以前的知识还给老师了,现在不用就忘得差不多了。
主要是我想复习和回顾一下程序函数栈的执行过程,还有各项地址指针的对应关系,给自己注入一点信心,口说无凭就很弱气 XD 。
函数调用栈图例
我就不解释一些基础性的知识了,毕竟我只是给自己做个笔记用的。
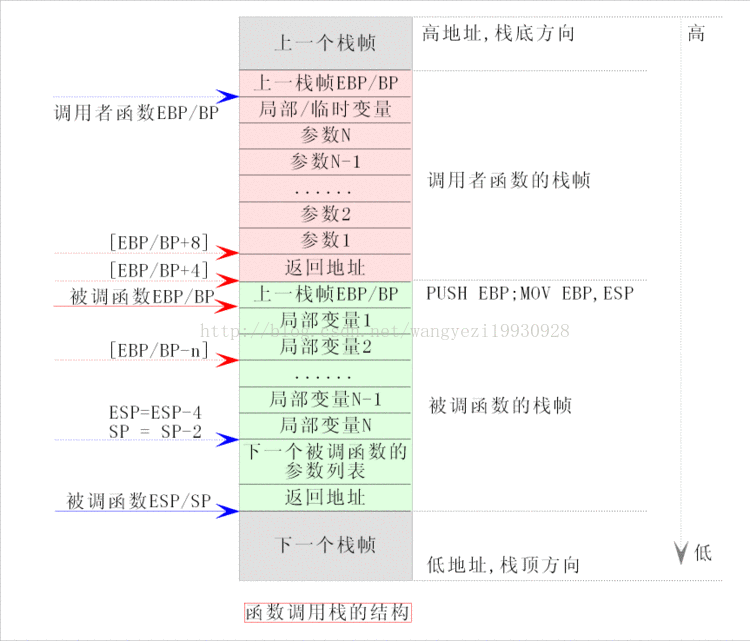
栈: 在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
当发生函数调用的时候,栈空间中存放的数据是这样的:
1、调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中,即:从右向左依次把被调函数所需要的参数压入栈;
2、调用者函数使用call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中(这个压栈操作隐含在call指令中);
3、在被调函数中,被调函数会先保存调用者函数的栈底地址(push ebp),然后再保存调用者函数的栈顶地址,即:当前被调函数的栈底地址(mov ebp,esp);
4、在被调函数中,从ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小,即:这些变量的地址是按照栈的延伸方向排列的,先定义的变量先入栈,后定义的变量后入栈;
引用 函数调用栈 剖析+图解
确认了栈的加载的顺序和内容,有些栈会进行对齐,只是为了方便访问时的固定偏移量,没有特别的用意。
ESP、EBP 寄存器
esp是栈指针,是cpu机制决定的,push、pop指令会自动调整esp的值;
ebp只是存取某时刻的esp,这个时刻就是进入一个函数内后,cpu会将esp的值赋给ebp,此时就可以通过ebp对栈进行操作,比如获取函数参数,局部变量等,实际上使用esp也可以;
那么ESP和EBP指的分别是什么呢?
(1)ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
(2)EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
因为esp在函数运行时会不断的变化,所以保存一个一进入某个函数的 esp 到 ebp 中会方便程序员访问参数和局部变量,而且还方便调试器分析函数调用过程中的堆栈情况。前面说了,这个ebp不是必须要有的,你非要使用esp来访问函数参数和局部变量也是可行的,只不过这样会麻烦一些。
ESP 专门用作堆栈指针,被形象地称为栈顶指针,堆栈的顶部是地址小的区域,压入堆栈的数据越多,ESP也就越来越小。在32位平台上,ESP每次减少4字节。
关于这些复习的资料就不讲了,仔细阅读这一份就足够了 栈指针&& 帧指针详解
调试确认栈的工作情况
确认压栈的工作流程,以调用 x86 的 test(1); 为例,这表示要传入一个 test 返回地址(ra) 和 一个 int(4 byte)的参数。

所以可以看到 esp 指针从 0x0115fa08 - 8 = 0x0115fa00 ,这表示压栈的过程符合预期,接下来还会将 ebp push 压入,退出前会 pop 出,这里先讨论函数压栈的过程,继续以 两个形参 的函数为参考。
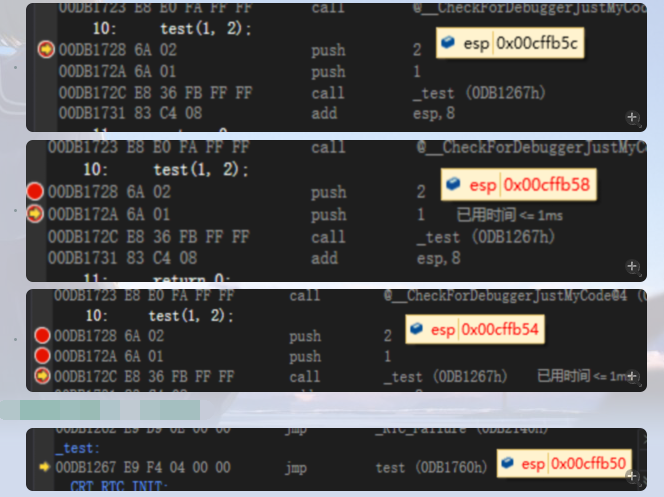
其中 call 实际上包含了将函数指针地址压入的过程,所以导致了减少 4 字节,同时调用参数从后往前压入,这也符合预期。
需要注意的是 DEBUG 模式下,有内存检测和栈检测的操作,如 增加的 esp 地址,在最后回退回来。
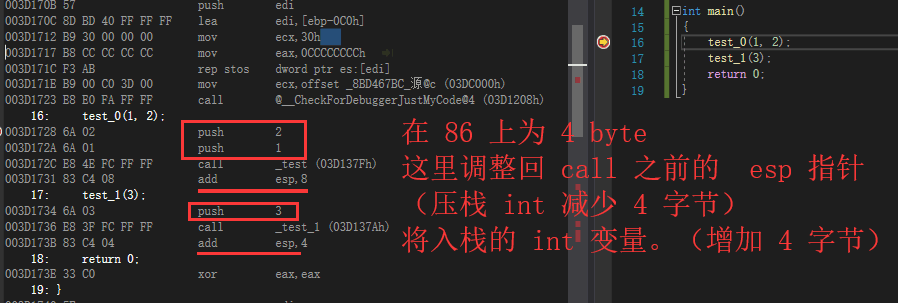
这里我们略过,直接看到函数调用的地方,确认回归到进入前的 esp 寄存器值,流程如下。

至此确认了函数递归流程 CALL 和 RET 符合预期,接着在函数体中运行,我们忽略正文的内容,直接看到 压栈 + 正文 + 出栈 的过程,这期间可以通过 ret 跳转回 call 的位置。
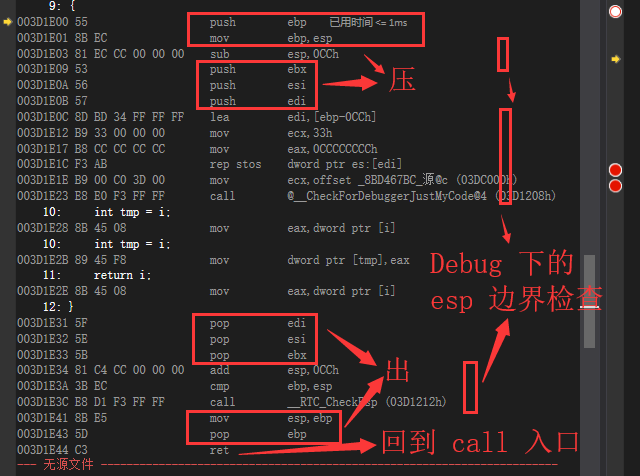
确认了函数体中的 ebp 和 esp 寄存器的备份与还原,忽略那个边界检查,这个主要是用来发现指针误操作的情况的。
关于 x86 上的 nlr 的实现问题
事实上,这里刚好可以提到 nlr 的实现问题,它实际上就是将 当前的堆栈入口 nlr_push 记录下来,然后过后再 nlr_jump 还原回去,这样当前的执行就会退回到记录的节点继续执行了。

但这里的操作都没有办法直接控制芯片的执行,我们只能通过交换寄存器内容来完成对程序的执行,这与我后来学习的 mips 指令有一些不太一样,包括 riscv 也一样。
例如 mips 是这样的控制函数栈的,https://www.cs.purdue.edu/homes/hosking/502/spim/node23.html。
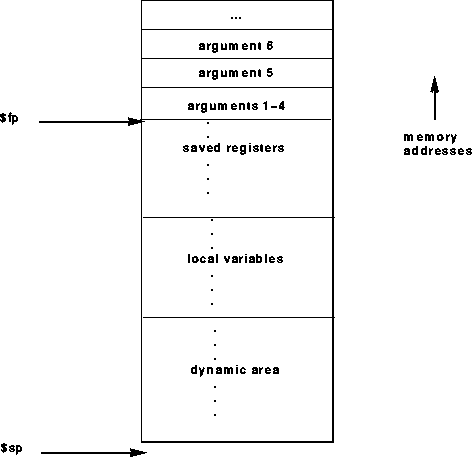
原文:

传递参数的方式采用的是 批量的 a[] 寄存器组,返回地址存储在 ra 寄存器,栈指针存储在 $sp 寄存器,这与我上面所提及的内容是有一些出入的,但整体的设计思想是相通的。
事实上结果大同小异,只是 X86 的指令集似乎有意隐瞒了 call 和 ret 指令的实现。
后记
以前在校的时候接触的都是 x86 指令集,现在开始玩起了嵌入式软件,或多或少都要被迫实践一些,虽然说在工作中,知道还是不知道都不影响你写出一手漂亮的逻辑,但真的出现了什么特殊情况,如果不知道这些底层的情况,就很难控制一些特殊异常错误,例如除法溢出的标记量检查,不在 asm 怎么可能访问得了除法器的 flag 寄存器呢?
以及一些指针异常的特殊情况,懂得这些可以有利于你分析出真正错误的异常,假设没有反汇编也没有debug工具的时候,手工分析就是我们最好的朋友。