1.问题
主要是updateStateByKey的问题
有的值不需要变化的时候,还会再打印出来。
每个批次的数据都会出现,如果向redis保存更新的时候,会把不需要变化的值也更新,这个不是我们需要的,我们只需要更新有变化的那部分值。
2.mapWithState
有一个注解,说明是实验性质的。
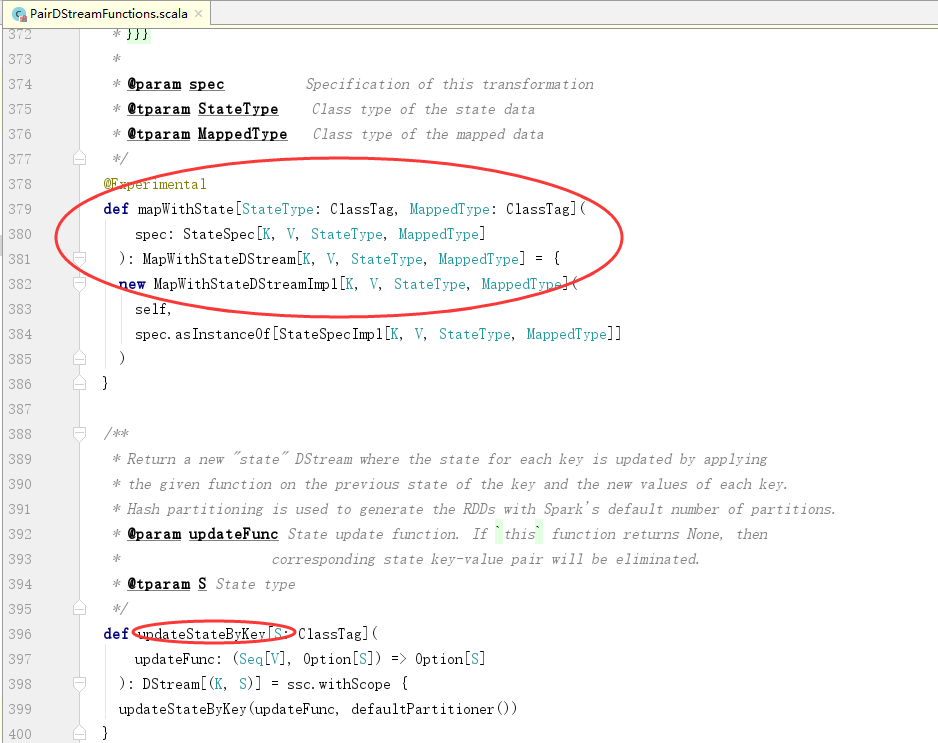
3.程序
1 package com.stream.it 2 import org.apache.spark.rdd.RDD 3 import org.apache.spark.storage.StorageLevel 4 import org.apache.spark.streaming.dstream.DStream 5 import org.apache.spark.streaming.kafka.KafkaUtils 6 import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext} 7 import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} 8 9 object MapWithState { 10 def main(args: Array[String]): Unit = { 11 val conf = new SparkConf() 12 .setAppName("StreamingMapWithState") 13 .setMaster("local[*]") 14 val sc = SparkContext.getOrCreate(conf) 15 val ssc = new StreamingContext(sc, Seconds(1)) 16 // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir 17 // 路径对应的文件夹不能存在 18 ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir45254") 19 20 /** 21 * 22 * @param key DStream的key数据类型 23 * @param values DStream的value数据类型 24 * @param state 是StreamingContext中之前该key的状态值 25 * @return 26 */ 27 def mappingFunction(key: String, values: Option[Int], state: State[Long]): (String, Long) = { 28 // 获取之前状态的值 29 val preStateValue = state.getOption().getOrElse(0L) 30 // 计算出当前值 31 val currentStateValue = preStateValue + values.getOrElse(0) 32 33 // 更新状态值 34 state.update(currentStateValue) 35 36 // 返回结果 37 (key, currentStateValue) 38 } 39 val spec = StateSpec.function[String, Int, Long, (String, Long)](mappingFunction _) 40 41 val kafkaParams = Map( 42 "group.id" -> "streaming-kafka-001231", 43 "zookeeper.connect" -> "linux-hadoop01.ibeifeng.com:2181/kafka", 44 "auto.offset.reset" -> "smallest" 45 ) 46 val topics = Map("beifeng" -> 4) // topics中value是读取数据的线程数量,所以必须大于等于1 47 val dstream = KafkaUtils.createStream[String, String, kafka.serializer.StringDecoder, kafka.serializer.StringDecoder]( 48 ssc, // 给定SparkStreaming上下文 49 kafkaParams, // 给定连接kafka的参数信息 ===> 通过Kafka HighLevelConsumerAPI连接 50 topics, // 给定读取对应topic的名称以及读取数据的线程数量 51 StorageLevel.MEMORY_AND_DISK_2 // 指定数据接收器接收到kafka的数据后保存的存储级别 52 ).map(_._2) 53 54 val resultWordCount: DStream[(String, Long)] = dstream 55 .filter(line => line.nonEmpty) 56 .flatMap(line => line.split(" ").map((_, 1))) 57 .reduceByKey(_ + _) 58 .mapWithState(spec) 59 60 resultWordCount.print() // 这个也是打印数据 61 62 // 启动开始处理 63 ssc.start() 64 ssc.awaitTermination() // 等等结束,监控一个线程的中断操作 65 } 66 }
4.效果

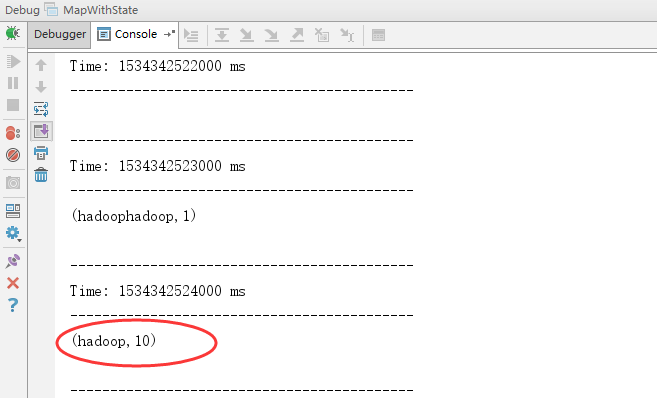
在控制台上再写入一个hadoop:
说明了,在新写入的时候,才会出现,但是以前的数据还在。
5.说明
因为存在checkpoint,在重新后,以前的数据还在,新加入数据后,会在原有的基础上进行更新,上面的第二幅图就是这样产生的。