一:知识点
1.安装requests库

2.Brautiful soup
可以提供一些简单的,python式的函数来处理导航,搜索,修改分析树等功能。
她是一个工具箱,通过解析文档为用户提供需要抓去的数据。
自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
现在是使用Beautiful Soup4,不过现在已经被移植到BS4了,即导入需要导入bs4。
3.导入
pip install beautifulsoup4
4.创建Beautiful Soup对象
导入bs4库
from bs4 import BeautifulSoup
创建:
soup=BeautifulSoup(html)
5.程序
1 import requests 2 from bs4 import BeautifulSoup 3 r=requests.get("http://www.baidu.com",headers={'User-Agent':'Mozilla/4.0'}) 4 soup=BeautifulSoup(r.text,"html.parser") 5 print soup.prettify()
6.打印soup的内容
print soup.prettify()
7.四大对象种类
Beautiful Soup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,将所有的对象归纳为四种。
BeautifulSoup
Tag
NavigableString
Comment
8.BeautifulSoup
对象表示是一个文档的全部内容,大部分的时候,可以将它当作Tag对象,是一个特殊的Tag,我们可以获取它的类型,名称,以及属性。
soup.name
soup.attrs
9.Tag的使用
找到的是第一个,后面的都没显示。
soup.title.name
soup.title.attrs
soup.meta['content']
soup.meta.get('content')
1 import requests 2 from bs4 import BeautifulSoup 3 r=requests.get("http://www.baidu.com",headers={'User-Agent':'Mozilla/4.0'}) 4 soup=BeautifulSoup(r.text,"html.parser") 5 print soup.title 6 print soup.meta
效果:
<title>百度一下,你就知道</title>
<meta content="text/html;charset=utf-8" http-equiv="content-type"/>
10.NavigableString
获取标签内部的文字。
soup.标签名.string
1 import requests 2 from bs4 import BeautifulSoup 3 r=requests.get("http://www.baidu.com",headers={'User-Agent':'Mozilla/4.0'}) 4 soup=BeautifulSoup(r.text,"html.parser") 5 print soup.title.string
效果:
百度一下,你就知道
11.Comment
是一个特殊类型的NavigableString对象,其实输出的内容仍然不包含注释符号。
12.常用方法(过滤)
name
attrs
text
limit
recursive:要不要搜索子孙节点。
13.常用方法
find_all
find
.contents .children
.descendants
.string
.parent
.next_sibling
next_elements .previous_elements
14.程序
1 import requests 2 from bs4 import BeautifulSoup 3 r=requests.get("http://www.baidu.com",headers={'User-Agent':'Mozilla/4.0'}) 4 soup=BeautifulSoup(r.text,"html.parser") 5 print soup.script.parent 6 print soup.title.string
二:案例
1.网址
https://movie.douban.com/top250?start=0&filter=
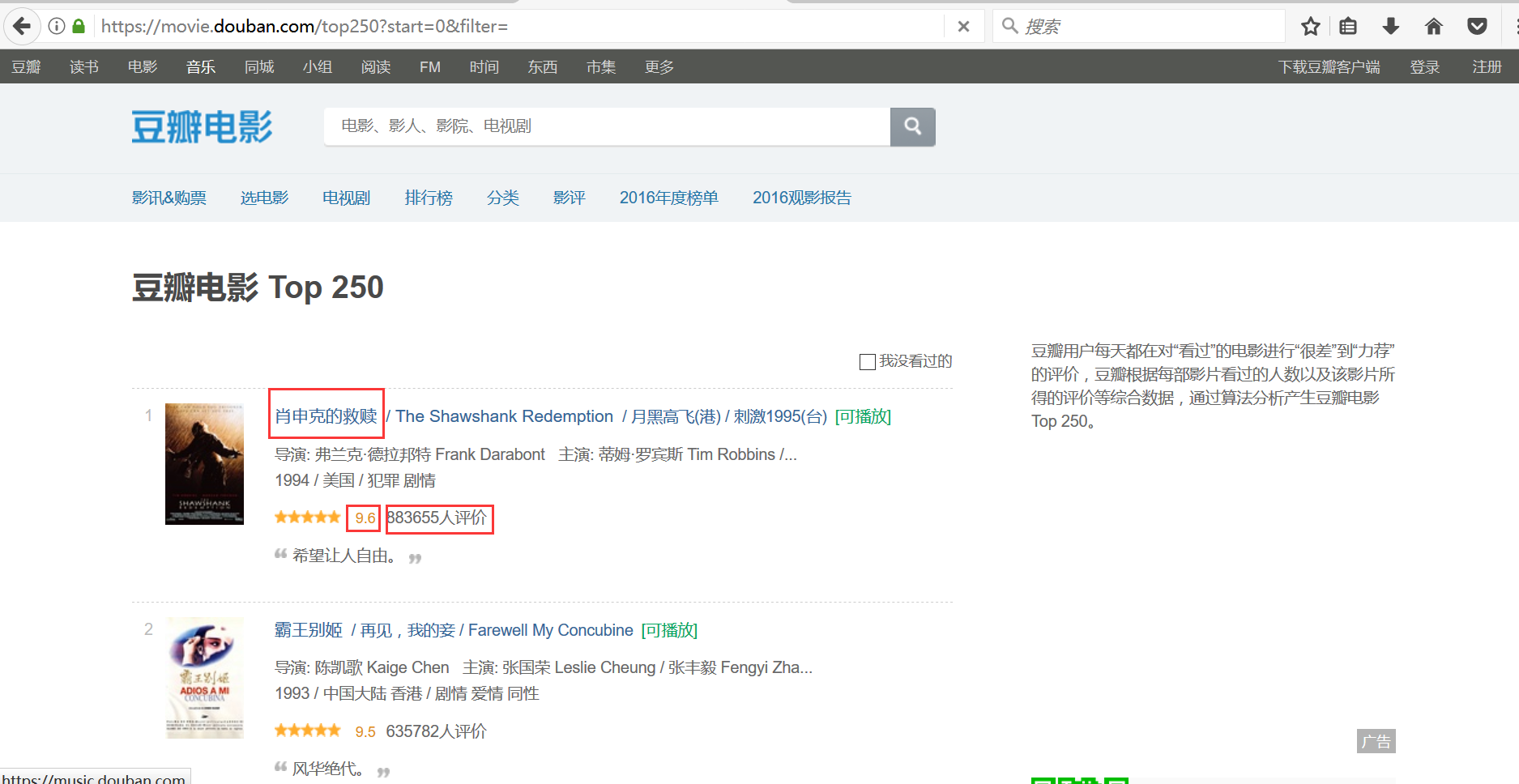
2.程序
1 #encoding=utf-8 2 import requests 3 from bs4 import BeautifulSoup 4 import re 5 import xlwt 6 7 #创建全局变量,保存电影信息 8 dataList=[] 9 10 #根据地址和开始行获取网页的文本内容 11 def getHtmlTest(url,startRow): 12 #头部筛选函数 13 if(startRow==0): 14 param={} 15 else: 16 param={'start':startRow,'filter':''} 17 #获取网页 18 r=requests.get(url,params=param,headers={'User-Agent':'Mozilla/4.0'}) 19 return r.text 20 21 #创建函数将传入的文本解析获取所需要的数据 22 def getData(html): 23 soup=BeautifulSoup(html,'html.parser') 24 #获取class为grid_view的ol下面的所有列表 25 movieList=soup.find('ol',attrs={'class':'grid_view'}) 26 #遍历查找内容 27 for movieLi in movieList.find_all('li'): 28 data=[] 29 #获取电影名称 30 movieHd=movieLi.find('div',attrs={'class':'hd'}) 31 movieName=movieHd.find('span',attrs={'class':'title'}).getText() 32 data.append(movieName) 33 34 #电影分数 35 movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText() 36 data.append(movieScore) 37 38 #电影评价人数 39 movieEval=movieLi.find('div',attrs={'class':'star'}) 40 movieEvalNum=re.findall(r'd+',str(movieEval))[-1] 41 data.append(movieEvalNum) 42 43 #电影评价 44 movieQuote=movieLi.find('span',attrs={'class','inq'}) 45 if(movieQuote): 46 data.append(movieQuote.getText()) 47 else: 48 data.append("无影评信息") 49 50 #添加到全局变量中 51 dataList.append(data) 52 return 53 54 #保存到excel 55 def saveData(savePath): 56 book=xlwt.Workbook(encoding='utf-8') 57 sheet=book.add_sheet('前250名的电影信息') 58 col=(u'电影名称',u'电影评分',u'评论人数',u'短评') 59 for i in range(0,4): 60 sheet.write(0,i,col[i]) 61 for i in range(0,250): 62 data=dataList[i] 63 for j in range(0,4): 64 sheet.write(i+1,j,data[j]) 65 book.save(savePath) 66 return 67 68 #创建主函数 69 def mainFunc(): 70 url='https://movie.douban.com/top250' 71 startRow=0 72 while startRow<250: 73 html=getHtmlTest(url,startRow) 74 getData(html) 75 startRow += 25 76 saveData('movieData.xls') 77 return 78 79 #测试 80 mainFunc()
3.效果
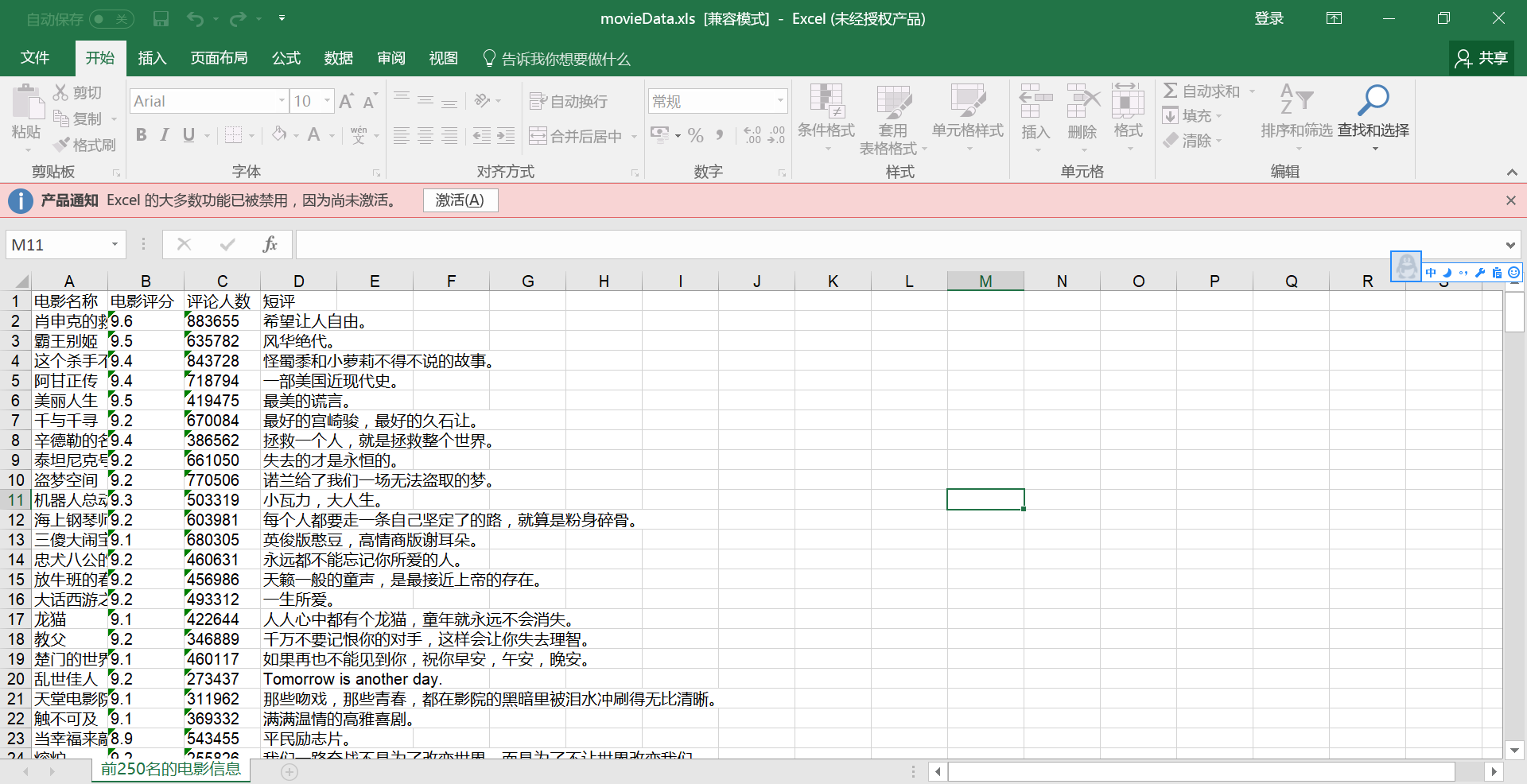
·