一、基于OpenVINO的“天空分割”回顾
semantic-segmentation-adas-0001模型中包含了天空对象。
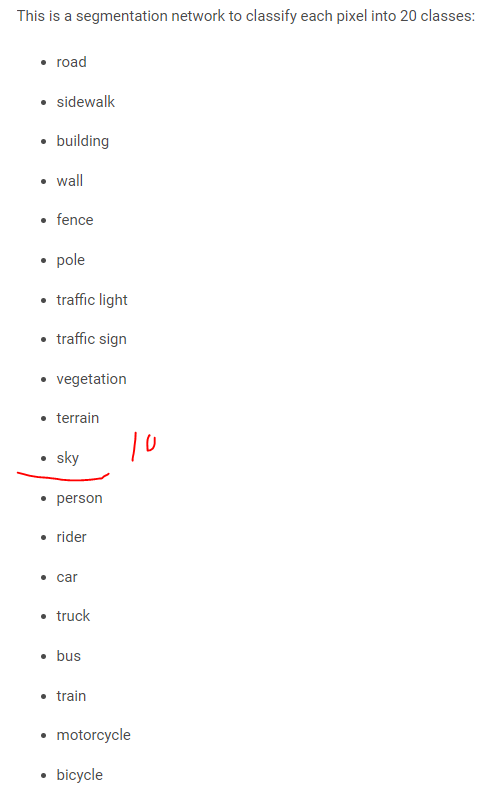
只接受batch=1的输入,而它的输出直接是标注label,需要缩放成为原图大小,可能还需要进行一些轮廓处理-但是已经基本上实现了“端到端”的效果。下面的图像中,蓝色区域是天空区域。这里需要注意的是,接口文件(***.py)是需要自己来写的。
The net outputs a blob with the shape [B, H=1024, W=2048]. It can be treated as a one-channel feature map, where each pixel is a label of one of the classes.
| 原图 | 效果 |
 |  |
 |  |
 |  |
 |  |
从上面几张图的效果可以看出,虽然有一定的误差,但是还是在可以接受范围内的。只要我们在融合上面稍微下一点功夫,这些是看不出来的。

经过进一步研究,能够得到以下的“天空替换”结果




二、OpenVINO Model Server服务化要点
最容易出错的地方是模型文件的准备,目前已经验证可行的方法是在本机按照制定的结构安排文件,而后调用“:ro"参数,将文件结构全部复制到docker中。比如:
我们下载了bin+xml,需要 按照以下模式存放
tree models/
models/
├── model1
│ ├── 1
│ │ ├── ir_model.bin
│ │ └── ir_model.xml
│ └── 2
│ ├── ir_model.bin
│ └── ir_model.xml
└── model2
└── 1
├── ir_model.bin
├── ir_model.xml
└── mapping_config.json这里的models以及下面的级联文件夹,都是在本机创建好的。
而后调用类似下面的命令行,启动Docker
docker run -d -v /models:/models:ro -p 9000:9000 openvino/model_server:latest --model_path /models/model1 --model_name face-detection --port 9000 --log_level DEBUG --shape auto参数解释
docker run 就是启动docker
-v 表示的是本机和docker中目录的对应方式,:ro表示是嵌套复制,也就是前面那么多级联的目录”原模原样“的复制过去。本机的文件放在哪里,我们当然知道;docker中的文件放在哪里,其实并不重要。重要的是将这里的文件地址告诉openvino,所以这里的目录地址和后面的--model_path是一致的
-p 本机和docker的端口镜像关系
openvino/model_server:latest 启动的docker镜像
--model_path 和前面的-v要保持一致
--model_name openvino调用的model的名称-d 它的意思就是后台运行,你可以去掉来看调试
其它几个不是太重要, 也不容易写错。启动成功以后,可以运行
docker ps来看是否运行成功。

当然你也可以在docker run中去掉 -d 而基于命令行的方法查看,这里还有其他一些相关命令。
sudo docker ps
sudo docker exec -it 775c7c9ee1e1 /bin/bash三、基于OpenVINO的道路分割服务化部署
3.1 新建model2,将最新的模型下载下来
wget https://download.01.org/opencv/2021/openvinotoolkit/2021.1/open_model_zoo/models_bin/2/semantic-segmentation-adas-0001/FP32/semantic-segmentation-adas-0001.bin
wget https://download.01.org/opencv/2021/openvinotoolkit/2021.1/open_model_zoo/models_bin/2/semantic-segmentation-adas-0001/FP32/semantic-segmentation-adas-0001.xml
[root@VM-0-13-centos 1]# cd /models
[root@VM-0-13-centos models]# tree
.
├── model1
│ └── 1
│ ├── face-detection-retail-0004.bin
│ └── face-detection-retail-0004.xml
└── model2
└── 1
├── semantic-segmentation-adas-0001.bin
└── semantic-segmentation-adas-0001.xml
4 directories, 4 files在image目录中,采用ftp或者wget的方式放置一张图片


这张图片由于曝光等问题,天空是比较难以分割出来的,我们看模型效果。
3.2修改几个参数,将服务跑起来,并确认服务正确运行:
[root@VM-0-13-centos models]# docker run -d -v /models:/models:ro -p 9000:9000 openvino/model_server:latest --model_path /models/model2 --model_name semantic-segmentation-adas --port 9000 --log_level DEBUG --shape auto
27907ca99807fb58184daee3439d821b554199ead70964e6e6bcf233c7ee20f0
[root@VM-0-13-centos models]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
27907ca99807 openvino/model_server:latest "/ovms/bin/ovms --mo…" 5 seconds ago Up 3 seconds 0.0.0.0:9000->9000/tcp flamboyant_mahavira以上两个步骤,都是和之前操作类似的,是比较简单的。
3.3接口文件的改写:
服务运行了,但是必须有能够调用这个服务的接口文件。这个方面的参考比较复杂。我经过一段时间的研究能够成功调用。这里将几个需要改写的地方和愿意进行梳理。我们最终形成的接口文件取名sky_detection.py。
3.3.1 图像尺寸
由于semantic-segmentation-adas模型在训练和推断的时候,是需要缩放到指定的大小的(具体的大小可以通过查文档获得)
Performance
Inputs
The blob with BGR image in format: [B, C=3, H=1024, W=2048], where:
B - batch size,
C - number of channels
H - image height
W - image width
……
Performance
Inputs
The blob with BGR image in format: [B, C=3, H=1024, W=2048], where:
B - batch size,
C - number of channels
H - image height
W - image width
……
Inputs
The blob with BGR image in format: [B, C=3, H=1024, W=2048], where:
B - batch size,
C - number of channels
H - image height
W - image width
……
故首先需要在参数设置中,设定正确的高度和宽度。比如客户端采用
python3 sky_detection.py --batch_size 1 --width 1024 --height 2048 --input_images_dir images --output_dir results
3.3.2 grpc传输限制
默认情况下,grpc只可以传输4M的文件,这对于我们以图像作为目的的推理来说,是不够的。因此,如果不做设置,会出现以下问题:
Request shape (1, 3, 1024, 2048)
(1, 3, 1024, 2048)
Traceback (most recent call last):
File "sky_detection.py", line 79, in <module>
result = stub.Predict(request, 10.0)
File "/usr/local/lib64/python3.6/site-packages/grpc/_channel.py", line 690, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/usr/local/lib64/python3.6/site-packages/grpc/_channel.py", line 592, in _end_unary_response_blocking
raise _Rendezvous(state, None, None, deadline)
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.RESOURCE_EXHAUSTED
details = "Received message larger than max (8388653 vs. 4194304)"
debug_error_string = "{"created":"@1602672141.715481155","description":"Received message larger than max (8388653 vs. 4194304)","file":"src/core/ext/filters/message_size/message_size_filter.cc","file_line":190,"grpc_status":8}"这个问题,经过管理员提醒
@jsxyhelu The limit on the server side is actually 1GB. Your logs indicate 4MB.
It seems to be client side restriction.
Could you try the following settings :
options = [('grpc.max_receive_message_length', 100 * 1024 * 1024),('grpc.max_send_message_length', 100 * 1024 * 1024)]
channel = grpc.insecure_channel(server_url, options = options)尝试进行解决。具体来说,就是采用这样的修改:
options = [('grpc.max_receive_message_length', 100 * 1024 * 1024),('grpc.max_send_message_length', 100 * 1024 * 1024)]
# this may make sense
channel = grpc.insecure_channel("{}:{}".format(args['grpc_address'],args['grpc_port']),options = options)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
3.3.3 获得模型名称
接口代码中,需要写明模型的Output name。这个名称比较隐晦,文档中是没有的(我没有找到)。解决的方法是需要通过“ get_serving_meta.py”(来自https://github.com/openvinotoolkit/model_server/)获得输出模型的具体名称,比如在模型已经启动(docker run)的情况下运行:
root@VM-0-13-centos tmp]# python3 get_serving_meta.py --grpc_port 9000 --model_name semantic-segmentation-adas --model_version 1
2020-10-17 07:03:10.395324: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-10-17 07:03:10.395363: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Getting model metadata for model: semantic-segmentation-adas
Inputs metadata:
Input name: data; shape: [1, 3, 1024, 2048]; dtype: DT_FLOAT
Outputs metadata:
Output name: 4455.1; shape: [1, 1, 1024, 2048]; dtype: DT_INT32那么输出就叫做4455.1,这个一个内部的名称。后面如果有需要,可以将这一步获取名称的操作变成内部获取,具体来说就是整编get_serving_meta.py的内容到接口文件,这里为了方便说明原理先不这样做。
3.3.4 接口文件经过大量改写
经过上面的准备,接口文件正确运行的先决条件已经具备。下面需要具体修正接口文件。主要是一些存储和配色功能。
#
# Copyright (c) 2019-2020 Intel Corporation
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# update 2020/10/17
import argparse
import cv2
import datetime
import grpc
import numpy as np
import os
from tensorflow import make_tensor_proto, make_ndarray
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
from client_utils import print_statistics
classes_color_map = [
(150, 150, 150),
(58, 55, 169),
(211, 51, 17),
(157, 80, 44),
(23, 95, 189),
(210, 133, 34),
(76, 226, 202),
(101, 138, 127),
(223, 91, 182),
(80, 128, 113),
(235, 155, 55),
(44, 151, 243),
(159, 80, 170),
(239, 208, 44),
(128, 50, 51),
(82, 141, 193),
(9, 107, 10),
(223, 90, 142),
(50, 248, 83),
(178, 101, 130),
(71, 30, 204)
]
def load_image(file_path):
img = cv2.imread(file_path) # BGR color format, shape HWC
img = cv2.resize(img, (args['width'], args['height']))
img = img.transpose(2,0,1).reshape(1,3,args['height'],args['width'])
# change shape to NCHW
return img
parser = argparse.ArgumentParser(description='Demo for sky detection requests via TFS gRPC API.'
'analyses input images and saves with with detected skys.'
'it relies on model semantic-segmentation...')
parser.add_argument('--input_images_dir', required=False, help='Directory with input images', default="images/people")
parser.add_argument('--output_dir', required=False, help='Directory for staring images with detection results', default="results")
parser.add_argument('--batch_size', required=False, help='How many images should be grouped in one batch', default=1, type=int)
parser.add_argument('--width', required=False, help='How the input image width should be resized in pixels', default=1200, type=int)
parser.add_argument('--height', required=False, help='How the input image width should be resized in pixels', default=800, type=int)
parser.add_argument('--grpc_address',required=False, default='localhost', help='Specify url to grpc service. default:localhost')
parser.add_argument('--grpc_port',required=False, default=9000, help='Specify port to grpc service. default: 9000')
args = vars(parser.parse_args())
options = [('grpc.max_receive_message_length', 100 * 1024 * 1024),('grpc.max_send_message_length', 100 * 1024 * 1024)]
# this may make sense
channel = grpc.insecure_channel("{}:{}".format(args['grpc_address'],args['grpc_port']),options = options)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
files = os.listdir(args['input_images_dir'])
batch_size = args['batch_size']
print(files)
imgs = np.zeros((0,3,args['height'],args['width']), np.dtype('<f'))
for i in files:
img = load_image(os.path.join(args['input_images_dir'], i))
imgs = np.append(imgs, img, axis=0) # contains all imported images
print('Start processing {} iterations with batch size {}'.format(len(files)//batch_size , batch_size))
iteration = 0
processing_times = np.zeros((0),int)
for x in range(0, imgs.shape[0] - batch_size + 1, batch_size):
iteration += 1
request = predict_pb2.PredictRequest()
request.model_spec.name = "semantic-segmentation-adas"
img = imgs[x:(x + batch_size)]
print("
Request shape", img.shape)
request.inputs["data"].CopyFrom(make_tensor_proto(img, shape=(img.shape)))
start_time = datetime.datetime.now()
result = stub.Predict(request, 10.0) # result includes a dictionary with all model outputs print(img.shape)
output = make_ndarray(result.outputs["4455.1"])
for y in range(0,img.shape[0]): # iterate over responses from all images in the batch
img_out = output[y,:,:,:]
print("image in batch item",y, ", output shape",img_out.shape)
img_out = img_out.transpose(1,2,0)
print("saving result to",os.path.join(args['output_dir'],str(iteration)+"_"+str(y)+'.jpg'))
out_h, out_w,_ = img_out.shape
print(out_h)
print(out_w)
for batch, data in enumerate(output):
classes_map = np.zeros(shape=(out_h, out_w, 3), dtype=np.int)
for i in range(out_h):
for j in range(out_w):
if len(data[:, i, j]) == 1:
pixel_class = int(data[:, i, j])
else:
pixel_class = np.argmax(data[:, i, j])
classes_map[i, j, :] = classes_color_map[min(pixel_class, 20)]
cv2.imwrite(os.path.join(args['output_dir'],str(iteration)+"_"+str(batch)+'.jpg'),classes_map)
我较facedetection.py进行了修改的地方都进行了标黄。而后运行
python3 sky_detection.py --batch_size 1 --width 2048 --height 1024 --input_images_dir images --output_dir results注意这里是 --width 2018 --height 1024 。运行成功的回显
[root@VM-0-13-centos tmp]# python3 sky_detection.py --batch_size 1 --width 2048 --height 1024 --input_images_dir images --output_dir results
2020-10-17 07:46:20.942953: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-10-17 07:46:20.943164: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
['sky9.jpg']
Start processing 1 iterations with batch size 1
Request shape (1, 3, 1024, 2048)
image in batch item 0 , output shape (1, 1024, 2048)
saving result to results/1_0.jpg
1024
2048结果我们来看result,虽然这种结果被拉变形了(1024X2048),但是很多细节还是被区分出来了(红圈标注),曝光的地方也确实比较难以识别,出现了明显错误(黄圈标注)

和原图对比。
|  |
这样一个结果,是目前不经过专门训练,使用通用模型能够获得的最好结果。这个比对结果能为最后的“天空替换”做良好支持。