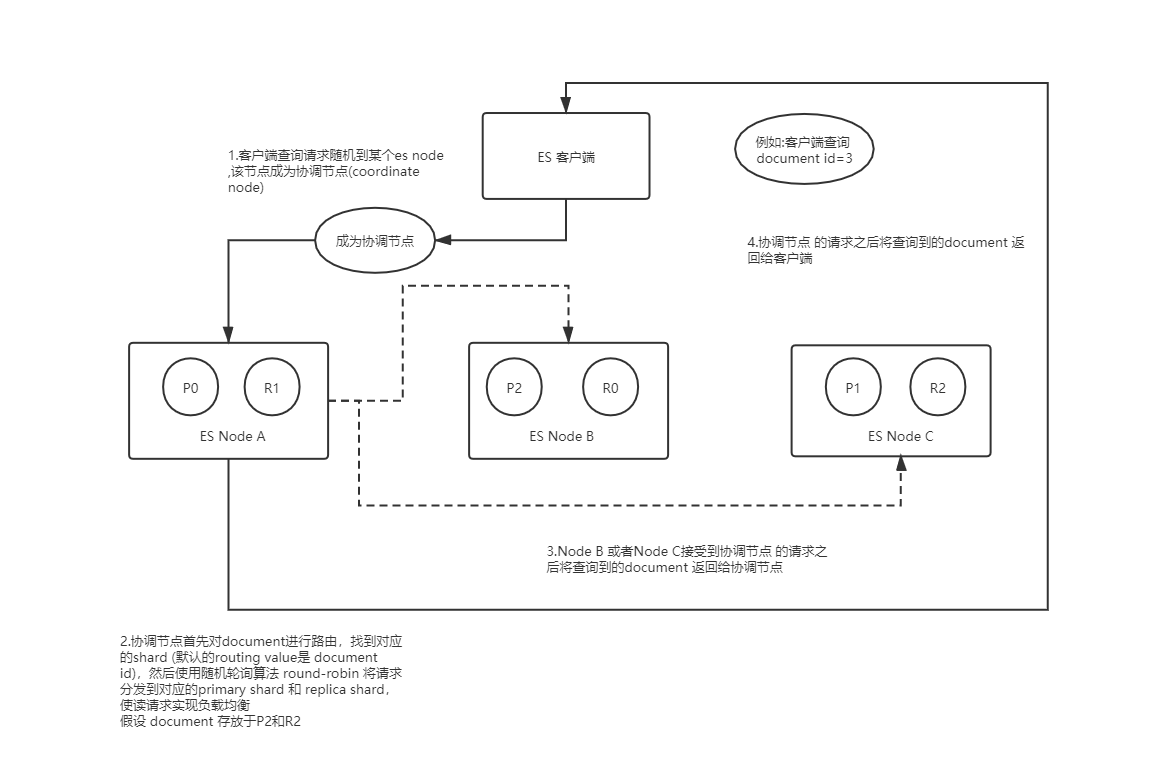
ES读数据的过程:
1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node);
2.corrdinating node 对 doc id 对哈希,找出该文档对应所在的shards,将请求转发到对应的node,
此时会使用round-robin 随机轮询算法,在primary shard 和 replica shard 之中选择一个 ,实现读请求的负载均衡;
3.接受请求的node 返回给document 给coordinate node;
4.coordinate node 返回document 给客户端;
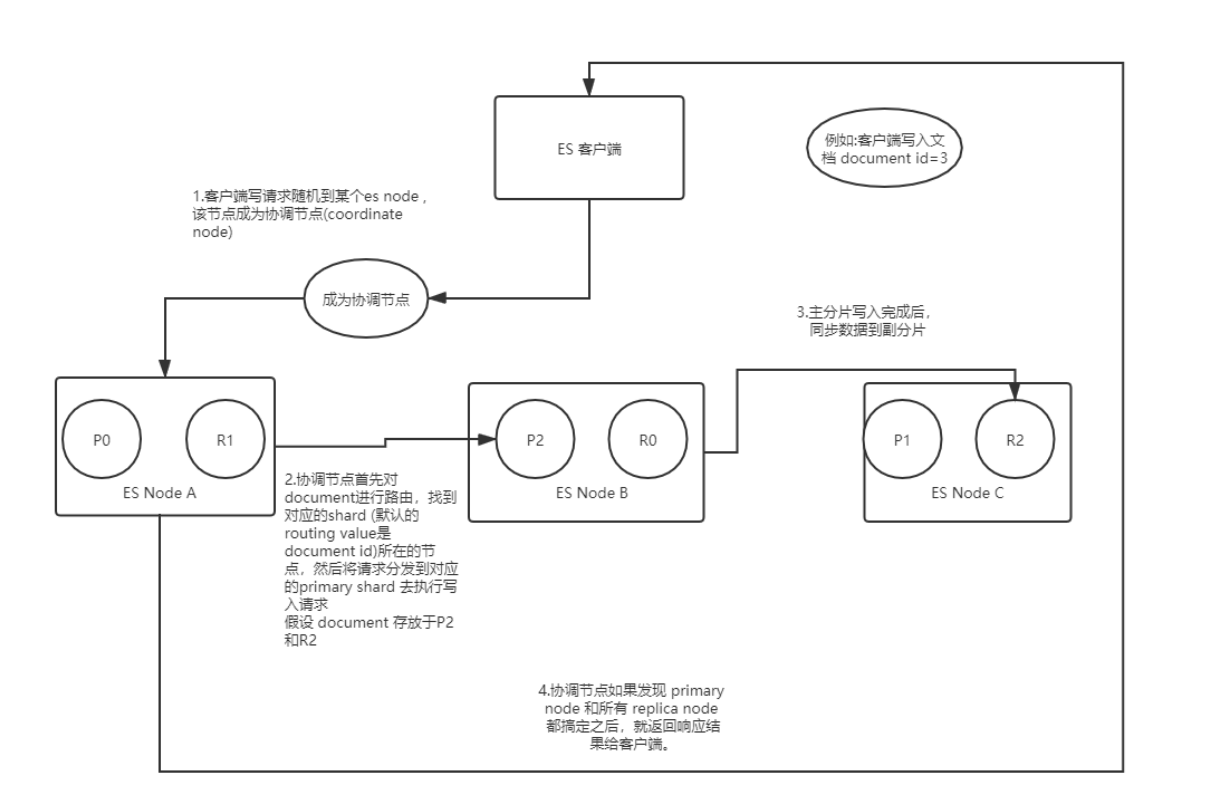
ES写数据的过程:
1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node);
2.协调节点 对 doc id 对哈希,找出该文档存放的primary shard,将请求转发到该shard对应的节点;
3.节点收到请求,primary shard处理写入,然后将数据同步到对应的replica shard 所在的节点;
4.协调节点 发现 主分片和副分片都写入完成后 返回响应结果给 ES 客户端;
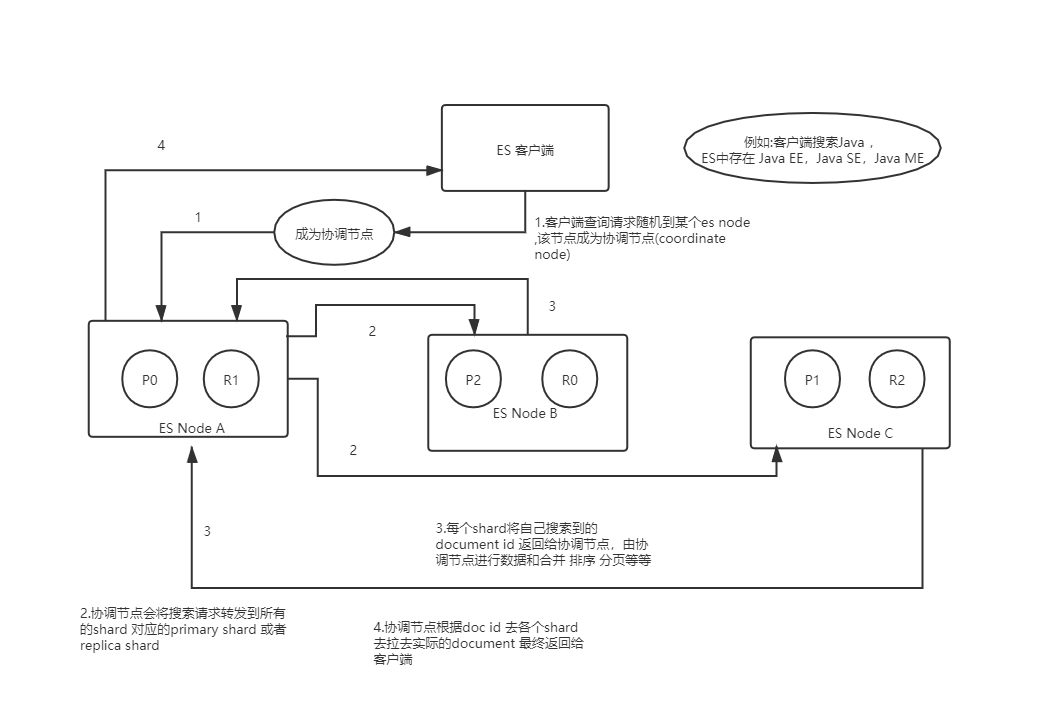
ES搜索数据的过程:
1..ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node);
2. 协调节点将请求发送到所有的shard ,包括primary shard 或者是 replica shard
3. shard 将搜索到的数据 也就是doc id 返回给协调节点
4. 协调节点根据doc id ,将请求分发到doc id 对应的shard 去获取完整的document ,然后将数据返回给ES 客户端
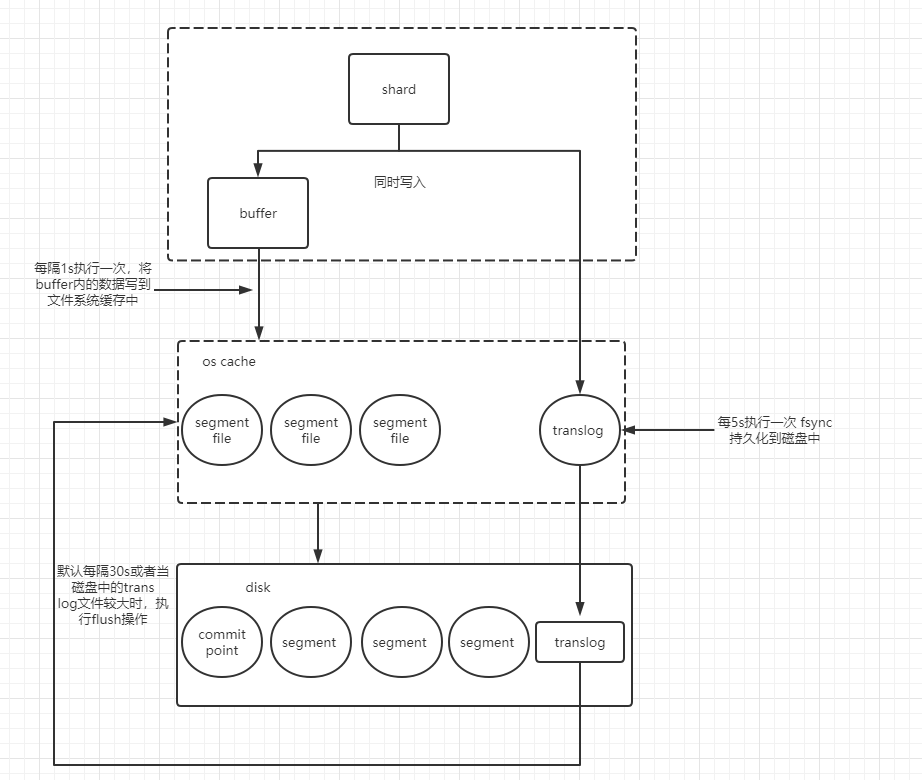
ES写数据的底层原理:
1.shard 收到写入请求后,写到内存buffer,同时写入到translog((每个shard都对应一个translog文件),注意内存buffer里面的数据是搜索不到的
2.shard 会每隔1秒执行refresh操作,将buffer内的数据刷到os cache级别的缓存中去(这里是文件系统缓存),生成新的segement,buffer内的数据被刷到os cache中,
buffer被清空,此时,这个数据也能被搜索到了
3.重复1,2两个步骤,数据会被写入到一个一个的os cache 的 segment file 中去,并刷到磁盘中去,但是每次写入,translog 会越来越大,到达一定长度将会触发 commit 操作
commit 操作
将buffer内的现有数据refresh 到os cache中,清空buffer,然后将一个commit point 写入到磁盘中,里面标识这个commit point对应的所有segment file
同时强行将os cache 里面的数据fsync到磁盘文件中去,最后清空现有的translog文件,重启一个新的translog文件;
fsync+清空translog, 操作就是 flush,默认30分钟执行一次flush,如果translog 文件过大(默认512M)也会触发flush操作,flush
注意:os 文件系统中的translog的数据写到磁盘中 translog文件中 fsync的操作默认每5s 执行一次;
参考:
https://blog.csdn.net/wang7075202/article/details/111308905
https://blog.csdn.net/lsgqjh/article/details/83022206
https://www.jianshu.com/p/15837be98ffd
https://blog.csdn.net/wx1528159409/article/details/105973336/
https://blog.csdn.net/u013129944/article/details/93720081
https://developer.51cto.com/art/202009/625293.htm