一:RDD与DataFrame互相转换
1.总纲

二:DataFrame转换为RDD
1.rdd
使用schema可以获取DataFrame的schema
使用rdd可以获取DataFrame的数据
三:RDD转换为DataFrame
1.第一种方式
使用反射,
RDD的数据类型必须是case class。
1 import sqlContext.implicits._ //如果不写,下面的转换不成功 2 3 //transform 4 val path="/spark/logs/input" 5 val rdd=sc.textFile(path) 6 val apacheAccessDataFrame=rdd 7 .filter(line=>ApacheAccessLog.isValidateLogLine(line)) 8 .map(line => { 9 ApacheAccessLog.parseLogLine(line) 10 }).toDF() //rdd转换为DataFrame
其中,ApacheAccessLog.parseLogLine(line)是case class类型。
2:第二种方式
1 package com.scala.it 2 import org.apache.spark.rdd.RDD 3 import org.apache.spark.sql.types._ 4 import org.apache.spark.sql.{Row, SQLContext} 5 import org.apache.spark.{SparkConf, SparkContext} 6 object CreateDataFrameDemo { 7 def main(args: Array[String]): Unit = { 8 val conf = new SparkConf() 9 .setMaster("local[*]") 10 .setAppName("hive-join-mysql") 11 // 使用kryo序列化机制 12 conf.registerKryoClasses(Array(classOf[Row], classOf[Tuple3[Int, String, Double]])) 13 val sc = SparkContext.getOrCreate(conf) 14 15 val sqlContext = new SQLContext(sc) 16 17 // =================================== 18 // RDD中Row中的各个列的类型必须是一致的(不能有歧义) 19 val rdd: RDD[Row] = sc.parallelize(Array( 20 (1, "Tom", 1234.1), 21 (2, "Lili", 12532.2), 22 (3, "Gerry", 123.0) 23 )).map { 24 case (id, name, salary) => { 25 Row(id, name, salary) 26 } 27 } 28 val schema: StructType = StructType(Array( 29 StructField("id", IntegerType), 30 StructField("name", StringType), 31 StructField("salary", DoubleType) 32 )) 33 34 val df = sqlContext.createDataFrame(rdd, schema) 35 df.show() 36 } 37 }
3.解释上面的程序
产生RDD有两种方式,读取数据源,或者序列化
这里使用序列化产生RDD。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
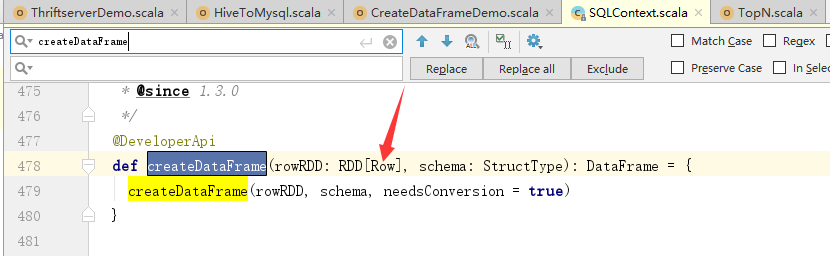
关于rdd中为什么要使用Row:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
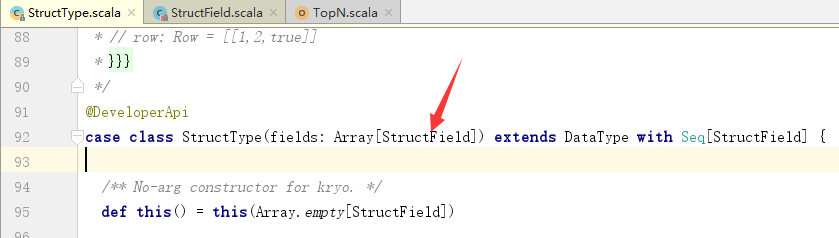
关于StructType:
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
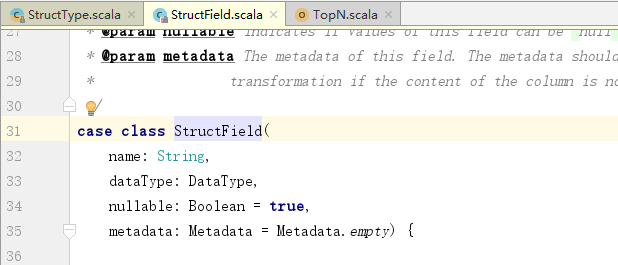
关于StructField:
其中,后两个是默认参数,可以不给。