1.问题
kafka的常见应用场景
kafka与其他消息中间件的异同点
2.回答
概念:
kafka是分布式的流处理平台
特性:
提供发布订阅及topic支持
吞吐量高,但是不保证消息有序【因为取决于partition的消费情况】
提供了offset的管理,可以消费历史数据。是日志管理机制导致的,因为是从日志文件中检索
3.应用场景回答
日志的收集或者流式系统
消息系统
用户活动跟踪或运营指标监控
4.问题
kafka为什么吞吐量大
kafka为什么速度快
5.回答
存储方面:日志顺序读写和快速检索
并行方面:partition机制
发送与接受:批量发送接收及批量数据压缩机制
原则:通过sendfile实现零拷贝原则
6.问题
kafka的底层日志原理
7.回答
日志格式:
kafka的日志是以partition为单位进行保存
日志目录格式为topic名称+数字
日志文件格式是一个“日志条目”序列
每条日志消息是油4字节整形与N字节消息组成

CRC:用于校验消息内容。占4个字节
MAGIC:用于标识kafka版本,默认是1。占1个字节
ATTRIBUTES:用于存储消息压缩使用的编码以及Timestamp类型。这个版本仅支持 gzip、snappy、lz4三种压缩格式。后三位如果是000则表示没有使用压缩,如果是001则表示是gzip压缩,如果是010则是snappy压缩,如果是011则是snappy压缩。第4位(从右数)如果为0,代表使用create time,如果为1代表append time。其余位保留。占1个字节
TIMESTAMP:时间戳。占8个字节
KEY_SIZE:用于标识KEY内容的长度K。占用4个字节
KEY:存储的是KEY的具体内容。占用K个字节。
VALUE_SIZE:主要标识VALUE的内容的长度V。占用4个字节。
VALUE:消息的真实内容。占用V个字节
日志分段
每个partition的日志将会分为N个大小相等的segment中,方便检索
每个segment中的消息数量不一定相等
每个partition只支持顺序读写,因为随机读写速度慢
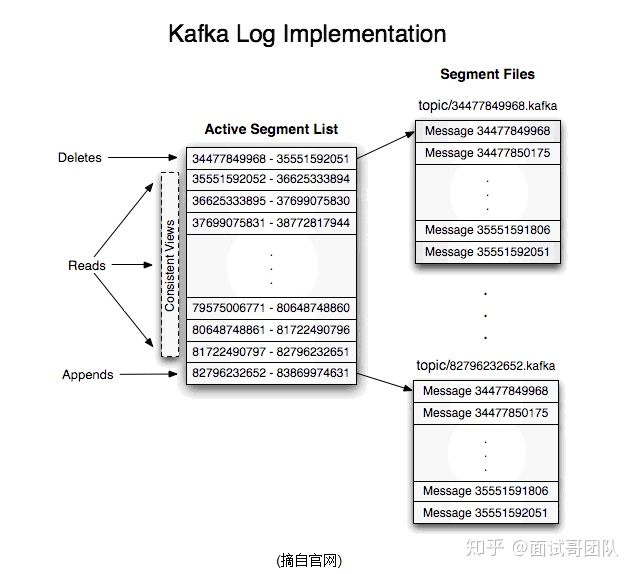
如果命中全局的segmentList,则可以知道对应的segment
segment的存储结构
patition会将消息添加到最后一个segment上
当segment达到一定阈值会flush到磁盘上,consumer的消息读取是读取的磁盘,在内存中的是读取不到的
segment分为两个部分,index与log【里面是具体的数据】
日志读操作
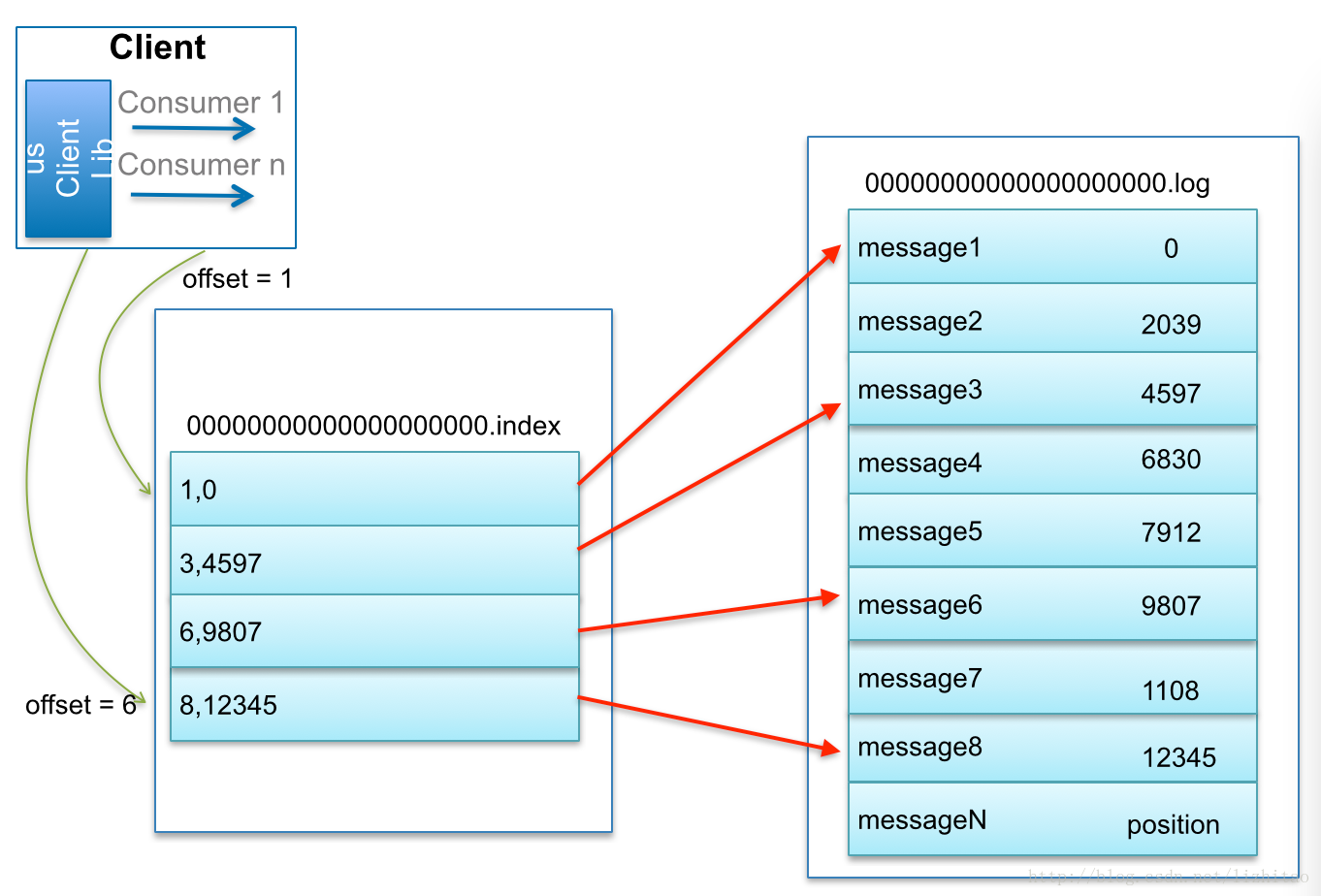
比如:要查找绝对offset为7的Message:
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
8.问腿
零拷贝
9.回答
传统的读取文件数据并发送到网络的步骤如下: (1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存; (2)应用程序将数据从内核空间读入用户空间缓冲区; (3)应用程序将读到数据写回内核空间并放入socket缓冲区; (4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送。
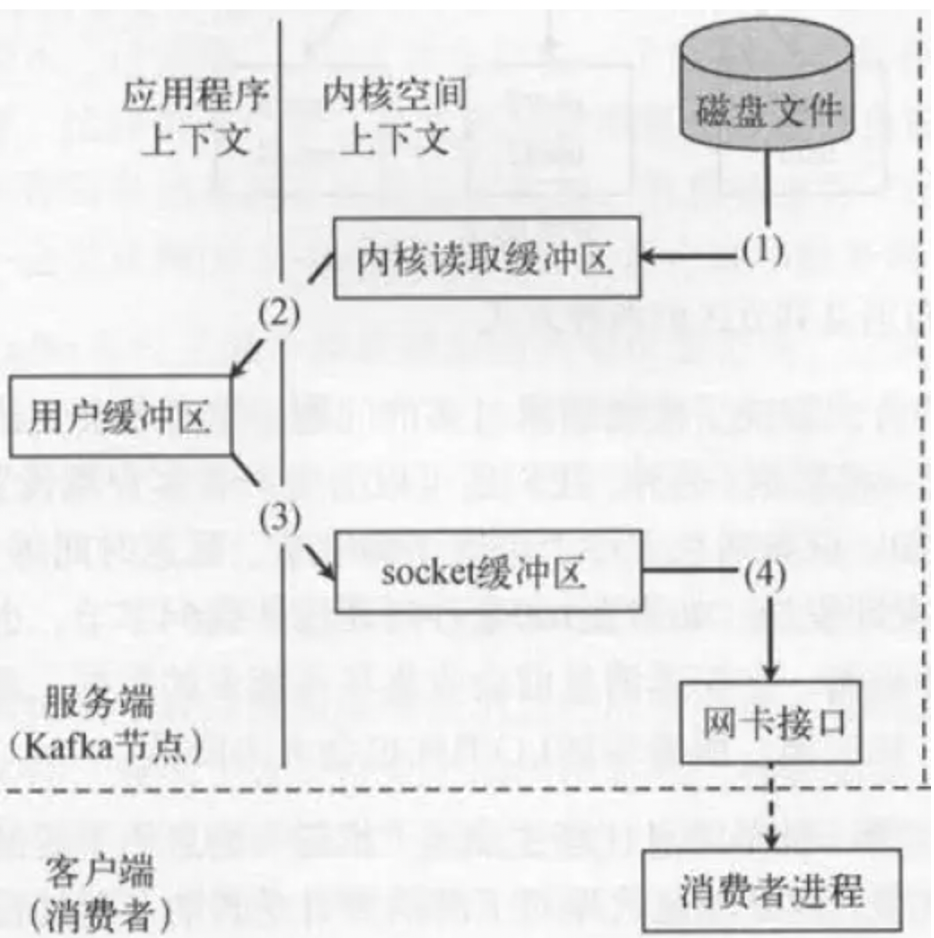
kafka的零拷贝
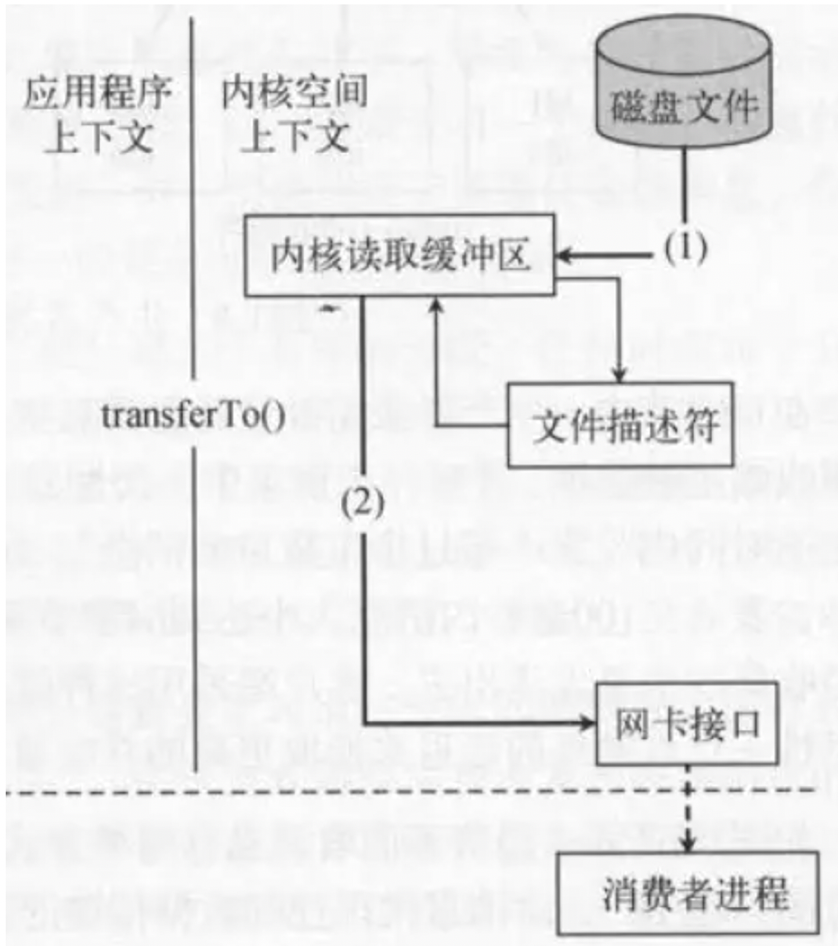
解释:
fileChannel.transferTo( position, count, socketChannel);把磁盘文件读取OS内核缓冲区后的fileChannel,直接转给socketChannel发送;底层就是sendfile。消费者从broker读取数据,就是由此实现。

主要从两条线来回答:
首先是启动了删除topic的进程
然后监听删除命令
建议:

最好是,输入流量进行控制,然后再删除