近来学习多线程爬虫,发现书上关于爬取简书网热评文章的代码因网页更改问题运行有误,在此修正。
开发环境:(Windows)eclipse+pydev+MongoDB
爬取网址:传送门
1、手动浏览网页,发现没有分页的界面,可判断该网站采用了异步加载技术。
2、查看网页源代码,通过观察源代码Network处Headers的URL,发现只需改变page后的页数即可获得不同的页面。
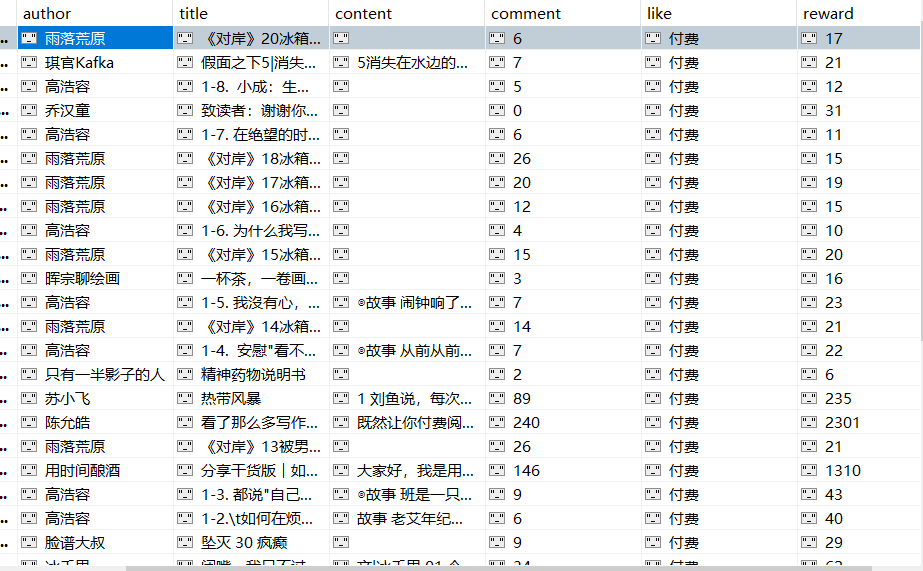
(爬取内容:用户名、标题、内容、评论数、点赞数、打赏数)
3、连接数据库(见本人其余博文,不再赘述)
代码:
# _*_ coding:utf-8 _*_
import requests
import pymongo
from multiprocessing import Pool
from lxml import etree
client = pymongo.MongoClient('localhost',27017) #连接数据库
mydb = client['mydb'] #创建数据库
jianshu_shouye =mydb['jianshu_shouye'] #创建集合
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
def get_jianshu_info(url):
html = requests.get(url,headers = headers) #获取页面请求
selector = etree.HTML(html.text) #分析返回文本
infos = selector.xpath('//ul[@class="note-list"]/li') #观察源代码三角标,可得循环点
for info in infos :
try:
author = info.xpath('div/div/a/text()')[0]
title = info.xpath('div/a/text()')[0]
content = info.xpath('div/p/text()')[0].strip()
comment = info.xpath('div/div/a[2]/text()')[1].strip()
like = info.xpath('div/div/span[1]/text()')[0]
rewards = info.xpath('div/div/span[2]/text()')
if len(rewards) == 0:
reward = '无'
else:
reward = rewards[0].strip()
data = {
'author':author,
'title':title,
'content':content,
'comment':comment,
'like':like,
'reward':reward
}
jianshu_shouye.insert_one(data)
except IndexError:
pass
if __name__=='__main__':
urls = ['https://www.jianshu.com/c/bDHhpK?order_by=added_at&page={}'.format(str(i)) for i in range(1,10001)]
pool = Pool(processes = 4) #创建进程池
pool.map(get_jianshu_info, urls)
#所谓循环点即爬取区域每一小段的完整信息标签(其上没有再囊括其的三角标)
运行Robomongo查看数据存储情况: