zoukankan
html css js c++ java
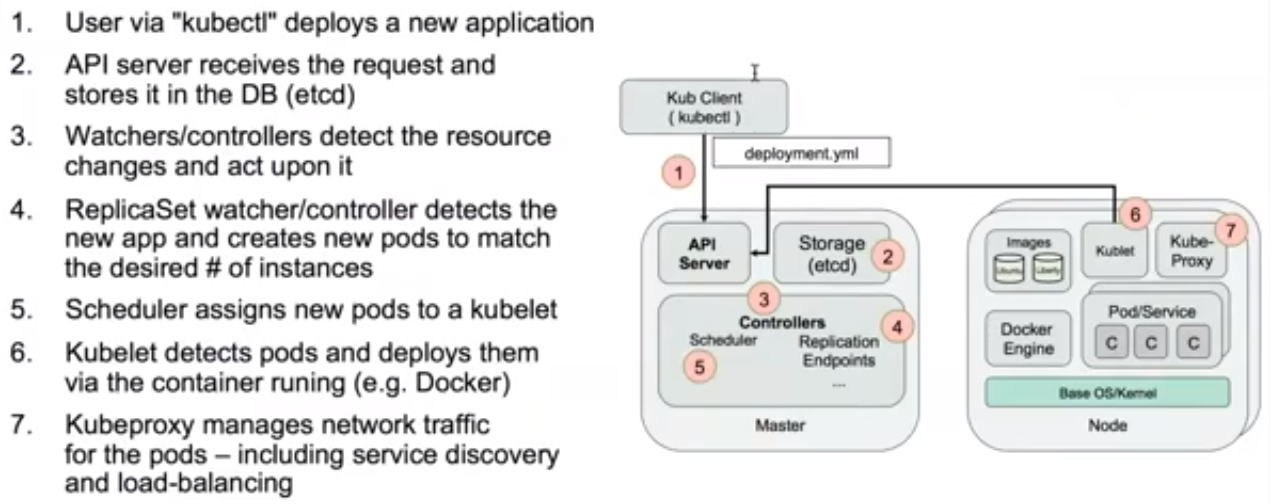
一个典型的kubernetes工作流程
1、准备好一个包含应用程序的Deployment的yml文件,然后通过kubectl客户端工具发送给ApiServer。
2、ApiServer接收到客户端的请求并将资源内容存储到数据库(etcd)中。
3、Controller组件(包括scheduler、replication、endpoint)监控资源变化并作出反应。
4、ReplicaSet检查数据库变化,创建期望数量的pod实例。
5、Scheduler再次检查数据库变化,发现尚未被分配到具体执行节点(node)的Pod,然后根据一组相关规则将pod分配到可以运行它们的节点上,并更新数据库,记录pod分配情况。
6、Kubelete监控数据库变化,管理后续pod的生命周期,发现被分配到它所在的节点上运行的那些pod。如果找到新pod,则会在该节点上运行这个新pod。
7、kuberproxy运行在集群各个主机上,管理网络通信,如服务发现、负载均衡。例如当有数据发送到主机时,将其路由到正确的pod或容器。对于从主机上发出的数据,它可以基于请求地址发现远程服务器,并将数据正确路由,在某些情况下会使用轮训调度算法(Round-robin)将请求发送到集群中的多个实例。
做一个有底蕴的软件工作者
查看全文
相关阅读:
CodeForces 543d Road Improvement
UVA Foreign Exchange
ZOJ 1825 Compound Words
UVA 10125 Sumsets
CodeForces
32位linux(centos)下mongoDB的安装
关于PHP 采集类
关于微信支付零时工代码的修正方法
微信公众号申请,微信支付全攻略 2
简介CentOS与 Ubuntu的不同
原文地址:https://www.cnblogs.com/justmine/p/8684564.html
最新文章
CTO俱乐部官方群聊-探讨创业和跳槽
[python]常用的几个包
【SVM】libsvm-python
【Debian】ftp安装
【Debian】时间设置
【linux】硬盘分区
【Cubian】set up
【cb2】安装终端
【cb2】扩展硬盘
[CB2]start up
热门文章
[R]RMySQL set up
(转)CloudStack 安装及使用过程中常见问题汇总
主从复制报错
mysqldump: Got error: 1356 mysqldump的重要参数--force
openstack vm ping 114.114.114.114
POJ 2502 Subway
HDU 2476 String painter
2015 Multi-University Training Contest 1 Assignment
2015 Multi-University Training Contest 1 OO’s Sequence
2015 Multi-University Training Contest 1 Tricks Device
Copyright © 2011-2022 走看看