- 为什么要理解Redi缓存问题
(1) 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问mysql等数据库。这样可以大大缓解数据库的压力
(2) 当缓存库出现时,必须要考虑如下问题
① 缓存穿透
② 缓存穿击
③ 缓存雪崩
④ 缓存污染(或者慢了)
⑤ 缓存和数据库一致性
- 缓存穿透
(1) 原因
① 缓存穿透是指缓存和数据库中都没有数据,而用户不断发起请求。由于缓存时不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要去存储层查询,失去了缓存的意义。在流量比较大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击应用,这就是漏洞;如果发起id=-1的数据或者id特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
(2) 解决方案
① 接口增增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
② 从缓存取不到的数据,在数据库中也没有取到,这个也可以将key-value对写成key-null,缓存有效时间可以短点。这样可以防止攻击用户反复用同一个id暴力攻击
③ 布隆过滤器。bloomfilter就类似于一个hash set,用于快速判断某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小
- 缓存击穿
(1) 问题来源
① 缓存击穿是指缓存中没有但是数据库中有数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存又没有读到数据,又同时去数据库取数据,引起数据库压力瞬间增大,造成过大压力
(2) 解决方案
① 设置热点数据永不过期
② 接口限流与熔断、降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时,进行熔断、失败快速返回机制
③ 加互斥锁
- 缓存雪崩
(1) 问题来源
① 缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同的数据都过期了,很多数据都查不到而查数据库了
(2) 解决方案
① 缓存数据的过期时间选择随机,防止同一时间大量数据过期现象发生
② 如果缓存数据库是分布式缓存,将热点数据均匀分布在不同的缓存数据库中
③ 设置热点数据永不过期
- 缓存污染(或满了)
(1) 缓存污染问题说的是缓存中一些只会被访问一次或者几次的数据,被访问完后,再也不会被访问到,但是这些数据依然存留在缓存中,消耗缓存空间
(2) 缓存污染会随着数据的持续增加而逐渐显露,随着服务的不断运行,缓存中会存在大量的永远不会被再次访问的数据。缓存空间是有限的,如果缓存空间满了,再往缓存里写数据时就会又额外开销,影响Redis性能。这部分额外开销主要是指写的时候判断淘汰策略,根据淘汰策略去选择要淘汰的数据,然后进行删除操作
- 最大缓存设置多大
(1) 系统的设计选择是一个权衡的过程;大容量缓存是能带来性能加速的收益,但是成本也会更高,而小容量缓存不一定就起不到加速访问的效果。一般来说建议把缓存容量设置为总数据量的15%-30%,兼顾访问性能和内存空间开销
(2) 对于Redis来说,一旦确定了最大缓存容量,比如4GB,就可以通过命令来设置
(3) CONFIG SET maxmemory 4gb
- 数据库和缓存一致性
(1) 问题来源
① 使用Redis做一个缓冲操作哦,让请求前访问到redis,而不是直接访问mysql等数据库
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存和数据库之间的数据一致性问题
不管是先写mysql数据库,再删除Redis缓存;还是先删除缓存再写库,都可能出现数据不一致情况
② 实例
1) 如果删除了缓存Redis,还没有来得及写库mysql,另外一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据
2) 如果先写了库,再删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致的情况
3) 因为读和写是并发的,没法保证顺序,就会出现缓存 和数据库的数据不一致问题
- 四种相关模式
(1) 分类
① Cache aside
② Read through
③ Write through
④ Write behind caching
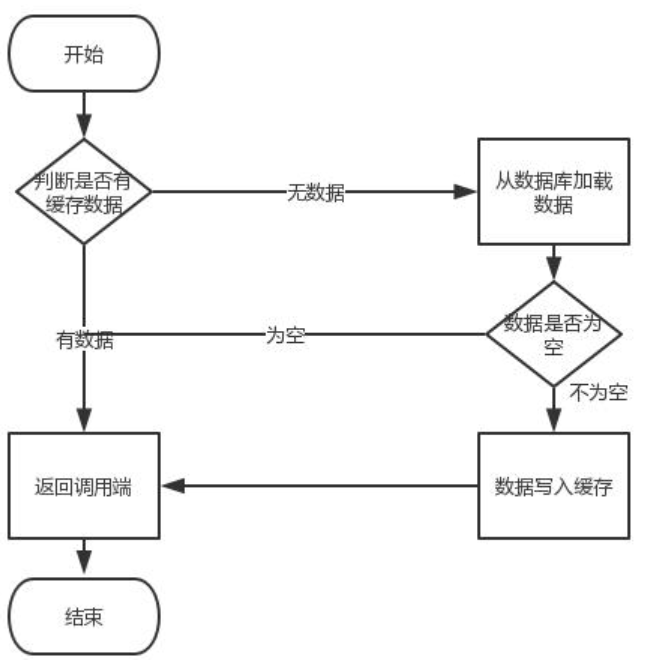
(2) 最常用的Cache aside,总结
① 读的时候 先读缓存,缓存没有的话,就读数据库,然后读出数据后放入缓存,同时返回响应
② 更新的时候 先更新数据库,然后在删除缓存
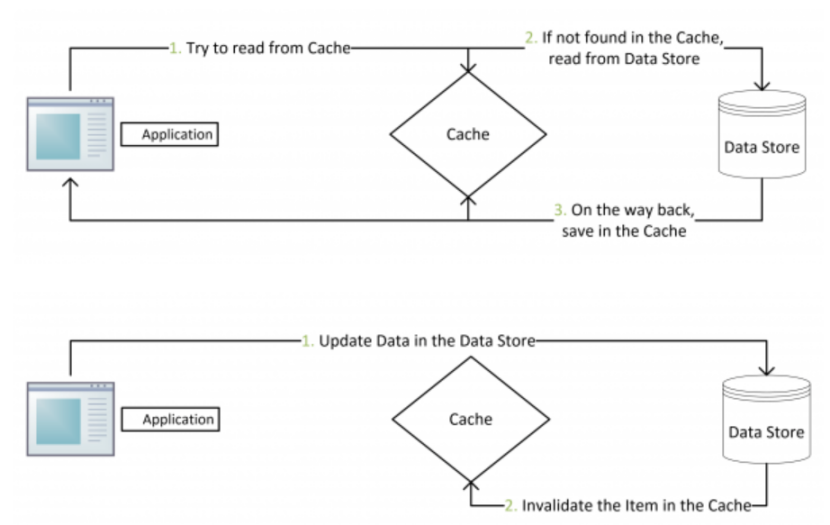
③ 其具体逻辑如下
1) 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后放入到缓存中
2) 命中:应用程序从cache中取数据,取到后返回
3) 更新:先把数据存储到数据库中,成功后再让缓存失效
4) 图示
④ 具体实现方案1:队列+重试机制
1) 图示
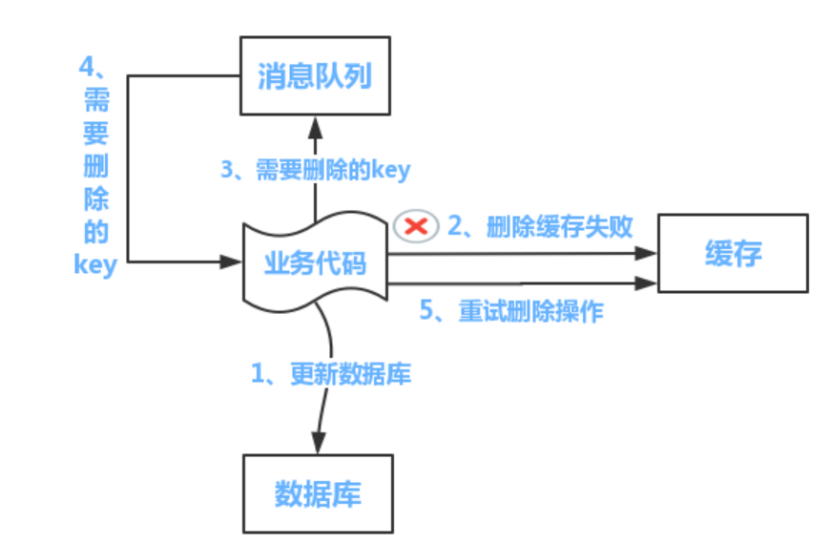
2) 流程如下:
- 更新数据库数据
- 缓存因为种种问题删除失败
- 将需要删除的key发送到消息队列
- 自己消费消息,获得需要删除的key
- 继续重试删除操作,直到成功
3) 缺点
- 对业务线代码造成大量入侵
⑤ 具体实现方案2:异步更新缓存(基于订阅binlog的同步机制)
1) 图示
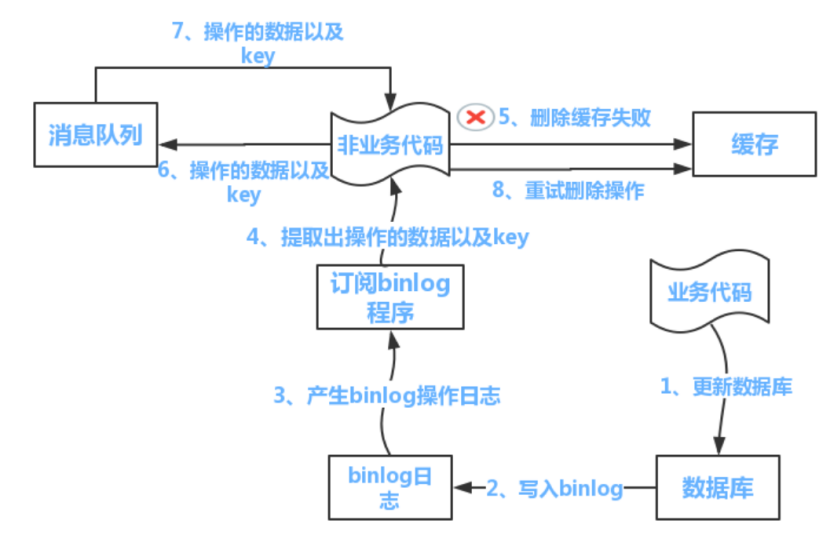
2) 技术整体思路
- Mysql binlog增量订阅消费+消息队列+增量数据更新到Redis
a) 读Redis:热点数据基本都在Redis中
b) 写Mysql:增删改都是操作Mysql
c) 更新Redis数据:Mysql的数据操作binlog,来更新到Redis
3) Redis更新
- 数据操作主要分为两大块
a) 一个是全量(将所有数据一次性写入到redis中)
b) 一个是增量(实时更新)
- 读取binlog后分析,利用消息队列,推送更新各台的redis缓存数据
a) 这样一旦Mysql中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的 记录,对Redis进行更新。其实这种机制,很类似于Mysql的主从备份机制,因为Mysql也通过binlog来实现数据的一致性
b) 消息推送工具:canal、kafka、rabbitMQ等