Middlebury数据集 http://vision.middlebury.edu/stereo/data/
KITTI数据集简介与使用 https://blog.csdn.net/solomon1558/article/details/70173223
http://www.dataguru.cn/article-12197-1.html
|
你一定不想错过这个全球较大的公开3D数据集。
本文作者为Matt Bell,是3D扫描解决方案提供商Matterport的联合创始人、首席战略官。在本文中,Bell亲述Matterport公开的这个数据集细节,我们随他去看看。
 一路走来,Matterport见证了3D数据集在深度学习多领域的巨大力量。我们在这个领域研究了很久,希望将一部分数据分享给研究者使用。令人兴奋的是,斯坦福、普林斯顿、TUM等的研究人员联手给大量的空间打了些标签,并将标记数据以Matterport 3D数据集的形式公开出来。
这是目前世界上较大的3D公开数据集,其中的标注意义重大。
像ImageNet、COCO这种比较大的2D数据集创建于2010年左右,是高精2D图像分类系统工具。我们希望Matterport这种3D+2D的数据集也能提升AI系统的认知力、理解力,带动3D研究的发展。
Matterport的行业影响力巨大,从增强现实、机器人技术、3D重构到更好地理解3D图像,我们一直在推进。
数据集“魔盒”
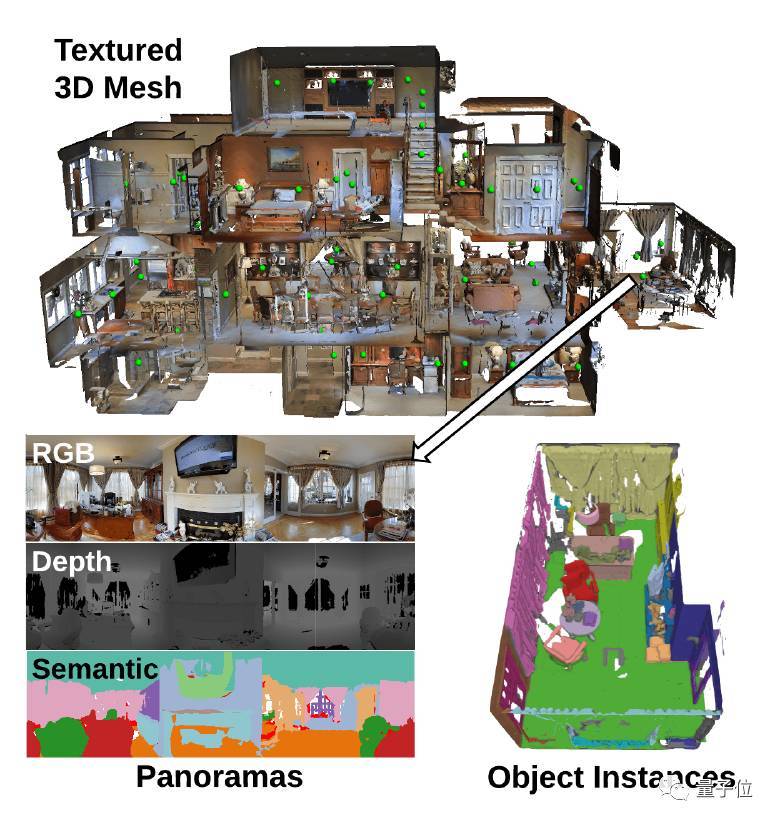
数据集中包含了10800张尺寸相同的全景图(RGB+深度图像),这些图片是从90个建筑场景的194400张RGB色彩模式的深度图像中挑选出来的,图像均用Matterport的Pro 3D相机拍摄。
 这些场景的3D模型已经用实例级对象分割做了标记,你可以在 https://matterport.com/gallery 网站中交互式探索不同的Matterport 3D重建模型。
 几种不同的解锁姿势
很高兴地告诉大家,这个数据集非常实用。下面我将介绍Matterport研究的几个方向。
目前,我们内部用这个数据集做过这样一个系统,将用户拍摄的照片分割成房间,并将其分类。这个系统的表现不错,甚至在没有门或隔断隔开情况下,也能分辨出不同的房间类型(例如厨房和餐厅)。
 此外,我们也在学习用深度学习方法填充3D传感器够不到的区域。这方便了用户快速拍摄广阔的开放空间,如仓库、购物中心、商业地产、工厂和新类型的房间等。
不妨看一个简单的示例。在这个例子中,我们的算法通过颜色和局部深度,预测深度值和深度传感器的表面方向(法向量)。由于这些区域太远,无法被深度传感器探测到。
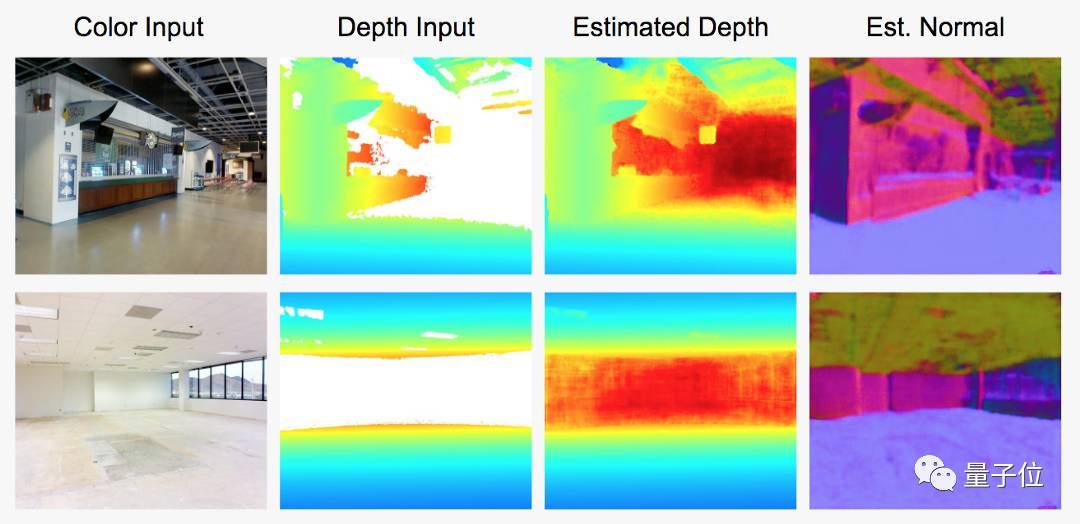 其实,我们还能用它在用户拍摄的空间中划分出不同对象。与现在3D模型不同的是,这些完全分割的模型能较精确识别空间中的物体。这样就解锁了很多使用姿势,包括自动生成含有空间内容和特征的详细列表,并自动看到不同家具在空间中的样子。
  我们还有个小目标,比如让任何空间能够被索引、搜索、排序和理解,让用户找到想要的东西。
比如,你想找到个地方度假,你希望那里有三间大卧室,配备着现代化厨房,客厅内还有内置的壁炉,在阳台上能看到下面的池塘风景,还有一扇落地窗?我们可以做到。
比如,你想盘点办公室里所有家具,想比较建筑工地上的管道和CAD模型是否一致?也so easy。
论文中还展示了一系列其他用例,包括通过深度学习的特性提高特征匹配、二维图像的表面法向量估计,以及识别基于体素模型的架构特征和对象等。
我们的下一步
正如上面所说,你可以使用这些数据、代码和论文,我们很愿意听听大家是如何使用它们的,也很期待与研究机构合作开展一些项目。
如果你对3D和更大的数据集感兴趣,也欢迎加入我们,感谢参与项目的所有人。
最后,附数据集地址:
https://niessner.github.io/Matterport/
Code地址:
https://github.com/niessner/Matterport
论文下载地址:
https://arxiv.org/pdf/1709.06158.pdf
欢迎来到3D世界!
欢迎加入本站公开兴趣群
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
|

计算机视觉·常用数据集·3D
Multiview
- 3D Photography Dataset
- Multiview stereo data sets: a set of images
- Multi-view Visual Geometry group’s data set
- Dinosaur, Model House, Corridor, Aerial views, Valbonne Church, Raglan Castle, Kapel sequence
- Oxford reconstruction data set (building reconstruction)
- Oxford colleges
- Multi-View Stereo dataset (Vision Middlebury)
- Temple, Dino
- Multi-View Stereo for Community Photo Collections
- Venus de Milo, Duomo in Pisa, Notre Dame de Paris
- IS-3D Data
- Dataset provided by Center for Machine Perception
- CVLab dataset
- CVLab dense multi-view stereo image database
- 3D Objects on Turntable
- Objects viewed from 144 calibrated viewpoints under 3 different lighting conditions
- Object Recognition in Probabilistic 3D Scenes
- Images from 19 sites collected from a helicopter flying around Providence, RI. USA. The imagery contains approximately a full circle around each site.
- Multiple cameras fall dataset
- 24 scenarios recorded with 8 IP video cameras. The first 22 first scenarios contain a fall and confounding events, the last 2 ones contain only confounding events.
- CMP Extreme View Dataset
- 15 wide baseline stereo image pairs with large viewpoint change, provided ground truth homographies.
- KTH Multiview Football Dataset II
- This dataset consists of 8000+ images of professional footballers during a match of the Allsvenskan league. It consists of two parts: one with ground truth pose in 2D and one with ground truth pose in both 2D and 3D.
- Disney Research light field datasets
- This dataset includes: camera calibration information, raw input images we have captured, radially undistorted, rectified, and cropped images, depth maps resulting from our reconstruction and propagation algorithm, depth maps computed at each available view by the reconstruction algorithm without the propagation applied.
- CMU Panoptic Studio Dataset
- Multiple people social interaction dataset captured by 500+ synchronized video cameras, with 3D full body skeletons and calibration data.
- 4D Light Field Dataset
- 24 synthetic scenes. Available data per scene: 9x9 input images (512x512x3) , ground truth (disparity and depth), camera parameters, disparity ranges, evaluation masks.
-
RGB-D数据集汇总 List of RGBD datasets https://blog.csdn.net/aaronmorgan/article/details/78335436
原文链接:http://www.cnblogs.com/alexanderkun/p/4593124.html
This is an incomplete list of datasets which were captured using a Kinect or similar devices. I initially began it to keep track of semantically labelled datasets, but I have now also included some camera tracking and object pose estimation datasets. I ultimately aim to keep track of all Kinect-style datasets available for researchers to use.
Where possible links have been added to project or personal pages. Where I have not been able to find these I have used a direct link to the data
Please send suggestions for additions and corrections to me at m.firman <at> cs.ucl.ac.uk.
This page is automatically generated from a YAML file, and was last updated on 26 November, 2014.
Turntable data
These datasets capture objects under fairly controlled conditions. Bigbird is the most advanced in terms of quality of image data and camera poses, while the RGB-D object dataset is the most extensive.
RGBD Object dataset
Introduced: ICRA 2011
Device: Kinect v1
Description: 300 instances of household objects, in 51 categories. 250,000 frames in total
Labelling: Category and instance labelling. Includes auto-generated masks, but no exact 6DOF pose information.
Download: Project page
Bigbird dataset
Introduced: ICRA 2014
Device: Kinect v1 and DSLR
Description: 100 household objects
Labelling: Instance labelling. Masks, ground truth poses, registered mesh.
Download: Project page
Segmentation and pose estimation under controlled conditions
These datasets include objects arranged in controlled conditions. Clutter may be present. CAD or meshed models of the objects may or may not be provided. Most provide 6DOF ground truth pose for each object.
Object segmentation dataset
Introduced: IROS 2012
Device: Kinect v1
Description: 111 RGBD images of stacked and occluding objects on table.
Labelling: Per-pixel segmentation into objects.
Download: Project page
Willow Garage Dataset
Introduced: 2011
Device: Kinect v1
Description: Around 160 frames of household objects on a board in controlled environment.
Labelling: 6DOF pose for each object, taken from board calibration. Per-pixel labelling.
Download: Project page
'3D Model-based Object Recognition and Segmentation in Cluttered Scenes'
Introduced: IJCV 2009
Device: Minolta Vivid 910 (only depth, no RGB!)
Description: 50 frames depicting five objects in various occluding poses. No background clutter in any image.
Labelling: Pose and per-point labelling information. 3D mesh models of each of the 5 objects.
Download: Project page
'A Global Hypotheses Verifcation Method for 3D Object Recognition'
Introduced: ECCV 2012
Device: Kinect v1
Description: 50 Kinect frames, library of 35 objects
Labelling: 6DOF GT of each object (unsure how this was gathered). No per-pixel labelling.
Download: Direct link
'Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes'
Introduced: ACCV 2012
Device: Kinect v1
Description: 18,000 Kinect images, library of 15 objects.
Labelling: 6DOF pose for each object in each image. No per-pixel labelling.
Download: Project page
RGBD Scenes dataset
Introduced: ICRA 2011
Device: Kinect v1
Description: Real indoor scenes, featuring objects from the RGBD object dataset 'arranged' on tables, countertops etc. Video sequences of 8 scenes.
Labelling: Per-frame bounding boxes for objects from RGBD object dataset. Other objects not labelled.
Download: Project page
RGBD Scenes dataset v2
Introduced: ICRA 2014
Device: Kinect v1
Description: A second set of real indoor scenes featuring objects from the RGBD object dataset. Video sequences of 14 scenes, together with stitched point clouds and camera pose estimations.
Labelling: Labelling of points in stitched cloud into one of 9 classes (objects and furniture), plus background.
Download: Project page
'Object Disappearance for Object Discovery'
Introduced: IROS 2012
Device: Kinect v1
Description: Three datasets: Small, with still images. Medium, video data from an office environement. Large, video over several rooms. Large dataset has 7 unique objects seen in 397 frames. Data is in ROS bag format.
Labelling: Ground truth object segmentations.
Download: Project page
'Object Discovery in 3D scenes via Shape Analysis'
Introduced: ICRA 2014
Device: Kinect v1
Description: KinFu meshes of 58 very cluttered indoor scenes.
Labelling: Ground truth binary labelling (object/not object) performed on segments proposed by the algorithm, with no labelling on the mesh.
Download: Project page
Cornell-RGBD-Dataset
Introduced: NIPS 2011
Device: Kinect v1
Description: Multiple RGBD frames from 52 indoor scenes. Stitched point clouds (using RGBDSLAM).
Labelling: Per-point object-level labelling on the stitched clouds.
Download: Project page
NYU Dataset v1
Introduced: ICCV 2011 Workshop on 3D Representation and Recognition
Device: Kinect v1
Description: Around 51,000 RGBD frames from indoor scenes such as bedrooms and living rooms. Note that the updated NYU v2 dataset is typically used instead of this earlier version.
Labelling: Dense multi-class labelling for 2283 frames.
Download: Project page
NYU Dataset v2
Introduced: ECCV 2012
Device: Kinect v1
Description: ~408,000 RGBD images from 464 indoor scenes, of a somewhat larger diversity than NYU v1. Per-frame accelerometer data.
Labelling: Dense labelling of objects at a class and instance level for 1449 frames. Instance labelling is not carried across scenes. This 1449 subset is the dataset typically used in experiments.
Download: Project page
'Object Detection and Classification from Large-Scale Cluttered Indoor Scans'
Introduced: Eurographics 2014
Device: Faro Lidar scanner
Description: Faro lidar scans of ~40 academic offices, with 2-3 scans per office. Each scan is 0.25GB-2GB. Scans include depth and RGB.
Labelling: No labelling present. The labelling shown in the exemplar image is their algorithm output.
Download: Project page
SUN3D
Introduced: ICCV 2013
Device: Kinect v1
Description: Videos of indoor scenes, registered into point clouds.
Labelling: Polygons of semantic class and instance labels on frames propagated through video.
Download: Project page
B3DO: Berkeley 3-D Object Dataset
Introduced: ICCV Workshop on Consumer Depth Cameras in Computer Vision 2011
Device: Kinect v1
Description: Aim is to crowdsource collection of Kinect data, to be included in future releases. Version 1 has 849 images, from 75 scenes.
Labelling: Bounding box labelling at a class level.
Download: Project page
TUM Benchmark Dataset
Introduced: IROS 2012
Device: Kinect v1
Description: Many different scenes and scenarios for tracking and mapping, including reconstruction, robot kidnap etc.
Labelling: 6DOF ground truth from motion capture system with 10 cameras.
Download: Project page
Microsoft 7-scenes dataset
Introduced: CVPR 2013
Device: Kinect v1
Description: Kinect video from 7 indoor scenes.
Labelling: 6DOF 'ground truth' from Kinect Fusion.
Download: Project page
IROS 2011 Paper Kinect Dataset
Introduced: IROS 2011
Device: Kinect v1
Description: Lab-based setup. The aim seems to be to track the motion of camera.
Labelling: 6DOF ground truth from Vicon system
Download: Project page
'When Can We Use KinectFusion for Ground Truth Acquisition?'
Introduced: Workshop on Color-Depth Camera Fusion in Robotics, IROS 2012
Device: Kinect v1
Description: A set of 57 scenes, captured from natural environments and from artificial shapes. Each scene has a 3D mesh, volumetric data and registered depth maps.
Labelling: Frame-to-frame transformations as computed from KinectFusion. The 'office' and 'statue' scenes have LiDAR ground truth.
Download: Project page
DAFT Dataset
Introduced: ICPR 2012
Device: Kinect v1
Description: A few short sequences of different planar scenes captured under various camera motions. Used to demonstrate repeatability of feature points under transformations.
Labelling: Camera motion type. 2D homographies between the planar scene in different images.
Download: Project page
ICL-NUIM Dataset
Introduced: ICRA 2014
Device: Kinect v1 (synthesised)
Description: Eight synthetic RGBD video sequences: four from a office scene and four from a living room scene. Simulated camera trajectories are taken from a Kintinuous output from a sensor being moved around a real-world room.
Labelling: Camera trajectories for each video. Geometry of the living room scene as an .obj file.
Download: Project page
'Automatic Registration of RGB-D Scans via Salient Directions'
Introduced: ICCV 2013
Device: RGBD Laser scanner
Description: Several laser scans taken from each of a European church, city and castle scenes.
Labelling: Results of the authors' registration algorithm.
Download: Project page
Stanford 3D Scene Dataset
Introduced: SIGGRAPH 2013
Device: Xtion Pro Live (Kinect v1 equivalent)
Description: RGBD videos of six indoor and outdoor scenes, together with a dense reconstruction of each scene.
Labelling: Estimated camera pose for each frame. No ground truth pose, so not ideal for quantitative evaluation.
Download: Project page
Princeton Tracking Benchmark
Introduced: ICCV 2013
Device: Kinect v1
Description: 100 RGBD videos of moving objects such as humans, balls and cars.
Labelling: Per-frame bounding box covering target object only.
Download: Project page
Cornell Activity Datasets: CAD-60 and CAD-120
Introduced: PAIR 2011/IJRR 2013
Device: Kinect v1
Description: Videos of humans performing activities
Labelling: Each video given at least one label, such as eating, opening or working on computer. Skeleton joint position and orientation labelled on each frame.
Download: Project page
RGB-D Person Re-identification Dataset
Introduced: First International Workshop on Re-Identification 2012
Device: Kinect v1
Description: Front and back poses of 79 people walking forward in different poses.
Labelling: In addition to the per-person label, the dataset provides foreground masks, skeletons, 3D meshes and an estimate of the floor.
Download: Project page
Sheffield KInect Gesture (SKIG) Dataset
Introduced: IJCAI 2013
Device: Kinect v1
Description: Total of 1080 Kinect videos of six people performing one of 10 hand gesture sequences, such as 'triangle' or 'comehere'. Sequences captured under a variety of illumination and background conditions.
Labelling: The gesture being performed in each sequence.
Download: Project page
RGB-D People Dataset
Introduced: IROS 2011
Device: Kinect v1
Description: 3000+ frames of people walking and standing in a university hallway, captured from three Kinects.
Labelling: Per-frame bounding box annotations of individual people, together with a `visibility' measure.
Download: Project page
50 Salads
Introduced: UbiComp 2013
Device: Kinect v1
Description: Over 4 hours of video of 25 people preparing 2 mixed salads each
Labelling: Accelerometer data from sensors attached to cooking utensils, and labelling of steps in the recipes.
Download: Project page
Microsoft Research Cambridge-12 Kinect gesture data set
Introduced: CHI 2012
Device: Kinect v1
Description: 594 sequences and 719,359 frames of 30 people performing 12 gestures.
Labelling: Gesture performed in each video sequence, plus motion tracking of human joint locations.
Download: Project page
UR Fall Detection Dataset
Introduced: Computer Vision Theory and Applications 2014
Device: Kinect v1
Description: Videos of people falling over. Consists of 60 sequences recorded with two Kinects.
Labelling: Accelerometer data from device attached to subject.
Download: Project page
RGBD-HuDaAct
Introduced: ICCV Workshops 2011
Device: Kinect v1
Description: 30 different humans each performing the same 12 activities, e.g. 'eat a meal'. Also include a random 'background' activity. All performed in a lab environment. Around 5,000,000 frames in total.
Labelling: Which activity being performed in each sequence.
Download: Project page
Human3.6M
Introduced: PAMI 2014
Device: SwissRanger time-of-flight (+ 2D cameras)
Description: 11 different humans performing 17 different activities. Data comes from four calibrated video cameras, 1 time-of-flight camera and (static) 3D laser scans of the actors.
Labelling: 2D and 3D human joint positions, obtained from a Vicon motion capture system.
Download: Project page
Biwi Kinect Head Pose Database
Introduced: IJCV 2013
Device: Kinect v1
Description: 15K images of 20 different people moving their heads in different directions.
Labelling: 3D position of the head and its rotation, acquired using 'faceshift' software.
Download: Project page
Eurecom Kinect Face Dataset
Introduced: ACCV Workshop on Computer Vision with Local Binary Pattern Variants 2012
Device: Kinect v1
Description: Images of faces captured under laboritory conditions, with different levels of occlusion and illumination, and with different facial expressions.
Labelling: In addition to occlusion and expression type, each image is manually labelled with the position of six facial landmarks.
Download: Project page
3D Mask Attack Dataset
Introduced: Biometrics: Theory, Applications and Systems 2013
Device: Kinect v1
Description: 76500 frames of 17 different people, facing the camera against a plain background. Two sets of the data are captured on the real subjects two weeks apart, while the final set consists of a single person wearing a fake face mask of the 17 different people.
Labelling: Which user is in each frame. Which images are real and which are spoofed. Manually labelled eye positions.
Download: Project page
Biwi 3D Audiovisual Corpus of Affective Communication - B3D(AC)^2
Introduced: IEEE Transactions on Multimedia 2010
Device: Custom active stereo setup
Description: Simultaneous audio and visual recordings of 1109 sentences spoken by 14 different people. Each sentence spoken neutrally and with an emotion. Depth images converted to 3D mesh.
Labelling: Perceived emotions for each recording. Audio labelled with phonemes.
Download: Project page
ETH Face Pose Range Image Data Set
Introduced: CVPR 2008
Device: Custom active stereo setup
Description: 10,545 images of 20 different people turning their head.
Labelling: Nose potition and coordinate frame at the nose.
Download: Project page