编者的话|本文来自 Nginx 官方博客,是「Chris Richardson 微服务」系列的第五篇文章。第一篇文章介绍了微服务架构模式,并且讨论了使用微服务的优缺点;第二和第三篇描述了微服务架构模块间通讯的不同方面;第四篇研究了服务发现中的问题。本篇研究微服务架构带来的分布式数据管理问题。
作者介绍:Chris Richardson,是世界著名的软件大师,经典技术著作《POJOS IN ACTION》一书的作者,也是 cloudfoundry.com 最初的创始人,Chris Richardson 与 Martin Fowler、Sam Newman、Adrian Cockcroft 等并称为世界十大软件架构师。
Chris Richardson 微服务系列全 7 篇:
5. 微服务的事件驱动数据管理
Chris Richardson 所著所有文章已独家授权 DaoCloud 翻译并刊载。
本期内容:
一、微服务以及分布式数据管理中存在的问题
单体应用通常使用单个关系型数据库,由此带来的好处在于应用能够使用 ACID 事务,后者提供了重要的操作特性:
- 原子化:原子粒度的更改
- 一致性:数据库的状态始终保持一致
- 隔离:并发执行的事务显示为串行执行
- 持久:事务一旦提交就不会被撤销
如此,应用能够简单地开始事务、更改(插入、更新和删除)多行、以及提交事务。
使用关系型数据库的另一大好处是它支持 SQL。SQL 是一门丰富、可声明的和标准化的查询预约。用户能够轻松通过查询将多个表中的数据组合起来,然后 RDBMS 查询调度器决定执行查询的最优方法。用户不必关心底层细节,比如如何访问数据库。此外,由于所有的应用数据在一个数据库中,很容易查询。
然而,微服务架构中的数据访问变得复杂许多。每个微服务拥有的数据专门用于该微服务,仅通过其 API 访问。这种数据封装保证了微服务松散耦合,并且可以独立更新。但如果多个服务访问相同数据,架构更新会耗费时间、也需要所有服务的协调更新。
更糟糕的是,不同的微服务通常使用不同类型的数据库。现代应用存储和处理各种类型的数据,而关系型数据库并非总是好选择。对于一些使用场景,特定的 NoSQL 数据库能提供更方便的数据模型、更好的性能和可扩展性。譬如,服务使用 Elasticsearch 这样的文本搜索引擎来存储和查询文本;同样地,存储社交图谱数据的服务可能需要使用 Neo4j 这样的图谱数据库。因此,基于微服务的应用通常会混合使用 SQL 和 NoSQL 数据库,即多语言留存(polyglot persistence approach)。
分区的、多语言留存的架构对于数据存储有很多好处,包括服务的松耦合、更好的性能和可扩展性。然而,它也确实给分布式数据管理带来了挑战。
第一个挑战就是如何实现业务逻辑,保持多种服务的一致性。为了说明为何这是一个问题,我们以在线 B2B 商店为例。Customer Service(下文使用客户服务)维护与用户有关的信息,包括信用信息。Order Service(下文使用订单服务)管理订单,验证新订单没有超出用户的信用额度。在单体应用里,订单服务可以简单地使用 ACID 事务来核对提供的信用信息和创建订单。
相反,在微服务架构中,如下图所示,订单表和客户表为各自对应的服务私有。
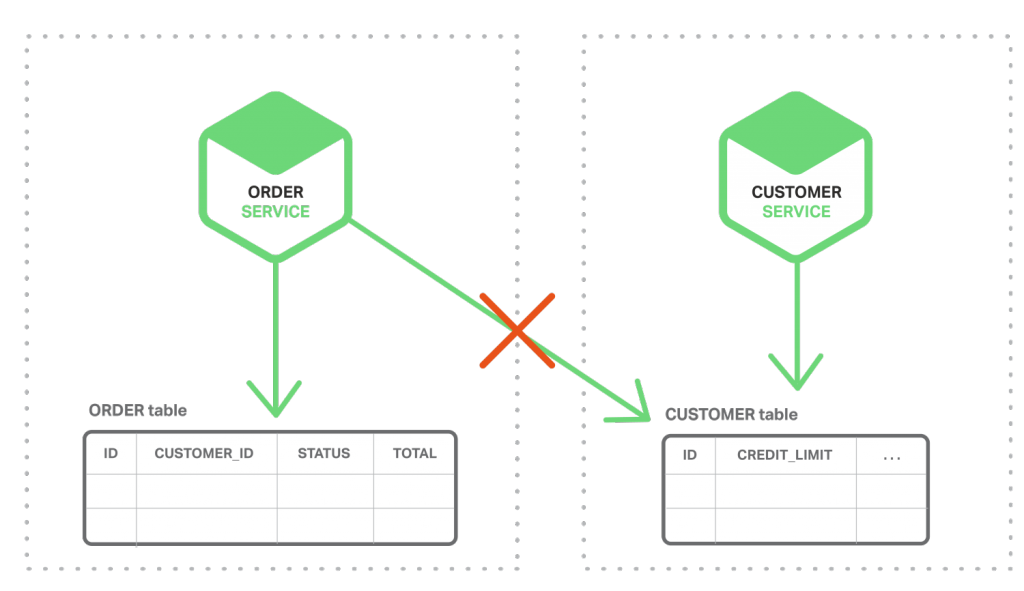
订单服务无法直接访问客户表,只能通过客户服务提供的 API。订购服务可能使用分布式事务,也被称为两步提交(2PC)。然而,2PC 通常不是现代应用的可行选项。CAP 定理需要用户在可用性和 ACID 风格的一致性中二选一,通常可用性是更好的选择。此外,许多现代技术,譬如大多数 NoSQL 数据库并不支持 2PC。维护整个服务和数据库中的数据一致性是至关重要的,因此我们需要另一种解决方案。
第二个挑战就是如何实现检索多个服务数据的查询。假设应用需要显示一位客户和他的最近的订单。如果订单服务为检索客户订单提供了 API,那么可以使用应用端获取该数据。应用通过客户服务检索该客户,通过订单服务检索该顾客的订单。但是假如订单服务只支持通过订单主键查询订单(可能使用仅支持键值检索的 NoSQL 数据库),这种情况下,就没有合适的方法来检索所需数据。
二、事件驱动的架构
对于许多应用,解决方案就是事件驱动的架构。在这一架构里,当有显著事件发生时,譬如更新业务实体,某个微服务会发布事件,其它微服务则订阅这些事件。当某一微服务接收到事件就可以更新自己的业务实体,实现更多事件被发布。
用户能够使用事件来实现跨多个服务的业务逻辑。事务由一系列步骤组成,每一步都有一个微服务更新业务实体,然后发布触发下一步的事件。下面的系列图展示了如何使用事件驱动的方法在创建订单时检查可用信用。微服务通过消息代理来交换事件。
1. 订单服务创建状态为 NEW 的订单,并发布“订单已创建”事件。

2. 客户服务获取“订单已创建”事件,为此订单保留信用,发布“信用保留”事件。

3. 订单服务获取“信用保留”事件,把订单状态修改为 OPEN。
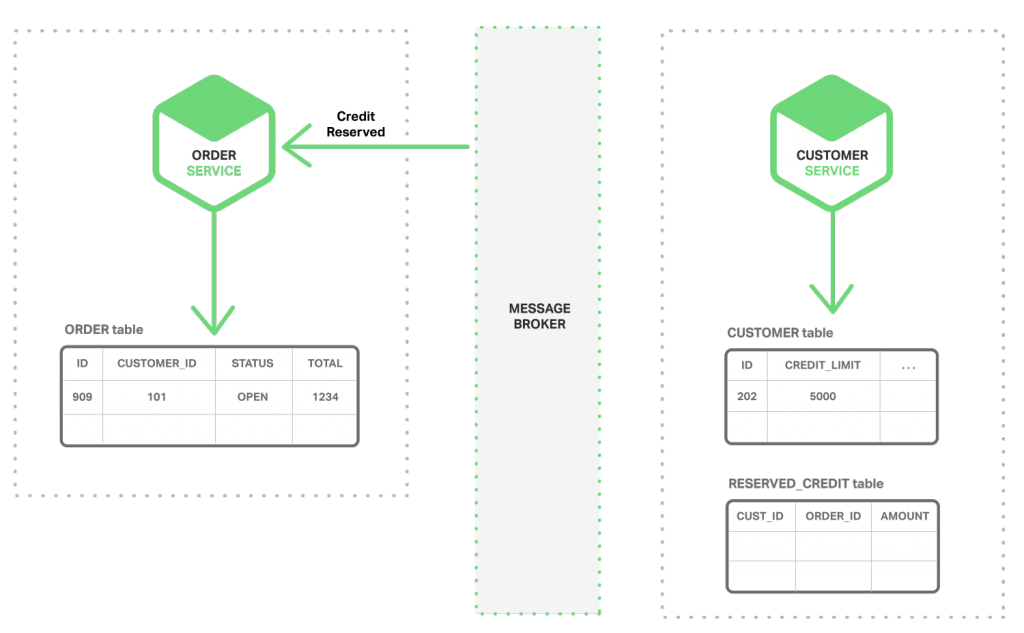
更为复杂的场景可能涉及更多的步骤,比如在核对客户信用的同时预留库存。
基于(a)每个服务自动更新数据库和发布事件,以及(b)消息代理确保事件传递至少一次,用户能够跨多个服务完成业务逻辑。注意它们并非 ACID 业务。这种模式提供弱确定性,比如最终一致性。这种事务模型也被称作 BASE 模型。
用户也可以使用事件来维护不同微服务拥有的预连接数据的物化视图。维护此视图的服务订阅相关事件,并更新视图。例如,维护客户订单视图的客户订单视图更新服务会订阅由客户服务和订单服务发布的事件。
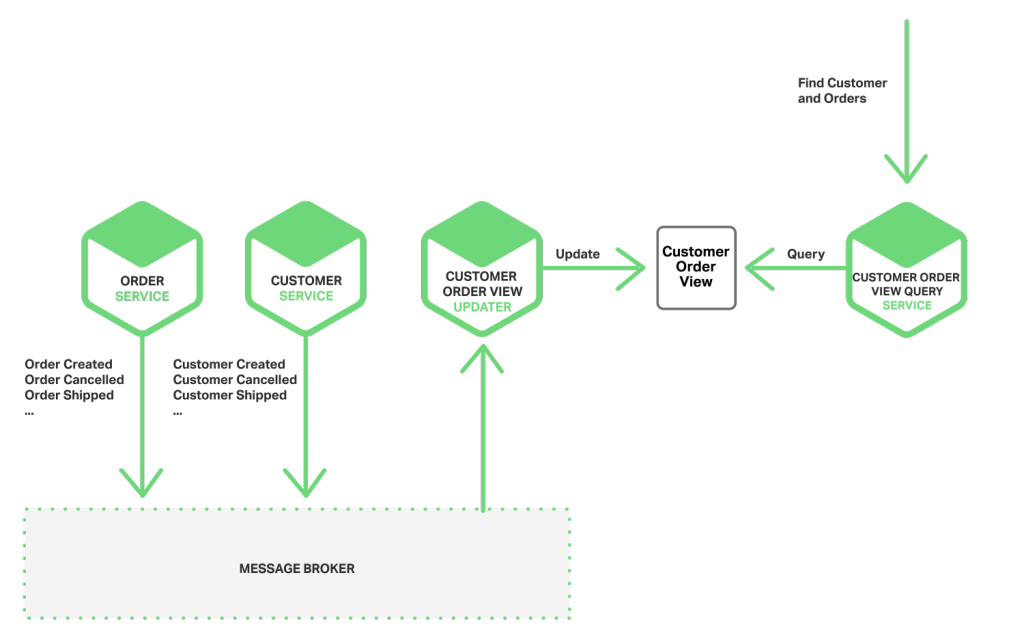
当客户订单查看更新服务收到客户或者订单事件,就会更新客户订单查看的数据存储。用户能够使用类似 MongoDB 的文档数据库查看用户订单,并为每位客户存储一个文档。用户订单预览查询服务通过客户订单预览数据存储,处理来自客户和最近订单的请求。
事件驱动的架构有优点也有缺点。它使得事务跨多个服务并提供最终一致性,也可以让应用维护物化视图。缺点之一在于,它的编程模型要比使用 ACID 事务的更加复杂。为了从应用级别的失效中恢复,还需要完成补偿性事务,例如,如果信用检查不成功则必须取消订单。此外,由于临时事务造成的改变显而易见,因而应用必须处理不一致的数据。此外,如果应用从物化视图中读取的数据没有更新时,也会遇到不一致的问题。此架构的另一缺点就是用户必须检测并忽略重复事件。
三、实现原子化
事件驱动的架构还存在以原子粒度更新数据库并发布事件的问题。例如,订单服务必须在订单表中插入一行,然后发布“订单已创建”事件。这两个操作需要原子化实现。如果服务在更新数据库之后、发布事件之前崩溃,系统变得不一致。确保原子化的标准做法是使用包含数据库和消息代理的分布式事务。然而,基于以上描述的 CAP 理论,这并非我们所想。
使用本地事务发布事件
实现原子化的方法是使用多步骤进程来发布事件,该进程只包含本地事务。诀窍就是在存储业务实体状态的数据库中,有一个事件表来充当消息队列。应用启动一个(本地)数据库事务,更新业务实体的状态,在事件表中插入一个事件,并提交该事务。独立的应用线程或进程查询事件表,将事件发不到消息代理,然后使用本地事务标注事件并发布。下图展示了这一设计。
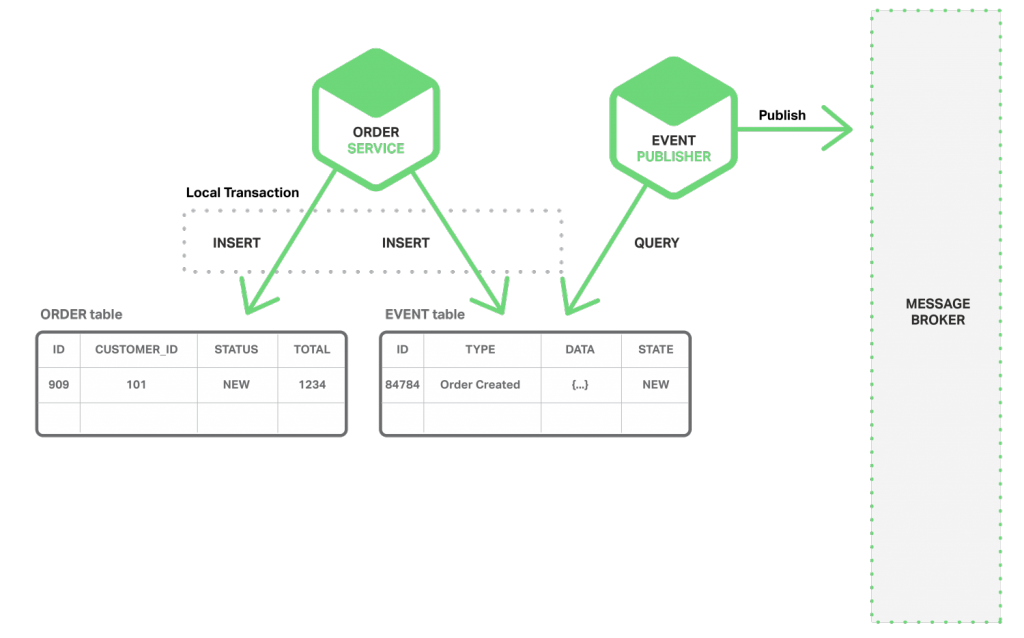
订单服务在订单表中插入一行,然后在事件表中插入“订单已创建”的事件。时间发布线程或进程在事件表中查询未发布的事件并发布,然后更新事件表,将该事件标记为已发布。
这种方法优缺点兼具。优点之一是保证每个更新都有对应的事件发布,并且无需依赖 2PC。此外,应用发布业务级别的事件,消除了推断事件的需要。这种方法也有缺点。由于开发者必须牢记发布事件,因此有很大可能出错。此外这一方法对于某些使用 NoSQL 数据库的应用是个挑战,因为 NoSQL 本身交易和查询能力有限。
通过此方法,应用使用本地事务来更新状态和发布事件,排除了对 2PC 的需要。接下来,我们了解使用应用更新状态实现原子化的方法。
挖掘数据库事务日志
无需 2PC 实现原子化的另一种方式是由线程或者进程通过挖掘数据库事务或提交日志来发布事件。应用更新数据库,数据库的事务日志记录这些变更。事务日志挖掘线程或进程读取这些日志,并把事件发布到消息代理。如下图所示:
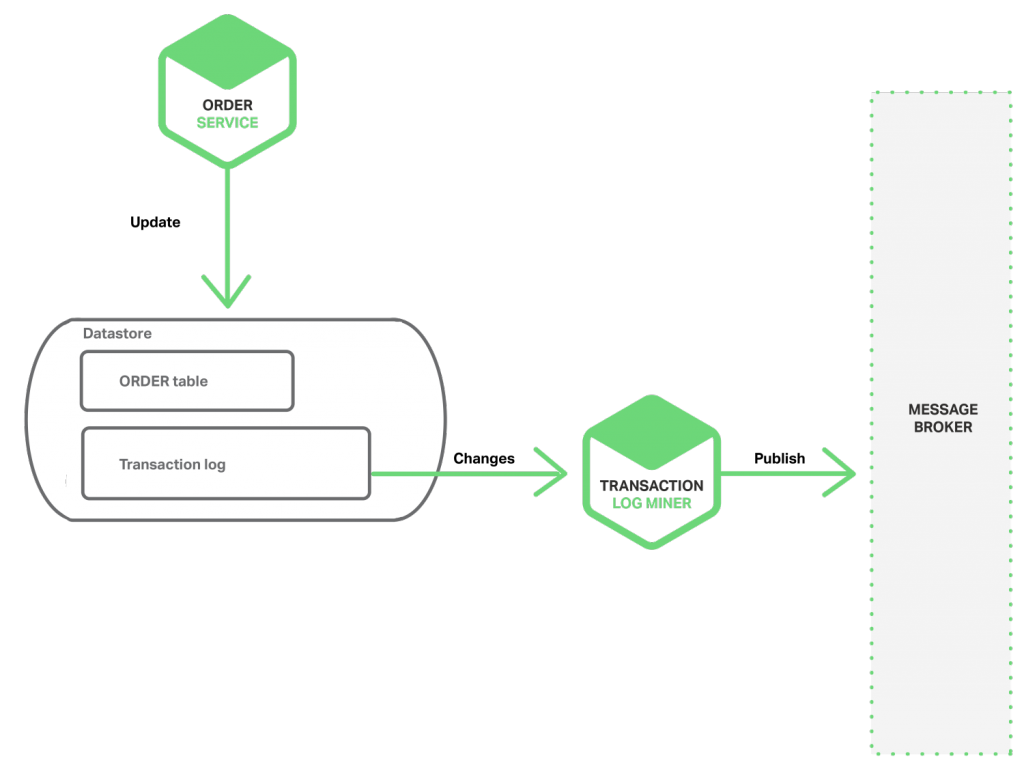
这一方法的范例是开源的 LinkedIn Databus 项目。Databus 挖掘 Oracle 事务日志并发布与之对应的事件。LinkedIn 使用 Databus 维持各种来源的数据存储与记录系统一致。
另一个范例则是 AWS DynamoDB 采用的流机制,AWS DynamoDB 是一个可管理的 NoSQL 数据库。每个 DynamoDB 流包括 DynamoDB 表在过去 24 小时之内的时序变化,包括创建、更新和删除操作。应用能够读取这些变更,将其作为事件发布。
事务日志挖掘具有多个优点。首先,它能保证无需使用 2PC 就能针对每个更新发布事件。其次,通过将日志发布于应用的业务逻辑分离,事务日志挖掘能够简化应用。事务日志挖掘也有缺点,主要缺点就是事务日志的格式与每个数据库对应,甚至随着数据库版本而变化。此外,很难从底层事务日志更新记录中逆向工程这些业务事件。
通过让应用更新数据库,事务日志挖掘消除了对 2PC 的需要。接下来我们会讨论另一种方法——消除更新,只依赖事件。
使用事件源
通过采用一种截然不同的、以事件为中心的方法来留存业务实体,事件源无需 2PC 实现了原子化。不同于存储实体的当前状态,应用存储状态改变的事件序列。应用通过重播事件来重构实体的当前状态。每当业务实体的状态改变,新事件就被附加到事件列表。鉴于保存事件是一个单一的操作,本质上也是原子化的。
要了解事件源如何运行,可以以订单实体为例。在传统的方法中,每个订单映射为订单表的一行,例如一个 ORDERLINEITEM 表。使用事件源的时候,订单服务以状态更改事件的方式存储订单,包括已创建、已批准、已发货、已取消等。每个事件都包含足够的数据去重建订单状态。
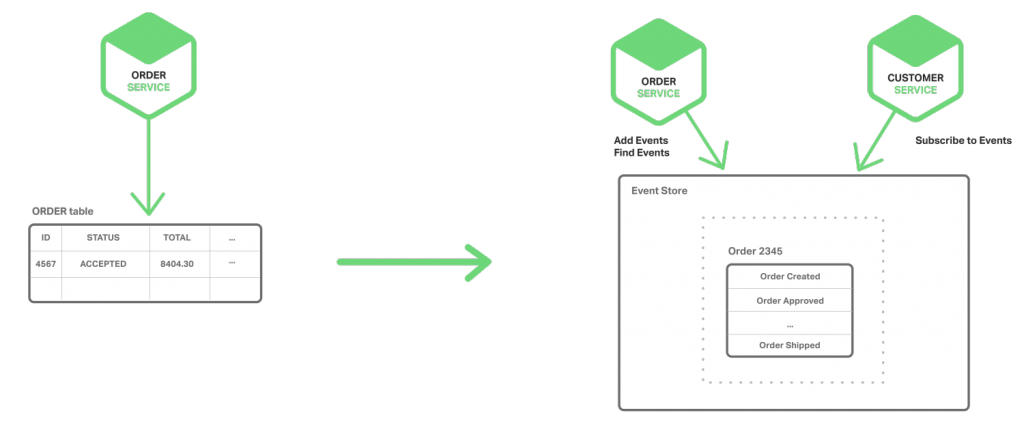
事件长期保存在事件数据库,使用 API 添加和检索实体的事件。事件存储类似上文提及的消息代理,通过 API 让服务订阅事件,将所有事件传达到所有感兴趣的订阅者。事件存储是事件驱动的微服务架构的支柱。
事件源有不少优点。它解决了实施事件驱动的微服务架构时的一个关键问题,能够只要状态改变就可靠地发布事件。另外,它也解决了微服务架构中的数据一致性问题。由于储存事件而不是域对象,它也避免了对象关系抗阻不匹配的问题(object‑relational impedance mismatch problem)。事件源提供了 100% 可靠的业务实体变化的审计日志,使得获取任何时间点的实体状态成为可能。事件源的另一大优势在于业务逻辑由松耦合的、事件交换的业务实体构成,便于从单体应用向微服务架构迁移。
事件源也有缺点。由于采用了不同或不熟悉的编程风格,会有学习曲线。事件存储只直接支持通过主键查询业务实体,用户还需要使用 Command Query Responsibility Segregation (CQRS) 来完成查询。因此,应用必须处理最终一致的数据。
四、总结
在微服务架构中,每个微服务都有其私有数据存储,不同的微服务可能使用不同的 SQL 和 NoSQL 数据库。这些数据库架构带来便利的同时,也给分布式数据管理带来挑战。第一个挑战就是如何实现业务事务,保持多个服务的一致性。第二个挑战就是如何从多个服务中检索数据,实现查询。
对于许多应用,解决方案就是使用事件驱动的架构。事件驱动的架构带来的挑战是如何原子化地更新状态和发布事件。有几个方法可以做到这一点,包括把数据库用作消息队列、事务日志挖掘和事件源。
下期:选择微服务部署策略 ,敬请期待!