1 自动化测试模型
1.1 数据驱动测试实例
调用的类
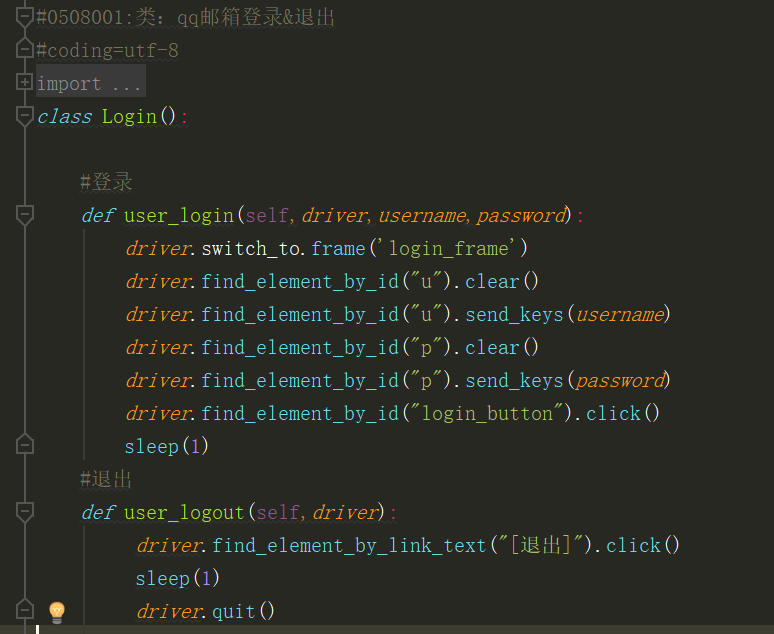
login.py
#0508001:类:qq邮箱登录&退出
#coding=utf-8
from selenium import webdriver
from time import sleep
class Login():
#登录
def user_login(self,driver,username,password):
driver.switch_to.frame('login_frame')
driver.find_element_by_id("u").clear()
driver.find_element_by_id("u").send_keys(username)
driver.find_element_by_id("p").clear()
driver.find_element_by_id("p").send_keys(password)
driver.find_element_by_id("login_button").click()
sleep(1)
#退出
def user_logout(self,driver):
driver.find_element_by_link_text("[退出]").click()
sleep(1)
driver.quit()
1.1.1 参数化邮箱登录
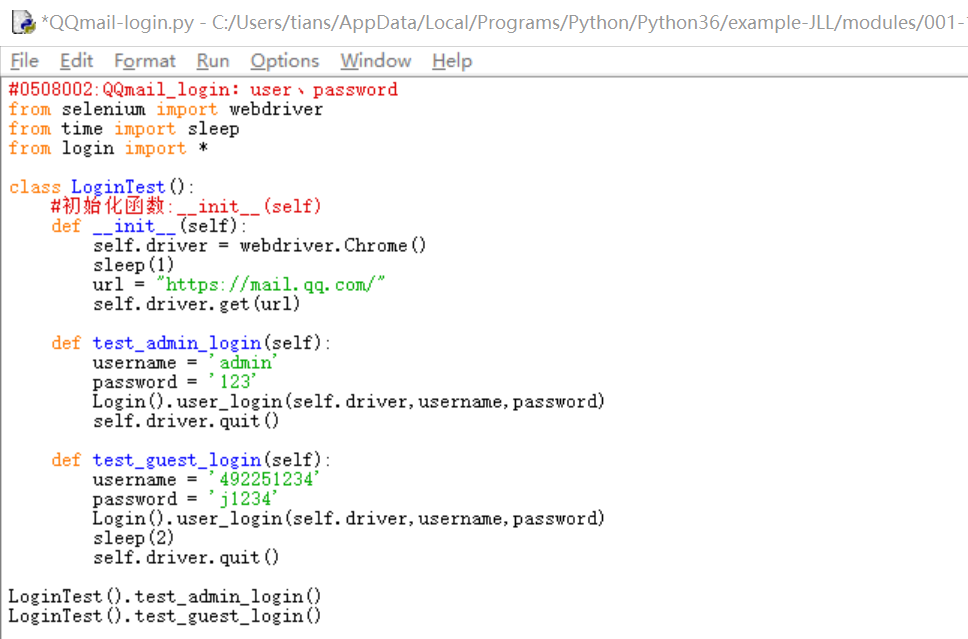
QQmail-login.py
#0508002:QQmail_login:user、password from selenium import webdriver from time import sleep from login import * class LoginTest(): #初始化函数:__init__(self) def __init__(self): self.driver = webdriver.Chrome() sleep(1) url = "https://mail.qq.com/" self.driver.get(url) def test_admin_login(self): username = 'admin' password = '123' Login().user_login(self.driver,username,password) self.driver.quit() def test_guest_login(self): username = '492251234' password = 'j1234' Login().user_login(self.driver,username,password) sleep(2) self.driver.quit() LoginTest().test_admin_login() LoginTest().test_guest_login()
1.1.1 参数化搜索关键字
可将参数放在一个数组,通过循环遍历数组,搜索。
如:text = [‘a’, ‘b’ ‘c’]
For I in text:
…………
1.1.2 读取txt文件

Python 提供了以下几种读取txt文件的方式。
l read() 读取整个文件。
l readline() 读取一行数据。
l readlines() 读取所有行的数据。

#0516003:QQmail_login:user、password from txt from selenium import webdriver from time import sleep from login import * class LoginTest(): #初始化函数:__init__(self) def __init__(self): self.driver = webdriver.Chrome() sleep(1) url = "https://mail.qq.com/" self.driver.get(url) def test_admin_login(self): print(username,password) Login().user_login(self.driver,username,password) sleep(3) self.driver.quit() user_file = open('users.txt','r') lines = user_file.readlines() user_file.close() for line in lines: username = line.split(',')[0] password = line.split(',')[1] LoginTest().test_admin_login()
1.1.3 读取csv文件
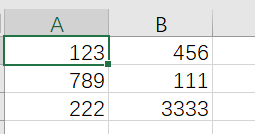
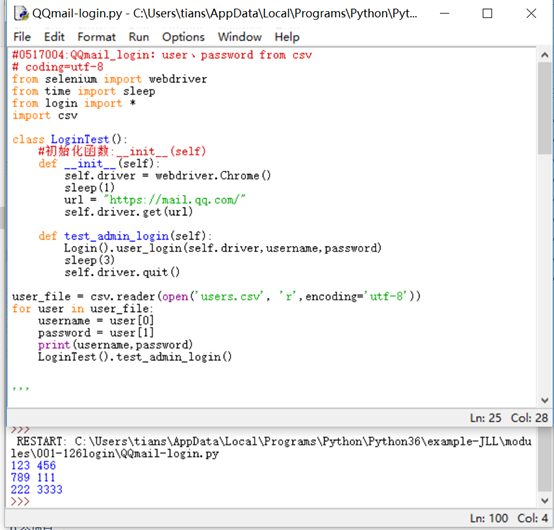
#0517004:QQmail_login:user、password from csv # coding=utf-8 from selenium import webdriver from time import sleep from login import * import csv class LoginTest(): #初始化函数:__init__(self) def __init__(self): self.driver = webdriver.Chrome() sleep(1) url = "https://mail.qq.com/" self.driver.get(url) def test_admin_login(self): Login().user_login(self.driver,username,password) sleep(3) self.driver.quit() user_file = csv.reader(open('users.csv', 'r',encoding='utf-8')) for user in user_file: username = user[0] password = user[1] print(username,password) LoginTest().test_admin_login()
1.1.4 读取xml文件

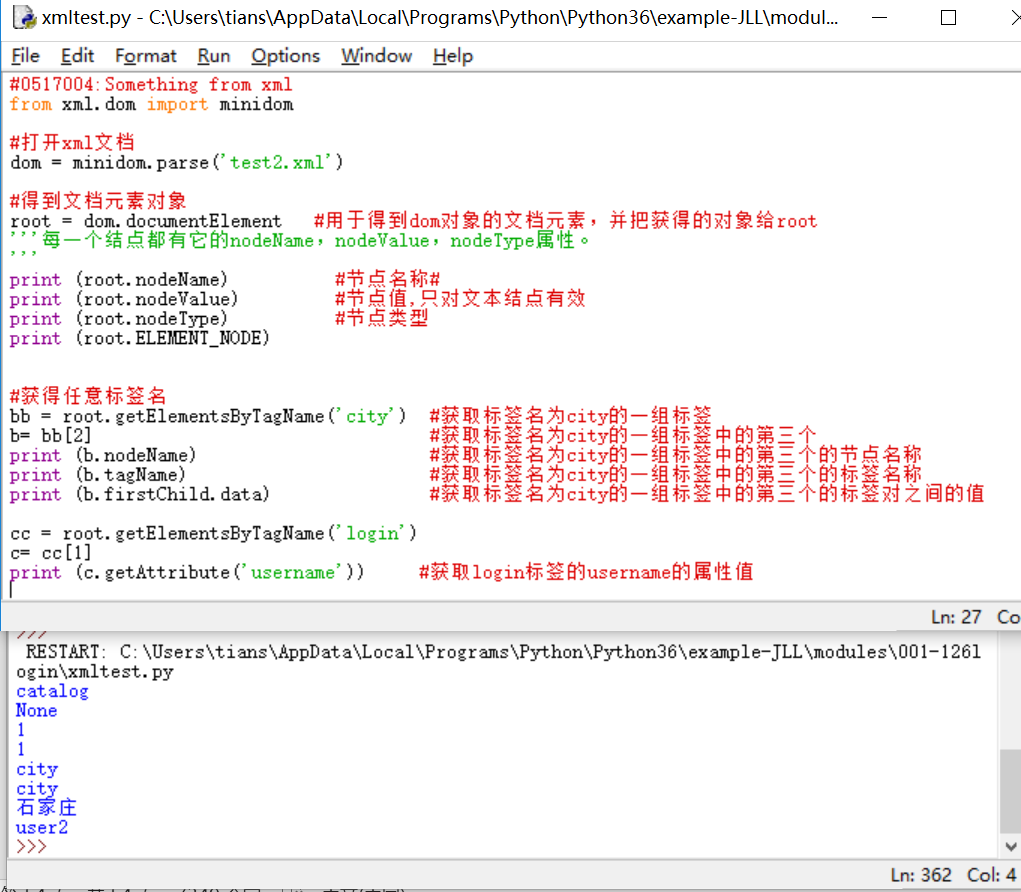
#0517004:Something from xml from xml.dom import minidom #打开xml文档 dom = minidom.parse('test2.xml') #得到文档元素对象 root = dom.documentElement #用于得到dom对象的文档元素,并把获得的对象给root '''每一个结点都有它的nodeName,nodeValue,nodeType属性。 ''' print (root.nodeName) #节点名称# print (root.nodeValue) #节点值,只对文本结点有效 print (root.nodeType) #节点类型 print (root.ELEMENT_NODE) #获得任意标签名 bb = root.getElementsByTagName('city') #获取标签名为city的一组标签 b= bb[2] #获取标签名为city的一组标签中的第三个 print (b.nodeName) #获取标签名为city的一组标签中的第三个的节点名称 print (b.tagName) #获取标签名为city的一组标签中的第三个的标签名称 print (b.firstChild.data) #获取标签名为city的一组标签中的第三个的标签对之间的值 cc = root.getElementsByTagName('login') c= cc[1] print (c.getAttribute('username')) #获取login标签的username的属性值