原文链接:小样本学习与智能前沿
上一篇:A Survey on Few-Shot Learning | Introduction and Overview
本节中的FSL方法使用先验知识来增强数据(D_{train}),从而丰富了E中的监督信息。(图4)。
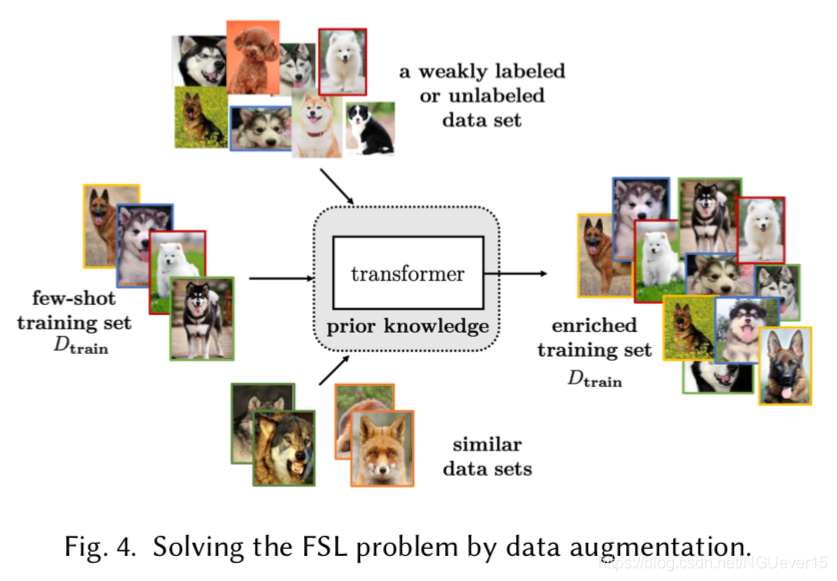
Data augmentation via hand-crafted rules is usually used as pre-processing in FSL methods.
They can introduce different kinds of invariance for the model to capture. For example, on images, one can use translation [12, 76, 114, 119], flipping [103, 119], shearing [119], scaling [76, 160], reflection [34, 72], cropping [103, 160] and rotation [114, 138].
许多增强规则根据数据集制定,使得他们很难应用到其他数据集中。
因此manual data augmentation 不能完全解决FSL问题。
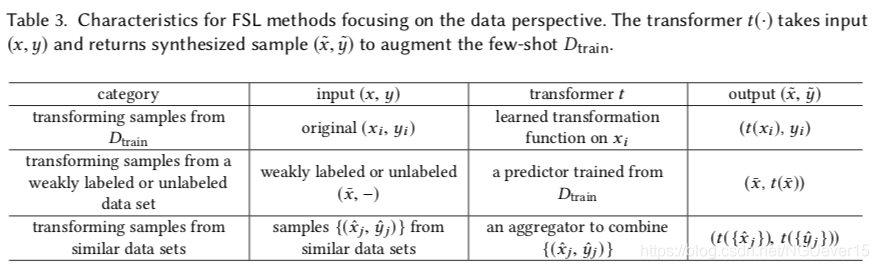
还有一些数据增强方式依赖于样本是如何转化和添加到训练集的。我们把他们分类在Table 3当中。
下面,我们将分别介绍这三种方法。
01 Transforming Samples from Dtrain
这个策略通过转换训练集中原有的((x_i,y_i))为多个样本来增加训练集(D_{train}). 转换过程作为先验知识包含在经验E中,以便生成其他样本。
早期的FSL论文[90]通过将每个样本与其他样本反复对齐,从相似的类中学习了一组几何变换。将学习到的变换应用于每个(xi,yi)以形成大数据集,然后可以通过标准机器学习方法学习大数据集。类似地,[116]从相似类中学习了一组自动编码器,每个自动编码器代表一个类内可变性。通过将习得的变化量添加到(x_i)来生成新样本。在[53]中,通过假设所有类别在样本之间共享一些可变换的可变性,可以学习单个变换函数,将从其他类别学习到的样本对之间的差异转移到(xi,yi)。在[74]中,不是枚举成对的变量,而是使用从大量场景图像中获悉的一组独立的属性强度回归将每个(x_i)转换为几个样本,并将原始(x_i)的标签分配给这些新样本。[82]在[74]的基础上进行了改进,将连续属性子空间用于向x添加属性变化。
02 Transforming Samples from a Weakly Labeled or Unlabeled Data Set
此策略通过从标记弱监督或未标记的大数据集中选择带有目标标记的样本来增强Dtrain。例如,在用监控摄像头拍摄的照片中,有人,汽车和道路,但没有一个被标记。另一个示例是一段较长的演示视频。它包含说话者的一系列手势,但是没有一个被明确注释。由于此类数据集包含样本的较大变化,因此将其增加到Dtrain有助于描绘更清晰的(p(x,y))。而且,由于不需要人工来标记,因此收集这样的数据集更加容易。但是,尽管收集成本很低,但主要问题是如何选择带有目标标签的样本以增加到Dtrain。在[102]中,为Dtrain中的每个目标标签学习了一个示例SVM,然后将其用于从弱标签数据集中预测样本的标签。然后将具有目标标签的样品添加到Dtrain中。在[32]中,标签传播直接用于标记未标记的数据集,而不是学习分类器。在[148]中,采用渐进策略选择信息丰富的未标记样品。然后为选定的样本分配伪标签,并用于更新CNN。
03 Transforming Samples from Similar Data Sets
该策略通过汇总和改编来自相似但较大数据集的输入输出对来增强(D_{train})。 聚集权重通常基于样本之间的某种相似性度量。 在[133]中,它从辅助文本语料库中提取聚合权重[133]。 由于这些样本可能不是来自目标FSL类,因此直接将汇总样本增加到(D_{train})可能会产生误导。 因此,生成对抗网络(GAN)[46]被设计为从许多样本的数据集中生成不可区分的合成x [42]。 它有两个生成器,一个生成器将少拍类的样本映射到大规模类,另一个生成器将大规模类的样本映射到少数类(以弥补GAN训练中样本的不足) 。
Discussion and Summary
使用哪种增强策略的选择取决于具体的应用。
有时,针对目标任务(或类)存在大量弱监督或未标记的样本,但是由于收集注释数据和/或计算成本高昂(这对应于引入的第三种情况)。 在这种情况下,可以通过转换标记较弱或未标记的数据集中的样本来执行增强。 当难以收集大规模的未标记数据集,但few-shot类具有某些相似类时,可以从这些相似类中转换样本。 如果只有一些学习的转换器而不是原始样本可用,则可以通过转换训练集中的原始样本来进行扩充。
总的来说,通过增强(D_{train})解决FSL问题非常简单明了, 即通过利用目标任务的先验信息来扩充数据。
另一方面,通过数据扩充来解决FSL问题的弱点在于,扩充策略通常是针对每个数据集量身定制的,并且不能轻易地用于其他数据集(尤其是来自其他数据集或域的数据。
最近,AutoAugment [27]提出了自动学习用于深度网络训练的增强策略的来解决这个问题。 除此之外,因为生成的图像可以很容易地被人在视觉上评估,现有的方法主要是针对图像设计的。而文本和音频涉及语法和结构较难生成。 [144]报告了最近对文本使用数据增强的尝试。
参考文献
[1] N.Abdo,H.Kretzschmar,L.Spinello,andC.Stachniss.2013.Learningmanipulationactionsfromafewdemonstrations. In International Conference on Robotics and Automation. 1268–1275.
[2] Z. Akata, F. Perronnin, Z. Harchaoui, and C. Schmid. 2013. Label-embedding for attribute-based classification. In Conference on Computer Vision and Pattern Recognition. 819–826.
[3] M. Al-Shedivat, T. Bansal, Y. Burda, I. Sutskever, I. Mordatch, and P. Abbeel. 2018. Continuous adaptation via meta- learning in nonstationary and competitive environments. In International Conference on Learning Representations.
[4] H. Altae-Tran, B. Ramsundar, A. S. Pappu, and V. Pande. 2017. Low data drug discovery with one-shot learning. ACS Central Science 3, 4 (2017), 283–293.
[5] M. Andrychowicz, M. Denil, S. Gomez, M. W. Hoffman, D. Pfau, T. Schaul, and N. de Freitas. 2016. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems. 3981–3989.
[6] S. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou. 2018. Neural voice cloning with a few samples. In Advances in Neural Information Processing Systems. 10019–10029.
[7] S. Azadi, M. Fisher, V. G. Kim, Z. Wang, E. Shechtman, and T. Darrell. 2018. Multi-content GAN for few-shot font style transfer. In Conference on Computer Vision and Pattern Recognition. 7564–7573.
[8] P. Bachman, A. Sordoni, and A. Trischler. 2017. Learning algorithms for active learning. In International Conference on Machine Learning. 301–310.
[9] Bengio Y. Bahdanau D, Cho K. 2015. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations.
[10] E.BartandS.Ullman.2005.Cross-generalization:Learningnovelclassesfromasingleexamplebyfeaturereplacement. In Conference on Computer Vision and Pattern Recognition, Vol. 1. 672–679.
[11] S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira. 2007. Analysis of representations for domain adaptation. In Advances in Neural Information Processing Systems. 137–144.
[12] S. Benaim and L. Wolf. 2018. One-shot unsupervised cross domain translation. In Advances in Neural Information Processing Systems. 2104–2114.
[13] L. Bertinetto, J. F. Henriques, P. Torr, and A. Vedaldi. 2019. Meta-learning with differentiable closed-form solvers. In International Conference on Learning Representations.
[14] L. Bertinetto, J. F. Henriques, J. Valmadre, P. Torr, and A. Vedaldi. 2016. Learning feed-forward one-shot learners. In Advances in Neural Information Processing Systems. 523–531.
[15] C. M. Bishop. 2006. Pattern Recognition and Machine Learning. Springer.
[16] J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. Wortman. 2008. Learning bounds for domain adaptation. In
Advances in Neural Information Processing Systems. 129–136.
[17] L. Bottou and O. Bousquet. 2008. The tradeoffs of large scale learning. In Advances in Neural Information Processing
Systems. 161–168.
[18] L. Bottou, F. E. Curtis, and J. Nocedal. 2018. Optimization methods for large-scale machine learning. SIAM Rev. 60, 2
(2018), 223–311.
[19] A. Brock, T. Lim, J.M. Ritchie, and N. Weston. 2018. SMASH: One-shot model architecture search through hypernet-
works. In International Conference on Learning Representations.
[20] J. Bromley, I. Guyon, Y. LeCun, E. Säckinger, and R. Shah. 1994. Signature verification using a "siamese" time delay
neural network. In Advances in Neural Information Processing Systems. 737–744.
[21] S. Caelles, K.-K. Maninis, J. Pont-Tuset, L. Leal-Taixé, D. Cremers, and L. Van Gool. 2017. One-shot video object
segmentation. In Conference on Computer Vision and Pattern Recognition. 221–230.
[22] Q. Cai, Y. Pan, T. Yao, C. Yan, and T. Mei. 2018. Memory matching networks for one-shot image recognition. In
Conference on Computer Vision and Pattern Recognition. 4080–4088.
[23] R. Caruana. 1997. Multitask learning. Machine learning 28, 1 (1997), 41–75.
[24] J. Choi, J. Krishnamurthy, A. Kembhavi, and A. Farhadi. 2018. Structured set matching networks for one-shot part
labeling. In Conference on Computer Vision and Pattern Recognition. 3627–3636.
[25] J.D.Co-Reyes,A.Gupta,S.Sanjeev,N.Altieri,J.DeNero,P.Abbeel,andS.Levine.2019.Meta-learninglanguage-guided
policy learning. In International Conference on Learning Representations.
[26] J. J. Craig. 2009. Introduction to Robotics: Mechanics and Control. Pearson Education India.
[27] E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le. 2019. AutoAugment: Learning augmentation policies
from data. In Conference on Computer Vision and Pattern Recognition. 113–123.
[28] T. Deleu and Y. Bengio. 2018. The effects of negative adaptation in Model-Agnostic Meta-Learning. arXiv preprint
arXiv:1812.02159 (2018).
[29] G. Denevi, C. Ciliberto, D. Stamos, and M. Pontil. 2018. Learning to learn around a common mean. In Advances in
Neural Information Processing Systems. 10190–10200.
[30] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database.
In Conference on Computer Vision and Pattern Recognition. 248–255.
[31] X. Dong, L. Zhu, D. Zhang, Y. Yang, and F. Wu. 2018. Fast parameter adaptation for few-shot image captioning and
visual question answering. In ACM International Conference on Multimedia. 54–62.
[32] M. Douze, A. Szlam, B. Hariharan, and H. Jégou. 2018. Low-shot learning with large-scale diffusion. In Conference on
Computer Vision and Pattern Recognition. 3349–3358.
[33] Y. Duan, M. Andrychowicz, B. Stadie, J. Ho, J. Schneider, I. Sutskever, P. Abbeel, and W. Zaremba. 2017. One-shot
imitation learning. In Advances in Neural Information Processing Systems. 1087–1098.
[34] H.EdwardsandA.Storkey.2017.Towardsaneuralstatistician.InInternationalConferenceonLearningRepresentations.
[35] L. Fei-Fei, R. Fergus, and P. Perona. 2006. One-shot learning of object categories. IEEE Transactions on Pattern Analysis
and Machine Intelligence 28, 4 (2006), 594–611.
[36] M. Fink. 2005. Object classification from a single example utilizing class relevance metrics. In Advances in Neural
Information Processing Systems. 449–456.
[37] C. Finn, P. Abbeel, and S. Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In
International Conference on Machine Learning. 1126–1135.
[38] C. Finn and S. Levine. 2018. Meta-learning and universality: Deep representations and gradient descent can approxi-
mate any learning algorithm. In International Conference on Learning Representations.
[39] C. Finn, K. Xu, and S. Levine. 2018. Probabilistic model-agnostic meta-learning. In Advances in Neural Information
Processing Systems. 9537–9548.
[40] L.Franceschi,P.Frasconi,S.Salzo,R.Grazzi,andM.Pontil.2018.Bilevelprogrammingforhyperparameteroptimization
and meta-learning. In International Conference on Machine Learning. 1563–1572.
[41] J. Friedman, T. Hastie, and R. Tibshirani. 2001. The Elements of Statistical Learning. Vol. 1. Springer series in statistics
New York.
[42] H. Gao, Z. Shou, A. Zareian, H. Zhang, and S. Chang. 2018. Low-shot learning via covariance-preserving adversarial
augmentation networks. In Advances in Neural Information Processing Systems. 983–993.
[43] P. Germain, F. Bach, A. Lacoste, and S. Lacoste-Julien. 2016. PAC-Bayesian theory meets Bayesian inference. In
Advances in Neural Information Processing Systems. 1884–1892.
[44] S. Gidaris and N. Komodakis. 2018. Dynamic few-shot visual learning without forgetting. In Conference on Computer
Vision and Pattern Recognition. 4367–4375.
[45] I. Goodfellow, Y. Bengio, and A. Courville. 2016. Deep Learning. MIT Press.
[46] I.Goodfellow,J.Pouget-Abadie,M.Mirza,B.Xu,D.Warde-Farley,S.Ozair,A.Courville,andY.Bengio.2014.Generative
adversarial nets. In Advances in Neural Information Processing Systems. 2672–2680.
[47] J. Gordon, J. Bronskill, M. Bauer, S. Nowozin, and R. Turner. 2019. Meta-learning probabilistic inference for prediction.
In International Conference on Learning Representations.
[48] E. Grant, C. Finn, S. Levine, T. Darrell, and T. Griffiths. 2018. Recasting gradient-based meta-learning as hierarchical
Bayes. In International Conference on Learning Representations.
[49] A. Graves, G. Wayne, and I. Danihelka. 2014. Neural Turing machines. arXiv preprint arXiv:1410.5401 (2014).
[50] L.-Y. Gui, Y.-X. Wang, D. Ramanan, and J. Moura. 2018. Few-shot human motion prediction via meta-learning. In
European Conference on Computer Vision. 432–450.
[51] M. Hamaya, T. Matsubara, T. Noda, T. Teramae, and J. Morimoto. 2016. Learning assistive strategies from a few
user-robot interactions: Model-based reinforcement learning approach. In International Conference on Robotics and
Automation. 3346–3351.
[52] X. Han, H. Zhu, P. Yu, Z. Wang, Y. Yao, Z. Liu, and M. Sun. 2018. FewRel: A large-scale supervised few-shot relation
classification dataset with state-of-the-art evaluation. In Conference on Empirical Methods in Natural Language
Processing. 4803–4809.
[53] B. Hariharan and R. Girshick. 2017. Low-shot visual recognition by shrinking and hallucinating features. In Interna-
tional Conference on Computer Vision.
[54] H. He and E. A. Garcia. 2008. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering
9 (2008), 1263–1284.
[55] K. He, X. Zhang, S. Ren, and J. Sun. 2016. Deep residual learning for image recognition. In Conference on Computer Vision and Pattern Recognition. 770–778.
[56] A. Herbelot and M. Baroni. 2017. High-risk learning: Acquiring new word vectors from tiny data. In Conference on Empirical Methods in Natural Language Processing. 304–309.
[57] L. B. Hewitt, M. I. Nye, A. Gane, T. Jaakkola, and J. B. Tenenbaum. 2018. The variational homoencoder: Learning to learn high capacity generative models from few examples. In Uncertainty in Artificial Intelligence. 988–997.
[58] S. Hochreiter and J. Schmidhuber. 1997. Long short-term memory. Neural Computation 9, 8 (1997), 1735–1780.
[59] S. Hochreiter, A. S. Younger, and P. R. Conwell. 2001. Learning to learn using gradient descent. In International
Conference on Artificial Neural Networks. 87–94.
[60] J. Hoffman, E. Tzeng, J. Donahue, Y. Jia, K. Saenko, and T. Darrell. 2013. One-shot adaptation of supervised deep
convolutional models. In International Conference on Learning Representations.
[61] Z. Hu, X. Li, C. Tu, Z. Liu, and M. Sun. 2018. Few-shot charge prediction with discriminative legal attributes. In
International Conference on Computational Linguistics. 487–498.
[62] S. J. Hwang and L. Sigal. 2014. A unified semantic embedding: Relating taxonomies and attributes. In Advances in
Neural Information Processing Systems. 271–279.
[63] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. 2014. Caffe:
Convolutional architecture for fast feature embedding. In ACM International Conference on Multimedia. 675–678.
[64] V. Joshi, M. Peters, and M. Hopkins. 2018. Extending a parser to distant domains using a few dozen partially annotated
examples. In Annual Meeting of the Association for Computational Linguistics. 1190–1199.
[65] Ł. Kaiser, O. Nachum, A. Roy, and S. Bengio. 2017. Learning to remember rare events. In International Conference on
Learning Representations.
[66] J. M. Kanter and K. Veeramachaneni. 2015. Deep feature synthesis: Towards automating data science endeavors. In
International Conference on Data Science and Advanced Analytics. 1–10.
[67] R. Keshari, M. Vatsa, R. Singh, and A. Noore. 2018. Learning structure and strength of CNN filters for small sample
size training. In Conference on Computer Vision and Pattern Recognition. 9349–9358.
[68] D. P. Kingma and M. Welling. 2014. Auto-encoding variational Bayes. In International Conference on Learning
Representations.
[69] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A.
Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks. National Academy of Sciences
114, 13 (2017), 3521–3526.
[70] G. Koch. 2015. Siamese neural networks for one-shot image recognition. Ph.D. Dissertation. University of Toronto.
[71] L. Kotthoff, C. Thornton, H. H. Hoos, F. Hutter, and K. Leyton-Brown. 2017. Auto-WEKA 2.0: Automatic model
selection and hyperparameter optimization in WEKA. Journal of Machine Learning Research 18, 1 (2017), 826–830.
[72] J.KozerawskiandM.Turk.2018.CLEAR:Cumulativelearningforone-shotone-classimagerecognition.InConference
on Computer Vision and Pattern Recognition. 3446–3455.
[73] A. Krizhevsky, I. Sutskever, and G. E. Hinton. 2012. ImageNet classification with deep convolutional neural networks.
In Advances in Neural Information Processing Systems. 1097–1105.
[74] R. Kwitt, S. Hegenbart, and M. Niethammer. 2016. One-shot learning of scene locations via feature trajectory transfer.
In Conference on Computer Vision and Pattern Recognition. 78–86.
[75] B. Lake, C.-Y. Lee, J. Glass, and J. Tenenbaum. 2014. One-shot learning of generative speech concepts. In Annual
Meeting of the Cognitive Science Society, Vol. 36.
[76] B.M.Lake,R.Salakhutdinov,andJ.B.Tenenbaum.2015.Human-levelconceptlearningthroughprobabilisticprogram
induction. Science 350, 6266 (2015), 1332–1338.
[77] B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Gershman. 2017. Building machines that learn and think like
people. Behavioral and Brain Sciences 40 (2017).
[78] C. H. Lampert, H. Nickisch, and S. Harmeling. 2009. Learning to detect unseen object classes by between-class
attribute transfer. In Conference on Computer Vision and Pattern Recognition. 951–958.
[79] Y. Lee and S. Choi. 2018. Gradient-based meta-learning with learned layerwise metric and subspace. In International
Conference on Machine Learning. 2933–2942.
[80] K. Li and J. Malik. 2017. Learning to optimize. In International Conference on Learning Representations.
[81] X.-L. Li, P. S. Yu, B. Liu, and S.-K. Ng. 2009. Positive unlabeled learning for data stream classification. In SIAM
International Conference on Data Mining. 259–270.
[82] B. Liu, X. Wang, M. Dixit, R. Kwitt, and N. Vasconcelos. 2018. Feature space transfer for data augmentation. In
Conference on Computer Vision and Pattern Recognition. 9090–9098.
[83] H. Liu, K. Simonyan, and Y. Yang. 2019. DARTS: Differentiable architecture search. In International Conference on
Learning Representations.
[84] Y. Liu, J. Lee, M. Park, S. Kim, E. Yang, S. Hwang, and Y Yang. 2019. Learning to propopagate labels: Transductive propagation network for few-shot learning. In International Conference on Learning Representations.
[85] Z.Luo,Y.Zou,J.Hoffman,andL.Fei-Fei.2017.Labelefficientlearningoftransferablerepresentationsacrosssdomains and tasks. In Advances in Neural Information Processing Systems. 165–177.
[86] S. Mahadevan and P. Tadepalli. 1994. Quantifying prior determination knowledge using the PAC learning model. Machine Learning 17, 1 (1994), 69–105.
[87] D. McNamara and M.-F. Balcan. 2017. Risk bounds for transferring representations with and without fine-tuning. In International Conference on Machine Learning. 2373–2381.
[88] T. Mensink, E. Gavves, and C. Snoek. 2014. Costa: Co-occurrence statistics for zero-shot classification. In Conference on Computer Vision and Pattern Recognition. 2441–2448.
[89] A. Miller, A. Fisch, J. Dodge, A.-H. Karimi, A. Bordes, and J. Weston. 2016. Key-value memory networks for directly reading documents. In Conference on Empirical Methods in Natural Language Processing. 1400–1409.
[90] E. G. Miller, N. E. Matsakis, and P. A. Viola. 2000. Learning from one example through shared densities on transforms. In Conference on Computer Vision and Pattern Recognition, Vol. 1. 464–471.
[91] N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel. 2018. A simple neural attentive meta-learner. In International Conference on Learning Representations.
[92] M. T. Mitchell. 1997. Machine Learning. McGraw-Hill.
[93] S.H.MohammadiandT.Kim.2018.Investigationofusingdisentangledandinterpretablerepresentationsforone-shot
cross-lingual voice conversion. In INTERSPEECH. 2833–2837.
[94] M. Mohri, A. Rostamizadeh, and A. Talwalkar. 2018. Foundations of machine learning. MIT Press.
[95] S. Motiian, Q. Jones, S. Iranmanesh, and G. Doretto. 2017. Few-shot adversarial domain adaptation. In Advances in
Neural Information Processing Systems. 6670–6680.
[96] T. Munkhdalai and H. Yu. 2017. Meta networks. In International Conference on Machine Learning. 2554–2563.
[97] T. Munkhdalai, X. Yuan, S. Mehri, and A. Trischler. 2018. Rapid adaptation with conditionally shifted neurons. In
International Conference on Machine Learning. 3661–3670.
[98] A. Nagabandi, C. Finn, and S. Levine. 2018. Deep online learning via meta-learning: Continual adaptation for
model-based RL. In International Conference on Learning Representations.
[99] H. Nguyen and L. Zakynthinou. 2018. Improved algorithms for collaborative PAC learning. In Advances in Neural
Information Processing Systems. 7631–7639.
[100] B. Oreshkin, P. R. López, and A. Lacoste. 2018. TADAM: Task dependent adaptive metric for improved few-shot
learning. In Advances in Neural Information Processing Systems. 719–729.
[101] S. J. Pan and Q. Yang. 2010. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering 10,
22 (2010), 1345–1359.
[102] T. Pfister, J. Charles, and A. Zisserman. 2014. Domain-adaptive discriminative one-shot learning of gestures. In
European Conference on Computer Vision. 814–829.
[103] H. Qi, M. Brown, and D. G. Lowe. 2018. Low-shot learning with imprinted weights. In Conference on Computer Vision
and Pattern Recognition. 5822–5830.
[104] T. Ramalho and M. Garnelo. 2019. Adaptive posterior learning: Few-shot learning with a surprise-based memory
module. In International Conference on Learning Representations.
[105] S. Ravi and A. Beatson. 2019. Amortized Bayesian meta-learning. In International Conference on Learning Representa-
tions.
[106] S. Ravi and H. Larochelle. 2017. Optimization as a model for few-shot learning. In International Conference on Learning
Representations.
[107] S. Reed, Y. Chen, T. Paine, A. van den Oord, S. M. A. Eslami, D. Rezende, O. Vinyals, and N. de Freitas. 2018. Few-shot
autoregressive density estimation: Towards learning to learn distributions. In International Conference on Learning
Representations.
[108] M. Ren, S. Ravi, E. Triantafillou, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel. 2018. Meta-
learning for semi-supervised few-shot classification. In International Conference on Learning Representations.
[109] D. Rezende, I. Danihelka, K. Gregor, and D. Wierstra. 2016. One-shot generalization in deep generative models. In
International Conference on Machine Learning. 1521–1529.
[110] A. Rios and R. Kavuluru. 2018. Few-shot and zero-shot multi-label learning for structured label spaces. In Conference
on Empirical Methods in Natural Language Processing. 3132.
[111] A. A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanu, S. Osindero, and R. Hadsell. 2019. Meta-learning with latent
embedding optimization. In International Conference on Learning Representations.
[112] R. Salakhutdinov and G. Hinton. 2009. Deep boltzmann machines. In International Conference on Artificial Intelligence
and Statistics. 448–455.



