一、重现基线模型
1.基线模型原理
所谓的代码搜索,就是根据输入的自然语言去寻找与之匹配的代码片段,并作为结果返回。但由于自然语言顺序与代码的语言格式之前存在差异,因此如果直接去寻找,那么必然会出现误匹配。一种方法是将代码片段与相应的自然语言描述嵌入到一个高维空间,那么代码片段和与之匹配的自然语言描述就会有相似的向量。在统一的向量表示下,语义上与自然语言查询相关的代码片段可以根据它们的向量进行检索。此外,还可以识别语义相关的词,并处理查询中不相关或者含噪的关键字。
本文提出了一种叫CODEnn的深度神经网络。它采用了Embedding的方法来将代码片段与自然语言描述映射为高维向量。所谓Embedding,就是一种学习诸如单词、句子和图像等实体的矢量表示的技术,其方式是相似的实体具有彼此接近的向量。
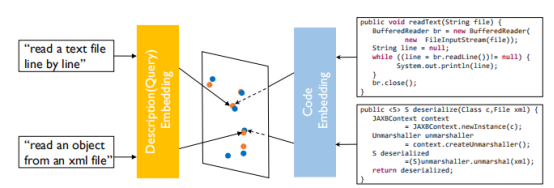
下图展示了一个示例,展示了代码和查询联合嵌入的思想。黄色点表示查询向量,蓝色点表示代码向量。由于代码和自然语言描述是两种不同的东西,因此要采用了两个不同的网络来分别进行embedding,使得语义对应的代码和描述在向量空间足够接近,而语义不同的代码和描述在向量空间则没有那么近。
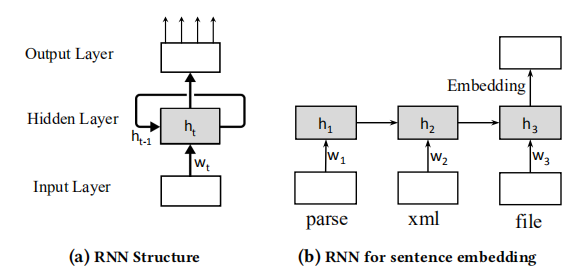
此外我们采用的主要架构是RNN,即递归神经网络。它是一类递归使用隐层的神经网络,它会创建网络的内部状态,以记录动态时态行为。 下图显示了RNN的基本结构。神经网络包括三个层,一个输入层,将每个输入映射到一个向量;一个递归隐藏层,递归计算和更新;一个输出层,读取每个输入后的隐藏状态,以及将隐藏状态用于特定任务。与传统的前馈神经网络不同,RNN可以嵌入顺序输入。
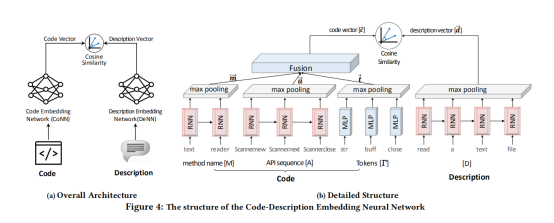
整个CODEnn的网络架构如下图所示。它由代码嵌入网络(CoNN),描述嵌入网络(DeNN)以及相似度模块三部分组成。
在代码嵌入网络中,又可分为方法名、API序列以及令牌(token)三部分组成。对于方法名和API序列,首先使得他们经过一个RNN序列,将文本序列转化为一个高维向量作为嵌入,然后进行最大池化操作来降低分辨率、节约计算资源。对于令牌部分,考虑到其无序性,直接用多层感知机进行处理,然后依然是经过一个最大池化层。之后采用全连接层将方法名、API序列以及令牌三部分融合起来,得到一个代码向量c。
在描述嵌入网络中,对输入的描述同样经过一个RNN网络将其映射到高维向量空间,然后经过一个最大池化层得到描述向量d。
对于相似性度量模块,我们采用余弦相似度来衡量代码向量c与描述向量d之间的相似性,最后得到一个标量值来衡量对于输入的自然语言描述找到的代码片段的相似度。
在训练过程中,对于每个代码向量c,都存在正描述d+以及负描述d-,我们据此构造损失函数L(θ),使得c与d+尽可能相似,而c与d-尽可能不同。损失函数L(θ)如下式所示:
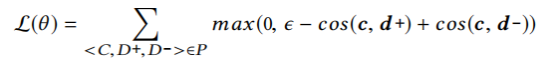
训练好的模型其搜索过程如下图所示。
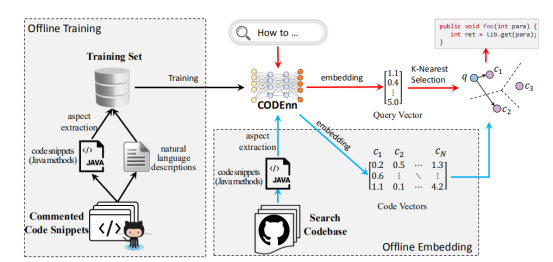
给定用户的自由文本查询,DeepCS通过经过训练的CODEnn模型返回相关的代码片段。它首先计算搜索中每个代码段的代码向量。然后,它选择并返回具有最高k个最近向量的代码片段到查询向量。具体地说,在搜索开始之前,DeepCS使用已经离线训练好的CODEnn模型,将代码库中的代码片段映射到高维空间中。在在线搜索期间,当开发人员输入自然语言查询时,DeepCS首先使用CODEnn的经过训练的Denn模块将查询嵌入到向量中。然后,使用余弦相似度估计查询向量和所有代码向量之间的余弦相似性。最后,将最类似于查询向量的的K个代码片段作为搜索结果返回。
2.模型的优缺点
优点:
(1)异构数据源和自然语言查询的统一表示是异构的。通过将源代码和自然语言查询联合嵌入到同一个向量表示中 它们的相似性可以更精确地测量。
(2)通过深度学习更好地理解查询,与传统技术不同,DeepCS通过深度学习学习查询和源代码表示。查询的特征,如语义相关词和语序,在我们的模型中都有有考虑。因此,它能够更好地识别查询和代码的语义。
(3)根据自然语言语义对代码片段进行聚类,我们的方法的一个优点是,它将语义上相似的代码片段嵌入到彼此相近的向量中。语义相似代码片段按语义分组。因此,除了精确匹配的片段之外,DeepCS还推荐语义相关的片段。
缺点:
(1)它有时排序部分相关的结果高于精确匹配的结果。这是因为Deeps通过考虑它们的语义向量来排名结果。
3.模型重现结果
我们将模型训练了200个epochs,在第200个epochs处在测试集上对模型进行了测试。测试结果如下,其中k表示选择的搜索结果数量:
| k | Success Rate | MAP | nDCG |
|---|---|---|---|
| 1 | 0.28 | 0.28 | 0.28 |
| 5 | 0.55 | 0.39 | 0.42 |
| 10 | 0.68 | 0.40 | 0.46 |
可以看出,随k增大,模型各项性能都更好。
可视化
我们通过PCA将code embedding与text embedding投影到二维;下图为所有测试数据的embedding的散点图。
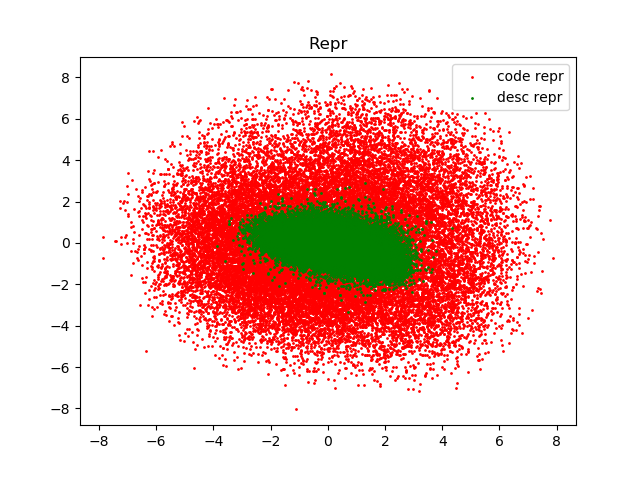
可以看出,code embedding与text embedding尺度上不完全一致,这进一步印证选择cosine similarity衡量相似度是正确的。
我们绘制了测试集中部分代码embedding与其描述的embedding在embedding space中的分布。下面两幅图表示code 0、desc 0、code 1、desc 1的embedding分别在原始embedding space中与L2归一化后的embedding space中分布,其中desc 0为"manage pende entry",code 0为其对应代码;desc 1为"Read mesh datum file",code 1为其对应代码。
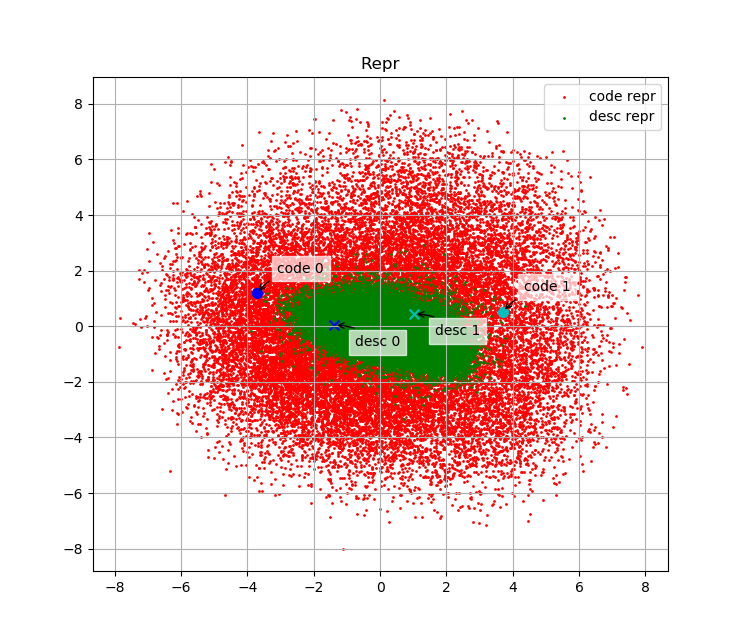
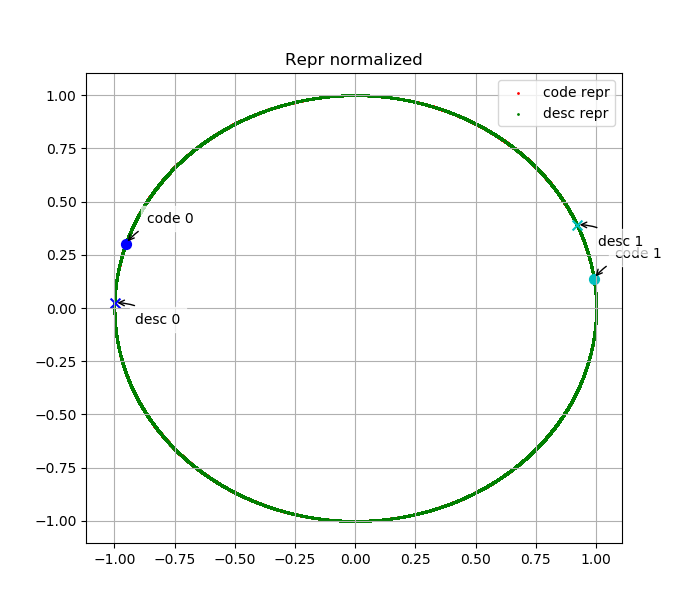
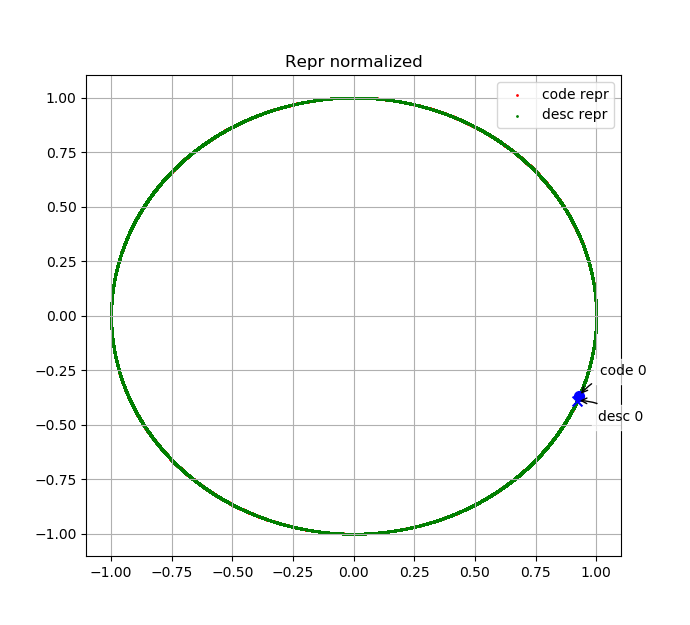
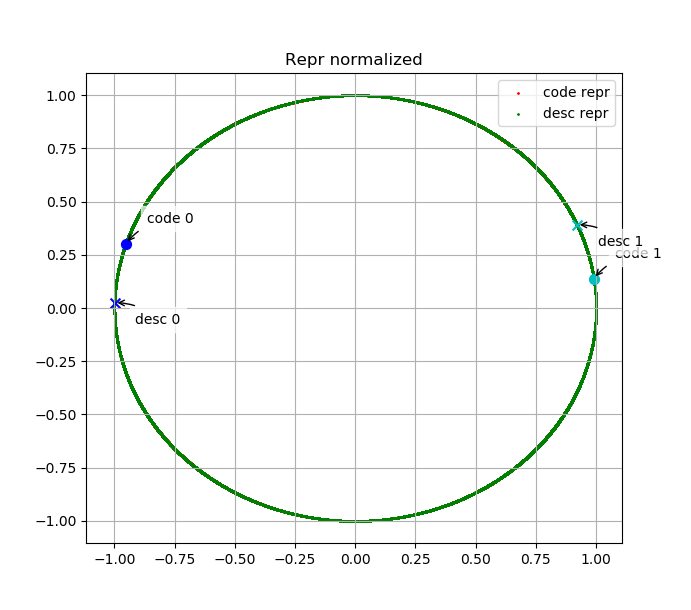
可以看出,语义上相关的代码与文本embedding相似度高、无关的代码或文本embedding相似度低,说明我们的模型是有效的。
二、提出改进方法
1.在我们的实验中,返回结果的相关性是手动分级的,可能会受到主观性偏倚的影响。为此,我们可以用更多的developers来对其进行分级以提高其准确率。
2.CODEnn方法是将代码与自然语言描述嵌入到高维空间向量,他们是离散的。而code2vec能为离散代码段在连续空间做Embedding,一次可以考虑加入code2vec方法来提高结果的精确度
3.质量高的(code, description)对较少,即可以用于将代码embedding与文本embedding投影到同一个embedding space的数据较少;然而无监督的数据,无论是代码还是文本有很多。我们可以用已有的大量无监督代码训练encoder,使之已经能表达一定的语义,然后在(code, description) 对数据上进行finetuning。
4.用语言模型对language encoder进行预训练是NLP中的常用方法。网络上,LSTM和更新的Transformer都有相应的预训练模型发布;也可以自己用与代码有关的文本语料(如爬取stackoverflow的文本)预训练一个模型。
三、评价合作伙伴
这次我们组的另两个同伴黄志鹏和吴雪晴都很厉害。我们合理的分工了任务,每个人都对论文阅读、模型理解、代码修改有所涉猎,同时都能提出对于模型修改的一些想法与建议,最后整个实验完成的也非常好。