对于同一个方法执行大量数据的程序时,我们可以采用ddt数据驱动的方式,来对数据规范化整理及输出
一、需要使用python的ddt库,ddt,data,unpack方法
1、仅使用ddt和data,代码如下
import unittest from ddt import ddt, data, unpack test_data = (1, 2, 3) @ddt # 需要在要引用的类前面加上 @ddt声明 class TestAdd(unittest.TestCase): @data(test_data) # 调用ddt的数据 def test_add(self, a): print(a)
test_add函数那里的形参a可以随便定义,程序会自动去接收 @data里面的值
输出结果
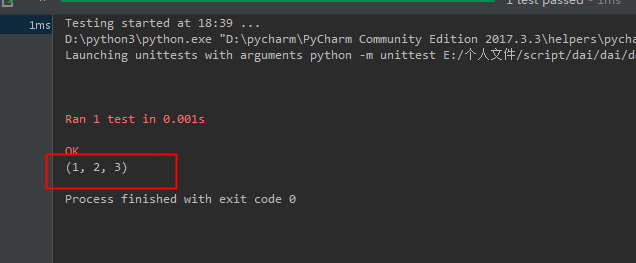
2、使用unpack功能,此方法主要是拆分数据类型,例如元组(1, 2, 3),在data下面加上 unpack后,会将数据类型拆分为
"""元组、列表数据驱动""" import unittest from ddt import ddt, data, unpack test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9)) @ddt # 需要在要引用的类前面加上 @ddt声明 class TestAdd(unittest.TestCase): @data(test_data) # 调用ddt的数据 @unpack def test_add(self, a, b, c): print('数据类型为', type(a), '数值为', a) print('数据类型为', type(b), '数值为', b) print('数据类型为', type(c), '数值为', c)
输出结果为:

会将test_data大元组拆分为,子类数值,并自动匹配数据类型。 例如将初始数据变为列表类型,并且列表里面的项未字符类型时
import unittest from ddt import ddt, data, unpack #test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9)) test_data = ['A', 'B', 'C'] @ddt # 需要在要引用的类前面加上 @ddt声明 class TestAdd(unittest.TestCase): @data(test_data) # 调用ddt的数据 @unpack def test_add(self, a, b, c): print('数据类型为', type(a), '数值为', a) print('数据类型为', type(b), '数值为', b) print('数据类型为', type(c), '数值为', c)
结果如下:
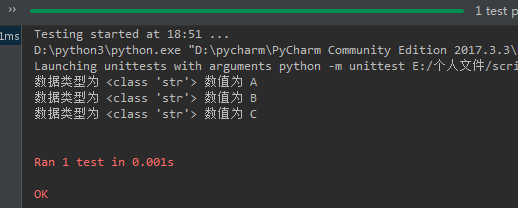
所以,ddt和data可以实现数据调用, unpack能对调用的大量数据进行拆分,得到最小等分的数据并进行使用。 注意,拆分之后的数据在函数test_data引用时,形参要和拆分的数量一致,即拆分了3个变量,那么我们调用函数的形参也必须是3个a,b,c (形参变量名不限,可以任意取,除了系统关键字)
二、对字典类型的数据进行数据驱动及拆分
字典是以键对值的形式来展示的,调用和拆分与列表、元组一样。 唯一不同点,在调用函数引用时,形参必须是字典的键值
"""字典类型数据驱动""" import unittest from ddt import ddt, data, unpack test_data = {"tall": 180, "sex": "boy"} @ddt class TestAdd(unittest.TestCase): @data(test_data) @unpack def test_add(self, tall, sex): # 此处的形参必须要是字典的键值 print("身高是", tall, "性别是", sex)
运行结果:
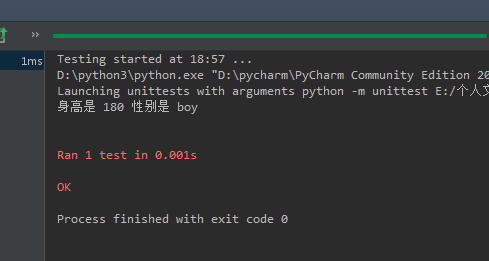
三、拓展使用
我们在进行数据驱动时,一般是从excel中读取数据,然后引用。 excel中的数据读取
from openpyxl import load_workbook class ReadExcel: # 读取Excel里面的内容 def __init__(self, file_name, sheet_name): self.file_name = file_name self.sheet_name = sheet_name def get_title(self): # 读取Excel里面的title数据 wb = load_workbook(self.file_name) # 打开Excel工作簿 sheet1 = wb[self.sheet_name] title = [] # 定义一个空列表,将读取的title字段进行存储 for i in range(1, sheet1.max_column+1): title.append(sheet1.cell(1, i).value) return title def do_excel(self): wb = load_workbook(self.file_name) sheet1 = wb[self.sheet_name] title = self.get_title() # 调用title内容 all_data = [] for j in range(2, sheet1.max_row+1): # 获取最大行数,加入循环 row_data={} for i in range(3, sheet1.max_column+1): # 获取最大列数,进行嵌套循环 row_data[title[i-1]] = sheet1.cell(j, i).value # 把拿到的数据进行字典的键对值匹配 all_data.append(row_data) return all_data
然后ddt进行引用即可