马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
(1)观察集群配置情况
[root@master ~]# hdfs dfsadmin -report
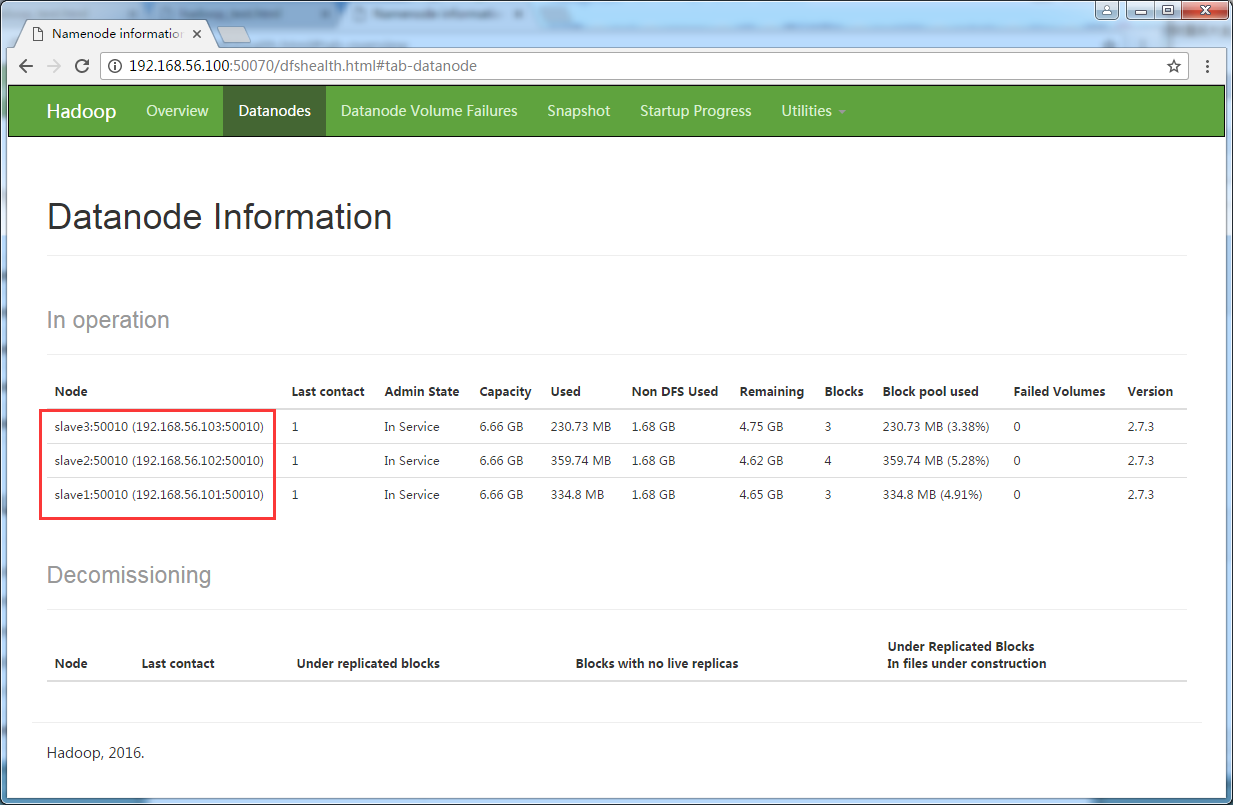
(2)web界面观察集群运行情况
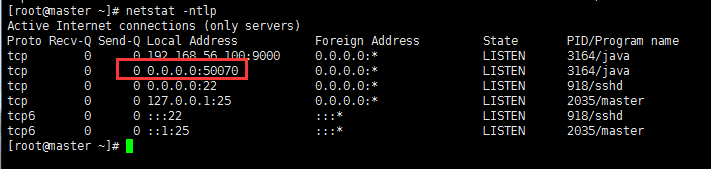
使用netstat命令查看端口监听
[root@master ~]# netstat -ntlp
浏览器地址栏输入:http://192.168.56.100:50070
(3)对集群进行集中管理
a) 修改master上的/usr/local/hadoop/etc/hadoop/slaves文件
[root@master hadoop]# vim slaves
#编辑内容如下
slave1
slave2
slave3
先使用hadoop-daemon.sh stop namenode(datanode)手工关闭集群。
b) 使用start-dfs.sh启动集群
[root@master hadoop]# start-dfs.sh
发现需要输入每个节点的密码,太过于繁琐,于是需要配置免密ssh远程登陆。
在master上用ssh连接一台slave,需要输入密码slave的密码,
[root@master hadoop]# ssh slave1
需要输入密码,输入密码登陆成功后,使用exit指令退回到master。
c) 免密ssh远程登陆
生成rsa算法的公钥和私钥
[root@master hadoop]# ssh-keygen -t rsa (然后四个回车)
进入到/root/.ssh文件夹,可看到生成了id_rsa和id_rsa.pub两个文件。
使用以下指令完成免密ssh登陆
[root@master hadoop]# ssh-copy-id slaveX
更多细节讲解,请查看马士兵hadoop第二课视频讲解:http://pan.baidu.com/s/1qYNNrxa
使用stop-dfs.sh停止集群,然后使用start-dfs.sh启动集群。
[root@master ~]# stop-dfs.sh
[root@master ~]# stop-dfs.sh
(3)修改windows上的hosts文件,通过名字来访问集群web界面
编辑C:WindowsSystem32driversetchosts
192.168.56.100 master
然后就可以使用http://master:50070代替http://192.168.56.100:50070
(4) 使用hdfs dfs 或者 hadoop fs命令对文件进行增删改查的操作
1 hadoop fs -ls / 2 hadoop fs -put file / 3 hadoop fs -mkdir /dirname 4 hadoop fs -text /filename 5 hadoop fs -rm /filename
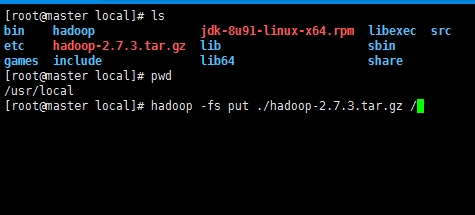
将hadoop的安装文件put到了hadoop上操作如下
[root@master local]# hadoop -fs put ./hadoop-2.7.3.tar.gz /
通过网页观察文件情况

(5)将dfs-site.xml的replication值设为2
replication参数是分块拷贝份数,hadoop默认为3。
也就是说,一块数据会至少在3台slave上都存在,假如slave节点超过3台了。
vim hdfs-site.xml

1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <configuration> 4 <property> 5 <name>dfs.replication</name> 6 <value>2</value> 7 </property> 8 <property> 9 <name>dfs.namenode.heartbeat.recheck-interval</name> 10 <value>10000</value> 11 </property> 12 </configuration>
为了方便测试,同时需要修改另外一个参数dfs.namenode.heartbeat.recheck-interval,这个值默认为300s,
将其修改成10000,单位是ms,这个参数是定期间隔时间后检查slave的运行情况并更新slave的状态。
可以通过 hadoop-2.7.3sharedochadoopindex.html里面查找这些默认的属性


修改完hdf-size.xml文件后,重启hadoop集群,
stop-dfs.sh #停止hadoop集群
start-dfs.sh #启动hadoop集权
hadoop -fs put ./jdk-8u91-linux-x64.rpm / #将jdk安装包上传到hadoop的根目录
到web页面上去观察jdk安装包文件分块在slave1,slave2,slave3的存储情况
hadoop-daemon.sh stop datanode #在slave3上停掉datanode
等一会时间后(大概10s,前面修改了扫描slave运行情况的间隔时间为10s),刷新web页面
观察到slave3节点挂掉
hadoop-daemon.sh start datanode #在slave3上启动datanode
然后再去观察jdk安装包文件分块在slave1,slave2,slave3的存储情况