本文的配置环境是VMware10+centos2.5。
在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验。
如果感觉有问题,欢迎咨询评论。
零:下载ruanjian
1.下载
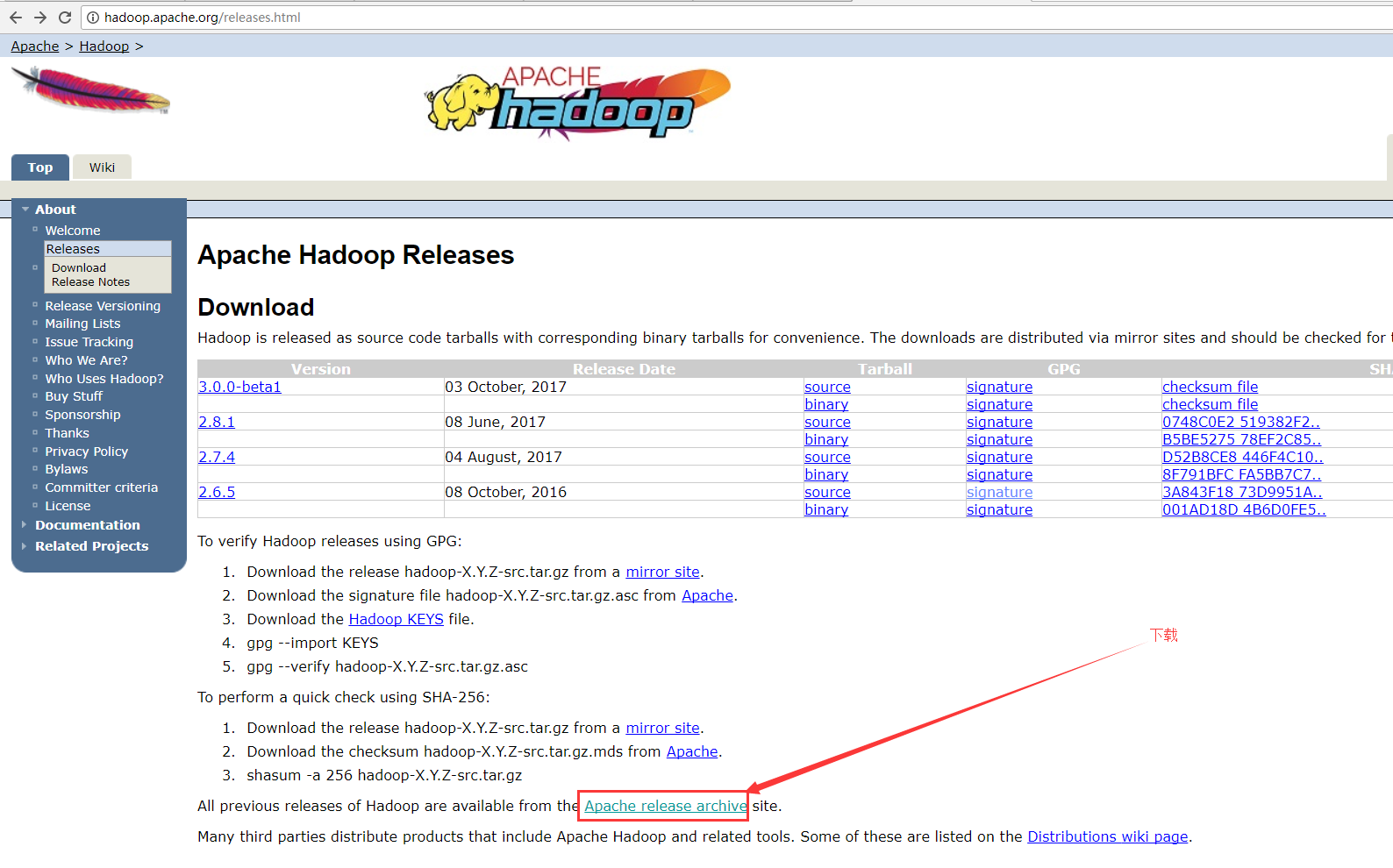
2.下载网址
https://archive.apache.org/dist/hadoop/common/
一:伪分布式准备工作
1.规划目录

2.修改目录所有者和所属组

3.删除原有的jdk

4.上传需要的jdk包

5.增加jdk 的执行权限

6.解压jdk

7.修改profile的JAVA_HOME,PATH

8.使文件生效
不需要使用root用户。

9.检验jdk是否成功

二:搭建为分布式(主要是namenode与datanode)
1.解压hadoop

2.进入hadoop主目录

3.获取JAVA_HOME的目录

4.*.env.sh
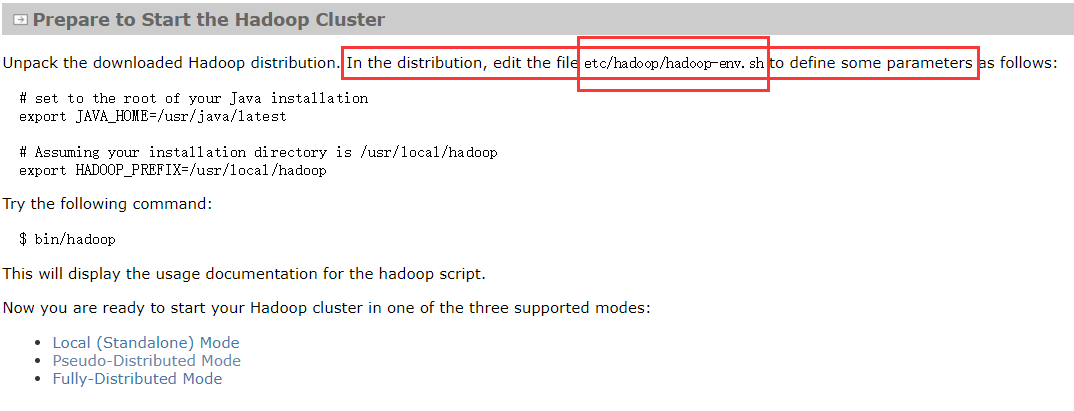
5.修改hadoop-env.sh的JAVA_HOME

6.修改mapred-env.h的JAVA_HOME
虽然官网没说,但是也需要修改。

7.修改yarn-env.sh的JAVA_HOME
虽然官网没说,但是也需要修改。

8.*-site.xml配置
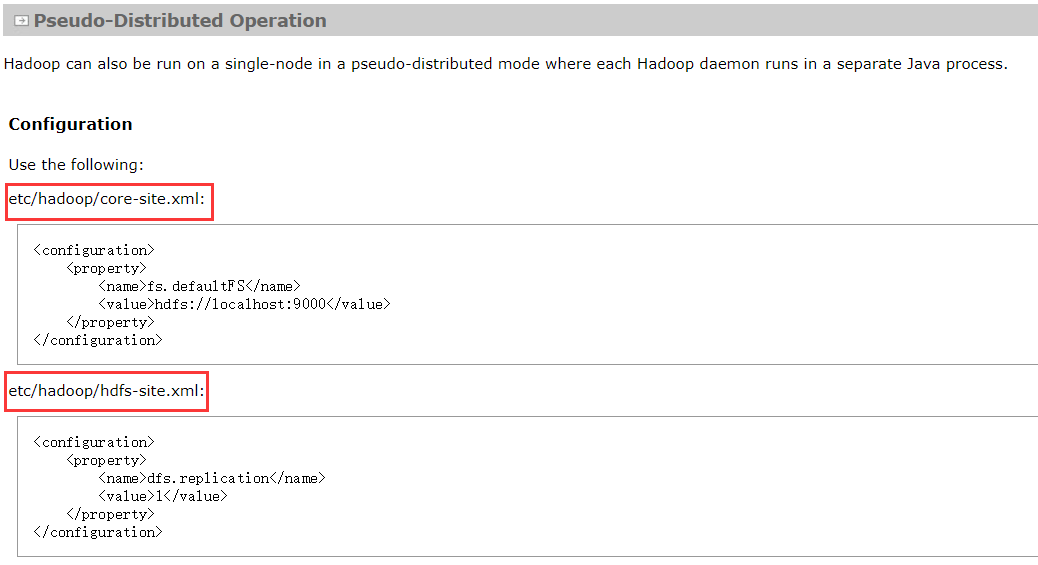
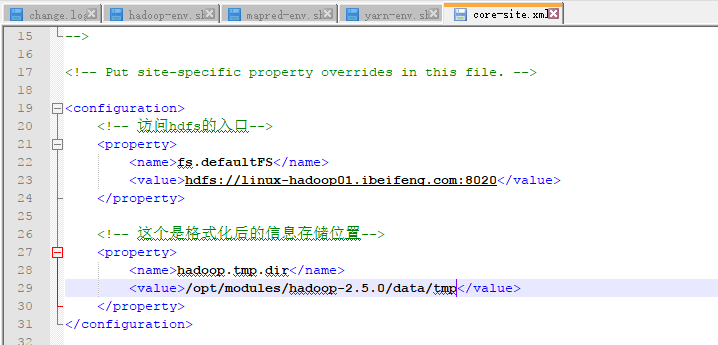
9.配置core-site.xml
8020是交互端口,namenode启动以后,可以通过浏览器进行访问hdfs文件系统。
新建一个临时目录:
注意点:sudo chown -R beifeng:beifeng data
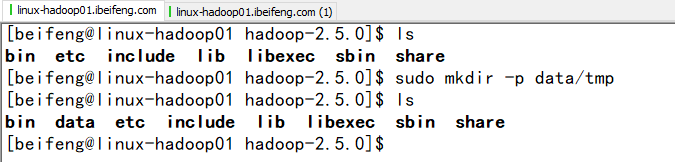
配置:
10.修改slave的配置

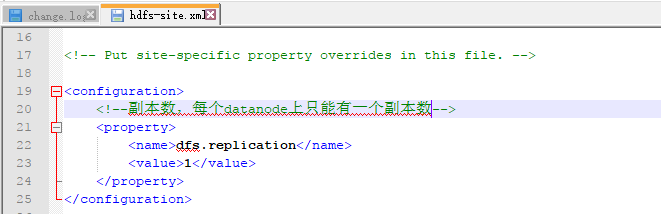
11.修改hdfs.site.xml
12.执行

13.检验hdfs

14.格式化hdfs
对文件操作系统进行格式化。


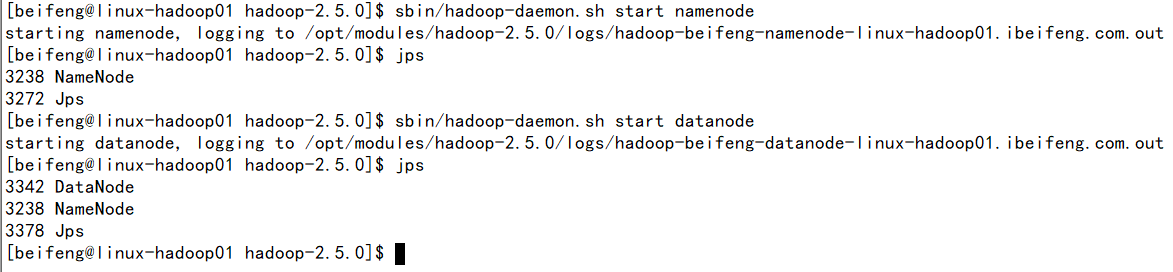
15.启动namenode 以及datanode进程
注意:
sudo chmod -R a+w hadoop-2.5.0/ 增加权限,因为要产生log文件夹。
16.查看浏览器,方便管理HDFS
http://linux-hadoop01.ibeifeng.com:50070/

17.在HDFS上新建文件夹


15.在HDFS上上传文件


16.在HDFS上读取wenjian

17.在HDFS上下载文件到本地

18.删除在HDFS上的文件
bin/hdfs dfs -rm -f core-site.xml
如果不知道可以使用bin/hdfs dfs ,在确认后就弹出使用方法
三:继续搭建伪分布式(YARN部分的搭建)
1.官网
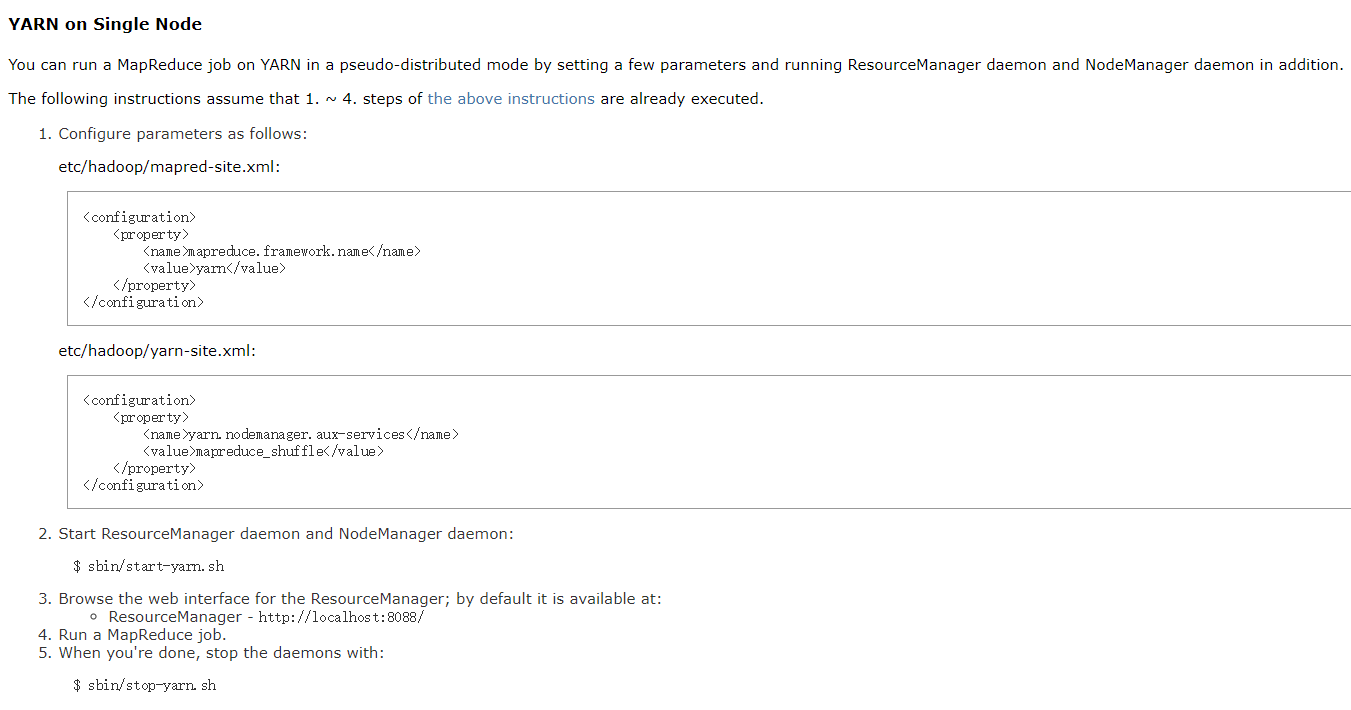
2.配置yarn-site.xml

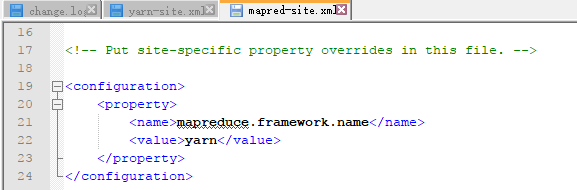
2..配置MapReduce的配置,MapReduce.site.xml
表示mapreduce将要运行在yarn上
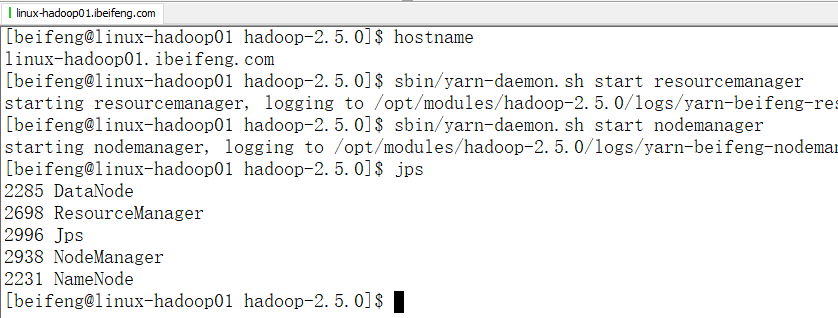
3.启动
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
4.浏览器上观察
端口为8088.
http://linux-hadoop01.ibeifeng.com:8088
5.新建将要测试的文件


6.在HDFS上新建文件目录


7.上传本地的wc.input文件进刚刚新建的目录


8.在yarn上运行计算
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount mapreduce/wordcount/input mapreduce/wordcount/output1


9.查看结果
bin/hdfs dfs -text mapreduce/wordcount/output1/pa*

这个时候因为没有配置历史服务器,所以在途中的history没有用。

四:历史服务器的配置
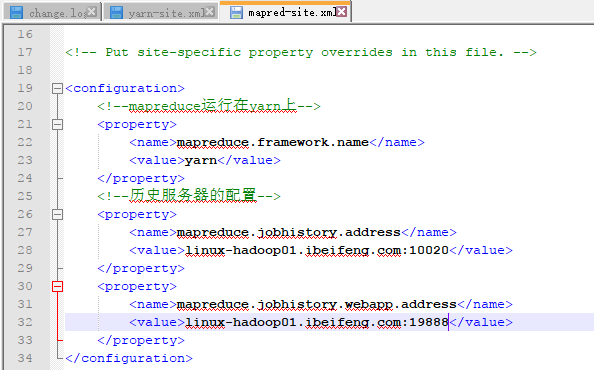
1.配置历史服务器,修改mapred-xite.xml
历史服务器可以查看已经完成的MR程序作业记录。
默认情况下历史服务器是不启动的。
所以配置在mapred-site.xml中。
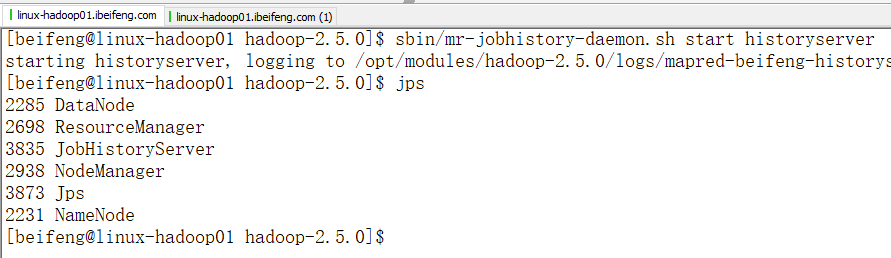
2.启动服务器

3.建议历史服务器在yarn启动之后紧接着启动
sbin/mr-jobhistory-daemon.sh start historyserver
4.浏览器观察
web端口是19888.
再点击一下刚才的history,这里不需要再次运行mapreduce程序。
五:日志聚集功能
1.问题由来
这个log的聚集主要说的是yarn里面的日志功能。
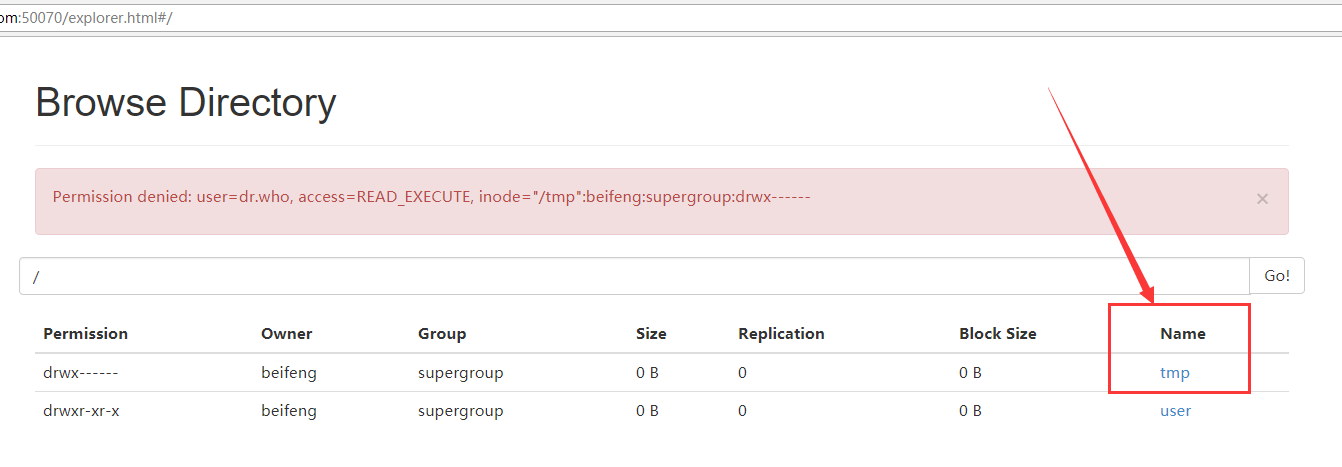
会将MR程序运行的日志上传到HDFS上的目录中,默认会在‘/’下产生一个tmp目录,这个tmp可以在HDFS的50070上看到,同时这个tmp对用户是无效的,没有权限。
很多mapreduce会对应需要的日志,如果将日志聚集到hdfs上,可以方便的查看。
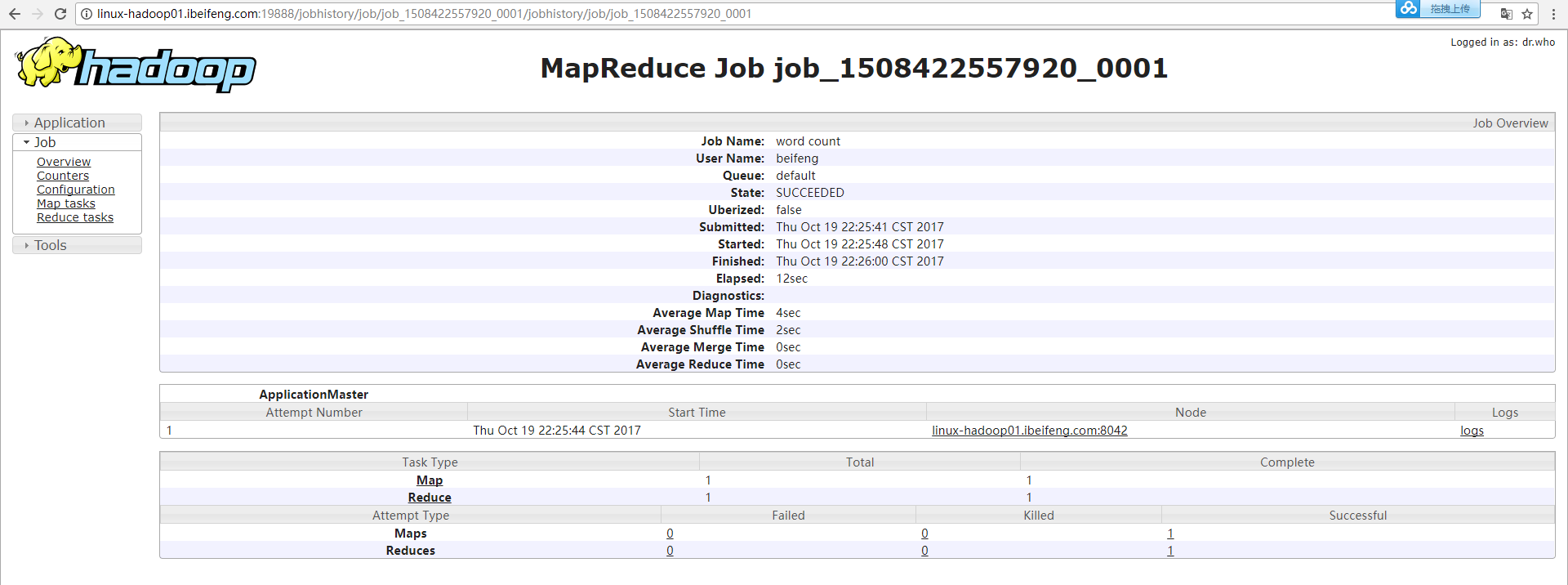
19888上的logs:

50070上的tmp
2.日志聚集功能,修改yarn.site.xml

3.重新启动resourcemanager,nodemanager,jobhistory

6.再次在yarn上运行程序

7.这时就可以点击logs,在yarn的管理页面上观看日志文件

8.logs点击的结果

但是问题还是没有完全解决好,有下面的问题。
9.HDFS用户权限的修改,点击tmp时,出现的问题效果

10.修改hdfs.xite.xml,使hdfs不在检查用户权限
HDFS上会存在用户权限检查。

11.重新启动HDFS
这个时候,其实,yarn也需要关闭,只是在验证tmp时可以不启动yarn。

12.再次点击tmp,即可进入

六:静态用户名的修改
1.修改静态用户名,之前的状态

2.修改core.site.xml

3.重启HDFS和YARN

4.重启任务

5.这时静态用户将会变成设置的用户
