一、简介
Kafka 是最初由 Linkedin 公司开发,Linkedin 于2010年贡献给了 Apache 基金会并成为顶级开源项目,也是一个开源【分布式流处理平台】,由 Scala 和 Java 编写,(也当做 MQ 系统,但不是纯粹的消息系统)。一句话概括:Kafka 是一种高吞吐量的分布式流处理平台,它可以处理消费者在网站中的所有动作流数据。比如网页浏览,搜索和其他用户的行为等,应用于大数据实时处理领域。
二、认识概念
Broker
- Kafka 的服务端程序,可以认为一个 mq 节点就是一个Broker
- Broker 存储 Topic 的数据
Producer 生产者
- 创建消息 Message,然后发布到 MQ 中
- 该角色将消息发布到 Kafka 的 Topic 中
Consumer 消费者
- 消费队列里面的消息
1、核心概念
ConsumerGroup 消费者组
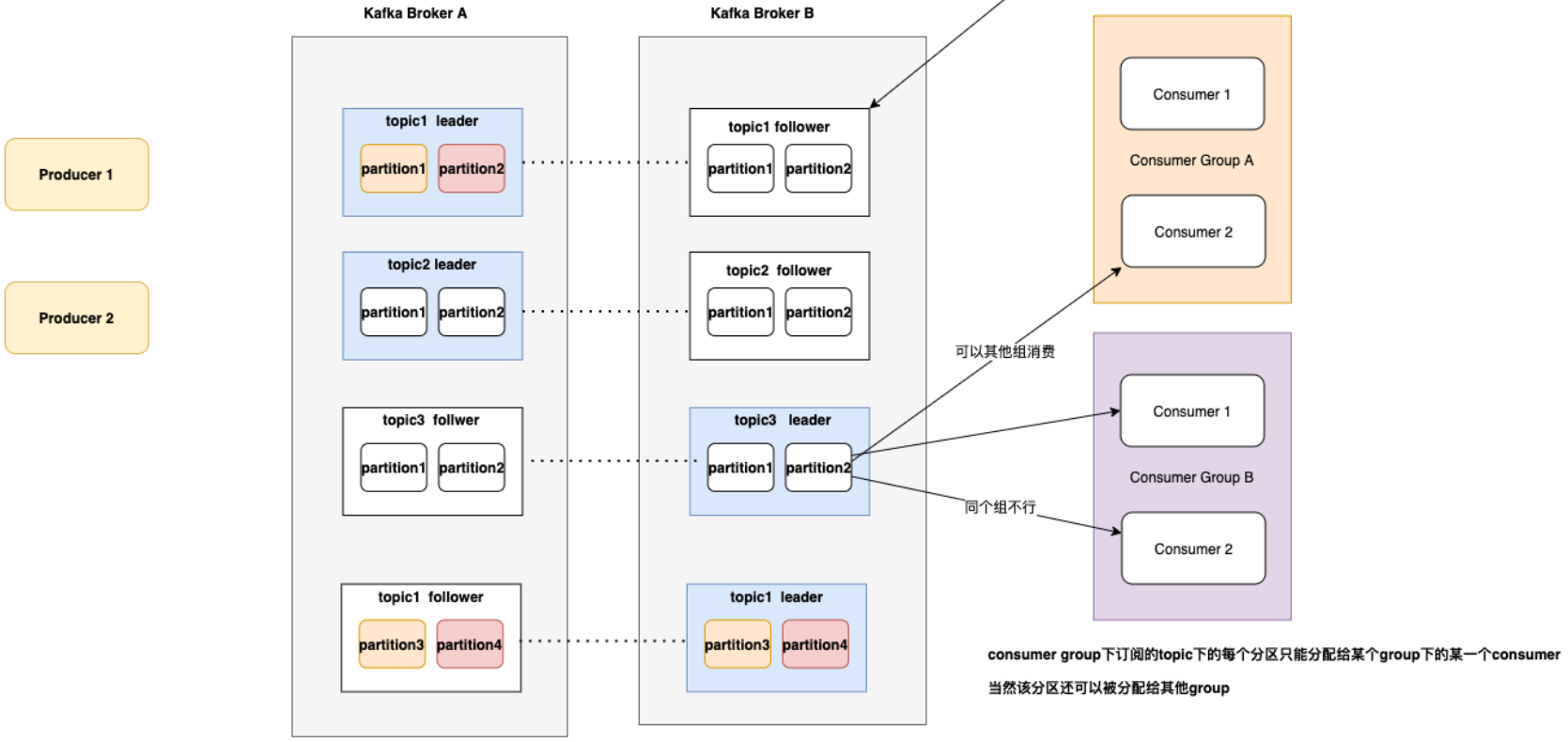
- 同个Topic,广播发送给不同的Group,一个 Group 中只有一个 Consumer 可以消费此消息
Topic
- 每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为Topic,主题的意思
Partition 分区
- Kafka 数据存储的基本单元,Topic 中的数据分割为一个或多个Partition,每个 Topic 至少有一个Partition,是有序的
- 一个 Topic 的多个Partitions,被分布在 Kafka 集群中的多个 Server 上
- 消费者数量 <=小于或者等于 Partition 数量
Replication 副本(备胎)
- 同个 Partition 会有多个副本Replication ,多个副本的数据是一样的,当其他 Broker 挂掉后,系统可以主动用副本提供服务
- 默认每个 Topic 的副本都是1(默认是没有副本,节省资源),也可以在创建 Topic 的时候指定
- 如果当前 Kafka 集群只有3个 Broker 节点,则 Replication-Factor 最大就是3了,如果创建副本为4,则会报错
ReplicationLeader、ReplicationFollower
- Partition 有多个副本,但只有一个 ReplicationLeader 负责该 Partition 和生产者消费者交互
- ReplicationFollower 只是做一个备份,从 ReplicationLeader 进行同步
ReplicationManager
- 负责 Broker 所有分区副本信息,Replication 副本状态切换
Offset
- 每个 Consumer 实例需要为他消费的 Partition 维护一个记录自己消费到哪里的偏移Offset
- Kafka 把 Offset 保存在消费端的消费者组里


2、特点总结
- 多订阅者
- 一个 Topic 可以有一个或者多个订阅者
- 每个订阅者都要有一个Partition,所以订阅者数量要少于等于 Partition 数量
- 高吞吐量、低延迟: 每秒可以处理几十万条消息
- 高并发:几千个客户端同时读写
- 容错性:多副本、多分区,允许集群中节点失败,如果副本数据量为n,则可以n-1个节点失败
- 扩展性强:支持热扩展
3、基于消费者组可以实现
- 基于队列的模型:所有消费者都在同一消费者组里,每条消息只会被一个消费者处理
- 基于发布订阅模型:消费者属于不同的消费者组,假如每个消费者都有自己的消费者组,这样 Kafka 消息就能广播到所有消费者实例上
三、安装 Zookeeper
步骤一:下载安装包并解压

步骤二:复制配置文件
将 zoo_sample.cfg 复制一份并命名为 zoo.cfg

步骤三:启动
进入 bin 目录,使用命令启动
./zkServer.sh start
默认2181端口
默认配置文件 zoo.cfg
四、安装Kafka
步骤一:下载安装包并解压
步骤二:修改server.properties
#标识broker编号,集群中有多个broker,则每个broker的编号需要设置不同 broker.id=0 #修改下面两个配置(listeners 配置的ip和advertised.listeners相同时启动kafka会报错) listeners(内网Ip) advertised.listeners(公网ip) #修改zk地址,默认地址,因为zookeeper和kafka部署在一起,可以这样,否则需要具体的IP zookeeper.connection=localhost:2181
默认端口是 9092 端口
步骤三:启动
进入 bin 目录
#启动 ./kafka-server-start.sh ../config/server.properties & #启动:守护进程方式 ./kafka-server-start.sh -daemon ../config/server.properties & #停止 kafka-server-stop.sh
五、命令行生产者发送消息和消费者消费消息实战
1、创建topic
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic xdclass-topic
2、查看topic
./kafka-topics.sh --list --zookeeper 112.74.55.160:2181
3、生产者发送消息
./kafka-console-producer.sh --broker-list 112.74.55.160:9092 --topic version1-topic
4、消费者消费消息
--from-beginning:会把主题中以往所有的数据都读取出来, 重启后会有这个重复消费,实际上不加 ./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1
5、删除topic
./kafka-topics.sh --zookeeper 112.74.55.160:2181 --delete --topic t1
6、查看broker节点topic状态信息
./kafka-topics.sh --describe --zookeeper 112.74.55.160:2181 --topic xdclass-topic
六、实现点对点消费
步骤一:编辑消费者配置
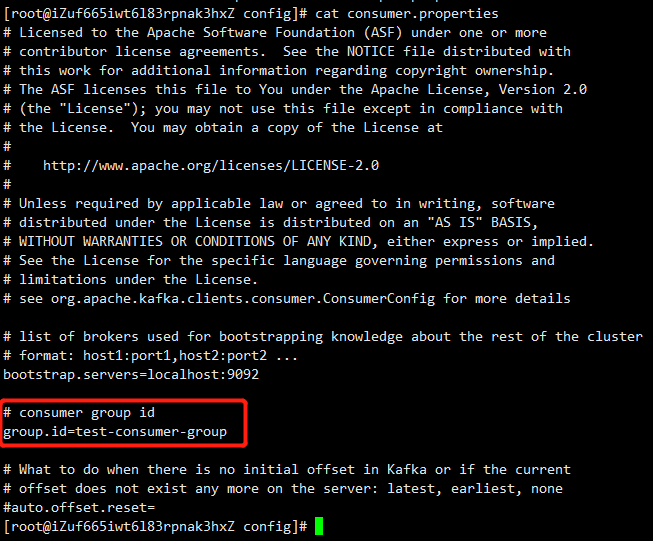
确保同个名称 group.id 一样,这里我们使用默认的就可以了,当然也可以改成自己喜欢的名称,编辑config/consumer.properties,
步骤二:启动两个消费者试验
#创建topic, 1个分区 ./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic t1 #下面的命令用两个窗口运行,指定配置文件启动两个消费者 ./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer.properties
只有一个消费者可以消费到数据,一个分区只能被同个消费者组下的某个消费者进行消费
七、实现发布订阅消费
步骤一:编辑消费者配置
确保group.id 不一样
- 编辑 config/consumer-1.properties
- 编辑 config/consumer-2.properties


步骤二:启动两个消费者试验
#创建topic, 2个分区 ./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic t2 #指定配置文件启动两个消费者 ./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer-1.properties ./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer-2.properties
两个不同消费者组的节点,都可以消费到消息,实现发布订阅模型
八、Kafka 数据存储流程、原理、LEO+HW讲解
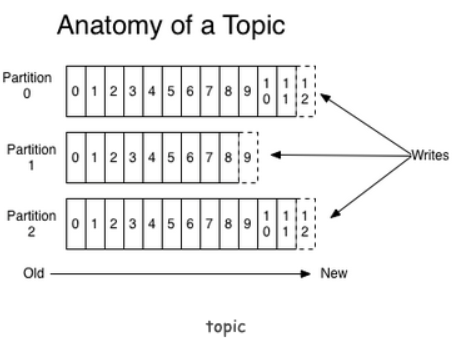
Partition
- Topic 物理上的分组,一个 Topic 可以分为多个Partition,每个 Partition 是一个有序的队列
- 是以文件夹的形式存储在具体 Broker 本机上
LEO(LogEndOffset)
- 表示每个 Partition 的 log 最后一条 Message 的位置。
HW(HighWatermark)
- 表示 Partition 各个 Replicas 数据间同步且一致的 offset 位置,即表示 allreplicas 已经 commit 的位置
- HW 之前的数据才是 Commit 后的,对消费者才可见
- ISR 集合里面最小leo

offset
- 每个 Partition 都由一系列有序的、不可变的消息组成,这些消息被连续的追加到 Partition 中
- Partition 中的每个消息都有一个连续的序列号叫做offset,用于 Partition 唯一标识一条消息
- 可以认为 offset 是 Partition 中 Message 的 id
Segment:每个 Partition 又由多个 segment file 组成;
- segment file 由2部分组成,分别为 index file 和 data file(log file),
- 两个文件是一一对应的,后缀“.index”和“.log”分别表示索引文件和数据文件
- 命名规则:Partition 的第一个 segment 从0开始,后续每个 segment 文件名为上一个 segment 文件最后一条消息的offset+1
Kafka 高效文件存储设计特点:
- Kafka 把 Topic 中一个 Parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message
- Producer 生产数据,要写入到 log 文件中,写的过程中一直追加到文件末尾,为顺序写,官网数据表明。同样的磁盘,顺序写能到600M/S,而随机写只有100K/S