先记录一下 idea安装Python的语言支持插件后的操作:我用的是windows环境、windows环境、windows环境。
首先 下载 Anaconda3 的可执行文件 下载地址

然后安装,安装过程中有一个环节,默认打了一个勾,把上面的配置环境变量也勾上,然后一路next
借图说明下:
安装完成后,打开cms 输入 :conda info --env 查看下环境,默认只有一个base;
下面那个py37是后来建的,创建命令conda create -n py37

删除环境谨慎执行:conda remove -n py37
激活环境:activate base
关闭环境:deactivate base
激活后,就可以起飞了。
惯例:helloworld
#!/usr/bin/python3 print('hello world')
1,
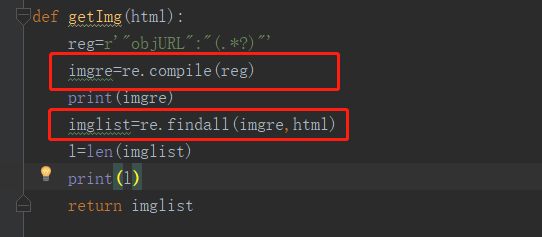

报错原因:
TypeError: can’t use a string pattern on a bytes-like object.
html用decode(‘utf-8’)进行解码,由bytes变成string。
py3的urlopen返回的不是string是bytes。
解决:
html = html.decode('utf-8')
2.

报错原因:
如果用 urllib.request.urlopen 方式打开一个URL,服务器端只会收到一个单纯的对于该页面访问的请求,但是服务器并不知道发送这个请求使用的浏览器,操作系统,硬件平台等信息,而缺失这些信息的请求往往都是非正常的访问,例如爬虫.
有些网站为了防止这种非正常的访问,会验证请求信息中的UserAgent(它的信息包括硬件平台、系统软件、应用软件和用户个人偏好),如果UserAgent存在异常或者是不存在,那么这次请求将会被拒绝(如上错误信息所示)
所以可以尝试在请求中加入UserAgent的信息
解决:
def getHtml(url): u = urllib.request.URLopener() # Python 3: urllib.request.URLOpener u.addheaders = [] u.addheader( 'Accept', '*/*') u.addheader('Accept-Language','en-US,en;q=0.8') u.addheader( 'Cache-Control', 'max-age=0') u.addheader( 'User-Agent', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36') u.addheader( 'Connection', 'keep-alive') u.addheader( 'Referer', 'http://www.baidu.com/') page=u.open(url) html = page.read() html = html.decode('utf-8',"ignore") page.close() return html
3.在一个py文件中,引入另一个py文件,直接import即可
4.用python3版本,引入request的下载函数 urlretrieve时候,可以这么做,举一反三,可以减少代码量
from urllib.request import urlretrieve
urlretrieve(url,filename)
5.在获取对象Html时,即使加了decode('utf-8'),也仍旧报错:
'utf-8' codec can't decode byte 0xd7 in position 309: invalid continuation byte
解决方法:decode('utf-8','ignore')
6.int 型变量 index 转 str类型---->str(index)
相反:str类型变量 string 转int类型 -----> int(str) --------10进制下
7.显示下载进度
def Schedule(a,b,c):
per = 100.0 * a * b / c
if per>100:
per = 100
print('完成!')
print('%.2f%%' % per)
urlretrieve(fileUrl,fileName,Schedule)
效果如下:

8记录一个爬网址图片,然后创建文件夹存图片的操作
# coding:utf-8 import requests from bs4 import BeautifulSoup import os # 创建一个文件夹名称 FileName = 'mm' def dd(): if not os.path.exists(os.path.join(os.getcwd(), FileName)): # 新建文件夹 os.mkdir(os.path.join(os.getcwd(),FileName)) print(u'建了一个名字叫做', FileName, u'的文件夹!') else: print(u'名字叫做', FileName, u'的文件夹已经存在了!') url = 'http://www.xiaohuar.com/list-1-1.html' html = requests.get(url).content # 返回html # html = html.decode('utf-8') soup = BeautifulSoup(html,'html.parser') # BeautifulSoup对象 jpg_data = soup.find_all('img',width="210") # 找到图片信息 index = 1 for i in jpg_data: deindex = str(index) + "a" data = i['src'] # 图片的URL print("图片url为"+data) if "https://www.dxsabc.com/" not in data: data = 'http://www.xiaohuar.com'+data r2 = requests.get(data) fpath = os.path.join(FileName,deindex) with open(fpath+'.jpg','wb+')as f : # 循环写入图片 f.write(r2.content) index += 1 print('保存成功,快去查看图片吧!!') if __name__== '__main__': dd()
9记录一个爬网址的shtml下的文章,然后创建文件夹存文件的操作
1)
我要判断获取到的<a>标签内是否含有 'shtml'
result = string.find(a_data,shtml)!=-1
if result:
#包含
else:
#不包含
module 'string' has no attribute 'find'
因为python版本升级,函数名称已有改变!只需要将string改为str即可!
2)逻辑是找到网址中的所有<a>标签,再取所有的href值,经判断后,取合适的链接
再通过循环获取链接内的属性,找自己想要的资源
3)can only concatenate str (not "int") to str

int类型和str类型不能拼接,所以需要转一下index的类型:str(index)
4) 以下是其中一个生成的文本截图,正文有了,但是调取接口却传不过去数据,导致校验返回为:缺少必填字段,
debug找到原因,是因为我在读取文件的时候,写入流还在一个线程没结束,文本是空的。我需要先走完写,再去读,才可以读到文件。
是由于读取流和写入流在同一个线程里,执行的先后顺序不一样。赶时间,我先分为2个进程去做。线程问题先不考虑,毕竟只是试验,
接下来学习下python的多线程,再搞。

5) 在陆续解决一些小问题后;终于出点成绩
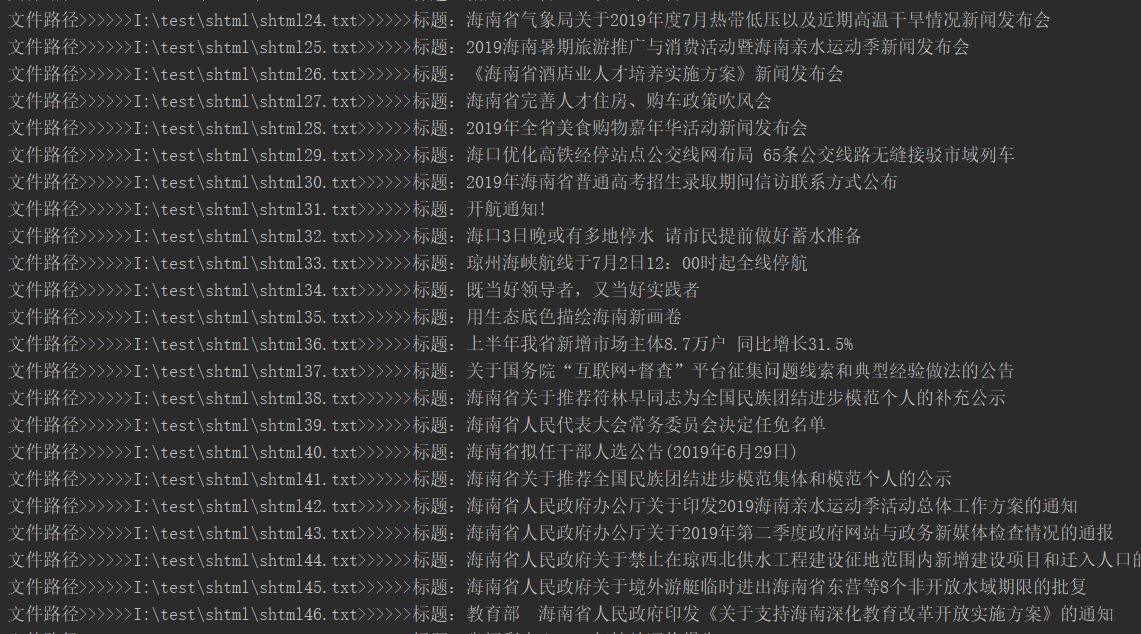
可惜的是在运行到第115的时候, 程序报错:
urllib3.exceptions.MaxRetryError: HTTPConnectionPool
接下来处理一下这个问题
6) urllib3.exceptions.MaxRetryError: HTTPConnectionPool
查了一下,发现我在拼接shtml链接逻辑的时候,判断有点问题,导致http://重复,肯定访问不到了。然后就不报错了
7),上整体代码。一共4个文件,其中有些是我调试用的代码,主要调取逻辑在mainTODO.py,刚刚练手,一些逻辑很笨拙,
代码不能拿走用,因为适配性并不好。一些标签是我要用的网站特有的。以后有类似问题,可以参考思路。
checkshtml.py
# coding:utf-8
import requests
from bs4 import BeautifulSoup
import os
import checkwebsite
import string
# 创建一个文件夹名称
FilePath = 'I:\test\'
FileName = 'xhtml'
def dd(url):
if not os.path.exists(os.path.join(os.getcwd(), FileName)): # 新建文件夹
os.mkdir(os.path.join(os.getcwd(),FileName))
print(u'建了一个名字叫做', FileName, u'的文件夹!')
else:
print(u'名字叫做', FileName, u'的文件夹已经存在了!')
html = requests.get(url).content # 返回html
# html = html.decode('utf-8')
soup = BeautifulSoup(html,'html.parser') # BeautifulSoup对象
# jpg_data = soup.find_all(r'href="(*.+?.shtml)"') # 找到shtml
a_datalist = soup.find_all('a') # 找到a标签
index = 1
datalist = []
for a_data in a_datalist:
result = a_data.get('href')
if not (result is None):
# str1=Hello.python
# print str1[:str1.index(str2)] #获取 "."之前的字符(不包含点) 结果 Hello
# print str1[str1.index(str2):] ; #获取 "."之后的字符(包含点) 结果.python
if "http://www.hainan.gov.cn/" not in result:
if "http://www"not in result:
result = 'http://www.hainan.gov.cn'+result
datalist.append(result)
return datalist
# print(index)
# index += 1
checkwebsite.py
# coding:utf-8
import requests
from bs4 import BeautifulSoup
import codecs
import urllib
from html5lib import HTMLParser
import os
def checkTitle(soup):
divtitle = soup.find_all('ucaptitle')
strtitle = str(divtitle)
if 'ucaptitle' in strtitle:
strtitle = strtitle[:strtitle.index("</ucaptitle>")]
strtitle = strtitle[::-1]
strtitle = strtitle[:strtitle.index(">eltitpacu")]
strtitle = strtitle[::-1]
# print(strtitle)
return str(strtitle)
else:
return ''
def checkContent(soup):
uuuu = ''
divlist = soup.find_all('ucapcontent')
for pfont in divlist:#遍历div的所有属性以及其值
p = pfont.find_all('p')
for pp in p:
start_pp = str(pp)
p_start_pp = start_pp[:start_pp.index("</p>")]
p_start_pp = p_start_pp[p_start_pp.index('>'):]
result = p_start_pp[::-1]
result = result[:result.index(">")]
result = result[::-1]
#w 只能操作写入 r 只能读取 a 向文件追加
#w+ 可读可写 r+可读可写 a+可读可追加
#wb+写入进制数据
#w模式打开文件,如果而文件中有数据,再次写入内容,会把原来的覆盖掉
uuuu = uuuu+str(result+'
')
return uuuu
# return result
def writeTxt(result):
f = codecs.open('I:\data.txt','a','utf-8')
f.write(str(result))
f.close()
if __name__== '__main__':
sHtmlUrl = "http://www.hainan.gov.cn/hainan/hngs/201906/c0a08f5b5a7e42b2bab66212de76b050.shtml"
html = requests.get(sHtmlUrl).content
soup = BeautifulSoup(html,'html.parser')
# writeTxt(checkTitle(soup))
writeTxt(checkContent(soup))
## 这个执行文件,是为了把所有的目标文章都爬进本地的txt文件里。
## 待下一个文件,去读取本地文章,再去调取远程post服务,把摘要写进去到txt文件,只需要分析txt文件即可
readFIleAndPost.py
import codecs
import requests
import json
import checkwebsite
import time
fileUrl = 'I:\data.txt'
def two(fileUrl):
num = 0
f = codecs.open(fileUrl,'r','utf-8')
string=''
for l in f:
tup = l.rstrip('
').rstrip()
# print(tup)
string += tup
num = num+1
# print (str)
# post 请求
url = 'http://localhost:8080/documentNew/parserNew'
s = json.dumps({'content': string, 'keywordCount': '5','summarySize':'2'})
try:
r = requests.post(url, s)
except:
print( u'[%s] HTTP请求失败!!!正在准备重发。。。')
time.sleep(2)
r = requests.post(url, s)
resultStr = str(r.text)
r.close()
return resultStr
if __name__ == '__main__':
checkwebsite.writeTxt(two(fileUrl))
mainTODO.py
import checkshtml
import checkwebsite
import readFIleAndPost
import requests
import os
import shutil
from bs4 import BeautifulSoup
import codecs
url = 'http://www.hainan.gov.cn/hainan/'
filePath = 'I:\testshtml\'
updateFilePath = 'I:\test\xhtml\'
def downLoadFile(url):
# 先拿取 目标网站的 href属性 对象数组
resultlist = checkshtml.dd(url)
shtmllist = []
# 取出 所需的shtml 对象数组
for list in resultlist:
if "shtml" in list:
shtmllist.append(list)
index = 1
#循环目标对象数组,分别取里面所需要的文本信息
for shtml in shtmllist:
# shtml = "http://www.hainan.gov.cn/hainan/hngs/201906/c0a08f5b5a7e42b2bab66212de76b050.shtml"
# shtml = "http://www.hainan.gov.cn/hainan/index.shtml"
html = requests.get(shtml).content
soup = BeautifulSoup(html,'html.parser')
urlpath = filePath+'shtml'+str(index)+'.txt'
updateurl = updateFilePath+'shtml'+str(index)+'.txt'
# 拿到文本对应的 标题和正文信息
strtitle = checkwebsite.checkTitle(soup).strip()
strcontent = checkwebsite.checkContent(soup)
if not (strcontent=='') :
f1 = codecs.open(urlpath,'w','utf-8')
f2 = codecs.open(updateurl,'w','utf-8')
# 新建并打开一个文本,写入标题
f1.write(strtitle+'
')
f2.write(strtitle+'
')
print("源文件路径>>>>>>"+urlpath+">>>>>>标题:"+strtitle)
print("修改文件路径>>>>>>"+updateurl+">>>>>>标题:"+strtitle)
# 循环调取 checkwebsite.checkContent() 写入正文。
f1.write(strcontent)
f2.write(strcontent)
# 关闭文件流
index += 1
f1.close()
f2.close()
# 开启下一个链接的处理
def updateFile():
file_name = os.listdir(updateFilePath)
for file in file_name:
#获取到 接口返回值
response = readFIleAndPost.two(updateFilePath+file)
f = codecs.open(updateFilePath+file,'a','utf-8')
f.write(response)
f.close()
def deleteAndCopyFile():
del_file(updateFilePath)
f_list = os.listdir(filePath)
n=0
for fileNAME in f_list:
n += 1
oldname = filePath + fileNAME
newname = updateFilePath + fileNAME
shutil.copyfile(oldname, newname)
# print(str(n)+'.'+'已复制'+fileNAME)
def del_file(path):
for i in os.listdir(path):
path_file = os.path.join(path,i)
if os.path.isfile(path_file):
os.remove(path_file)
else:
del_file(path_file)
if __name__== '__main__':
# 下载 2份文档到本地,运行一次,即可注释
# downLoadFile(url)
# 直接修改初始化的其中一份文本
# updateFile()
# 删除已有的样本,取源文件,先copy一份,再发post filePath源路径
deleteAndCopyFile()
updateFile()
10、取字典里的数据
[{'name': '张三', 'phone': '185185', 'wechat': '6546231'}, {'name': '李四', 'phone': '187169', 'wechat': 'asdsad'}]
这个版本里:
for studeht in self.studehts :
#错误
name=studeht .get["name"]
#正确取法
name=studeht["name"]