1.构成
由RDD+Schema构成
RDD: DataFrame中的数据 ===> df.rdd
Schema: RDD中数据的结构 ===> df.schema
df是dataFrame。
2.官网


3.DataFrame的本质
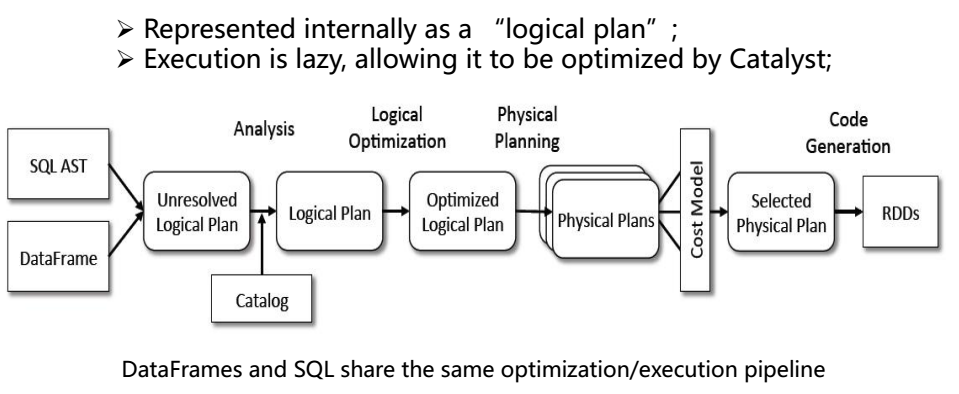
内部实质上就是一个逻辑执行计划
Catalyst模块负责逻辑执行计划
逻辑计划 -> 分析逻辑计划 -> 优化逻辑计划 -> 产生物理计划(多个) -> 判断物理计划的执行成本 -> 选择一个最优物理计划SparkCore代码生成 -> SparkCore代码执行
题外:Spark2.x之前的版本不支持逻辑计划产生的修改
Spark2.x支持用户自定义HQL逻辑计划产生
4.DataFrame的数据保存
第一种: 将Dataframe转换为RDD,RDD数据保存
第二种: 直接通过DataFrame的write属性将数据写出(有限制,必须有定义类实现,默认情况:SparkSQL只支持parquet、json、jdbc...)
5.创建DataFrame
val df = sqlContext.# :这个是使用各种api,例如sql,然后返回dataFrame。
val df = sqlContext.read.#