一.服务器环境
本人用的是阿里云的ECS的入门机器,配置1核2G,1M带宽,搭了个Hadoop单机环境,供参考
Linux发行版本:Centos7
JDK:阿里云镜像市场中选择JDK8
二.安装步骤
1.从镜像下载Hadoop安装包
这里选择从国内镜像下载,我这里选择是hadoop-2.7.7版本
镜像地址:http://mirror.bit.edu.cn/apache/hadoop/common/
2.解压缩hadoop安装包
tar -zxvf /opt/hadoop-2.7.7.tar.gz
这里的路径/opt/hadoop-2.7.7.tar,gz,可以自己定义
3.确认JAVA_HOME的环境变量已经配置好
默认情况下,从阿里云镜像市场中的镜像应该是已经配好的
可以通过以下命令确认
echo {JAVA_HOME} ,这个命令会输出JAVA的环境地址
4.运行hadoop自带的wordcount程序
-首先 我们要定义一个输入文件
如,vim /opt/hadoop-2.7.7/test.txt
-在test.txt文件中输入初始的需要计算的数据数据
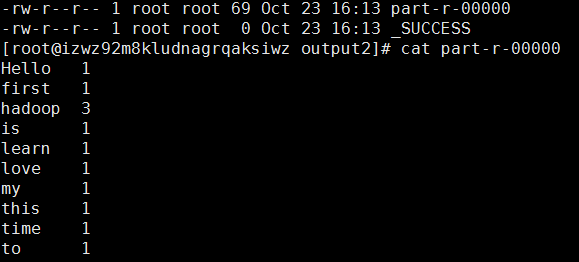
this is my first time to learn hadoop
love hadoop
Hello hadoop
-然后运行hadoop自带的demo示例,
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /opt/hadoop-2.7.7/input/test.txt output2
bin/hadoop:这是hadoop的执行入口
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar :这是hadoop地带的示例demo
/opt/hadoop-2.7.7/input/test.txt 这是输入文件的位置
output2:这是输出的文件夹
运行结束后,在output2文件夹下面可以查看输出的结果