1.大数据计算服务(Maxcompute,原名ODPS)
MaxCompute is a big data processing platform developed by Alibaba Cloud independently. It is a fast and cloud-based big data solution that supports multiple distributed data storage and processing models, which can provide massive data warehouse and big data modeling service.
MaxCompute Studio is a plugin for IntelliJ platform allowing data developers works with MaxCompute platform including authoring SQL scripts, UDF extensions, MapReduce programs and other functions like local debugging, data browsing and uploading/downloading, job browsing and analytics, etc.
Features include:
MaxCompute SQL language support
MaxCompute function development
MaxCompute data management
MaxCompute job management
分布式的计算模型对数据分析人员要求较高且不易维护。数据分析人员不仅需要了解业务需求,同时还需要熟悉底层分布式计算模型。MaxCompute为您提供完善的数据导入方案以及多种经典的分布式计算模型,您可以不必关心分布式计算和维护细节,便可轻松完成大数据分析。
DataWorks和MaxCompute关系紧密:DataWorks为MaxCompute提供一站式的数据同步、业务流程设计、数据开发、管理和运维功能。
产品优势
- 大规模计算存储
MaxCompute适用于100GB以上规模的存储及计算需求,最大可达EB级别。
- 多种计算模型
MaxCompute支持SQL、MapReduce、UDF(Java/Python)、Graph、基于DAG的处理、交互式、内存计算、机器学习等计算类型及MPI迭代类算法。简化了企业大数据平台的应用架构。
- 强数据安全
MaxCompute已稳定支撑阿里全部数据仓库业务9年以上,提供多层沙箱防护、细粒度权限管理及监控。
- 低成本
与企业自建专有云相比,MaxCompute的计算存储更高效,可以降低30%~50%的采购成本。
- 免运维
基于MaxCompute的Serverless无服务器的设计思路,用户只需关心作业和数据,而无需关心底层分布式架构及运维。
- 极致弹性扩展
MaxCompute提供按量付费模式下的作业级别的资源管理。用户无需受困于资源扩展难题,系统会自动扩展计算、存储、网络等资源,最大程度地节省成本。
maxcompute系统架构
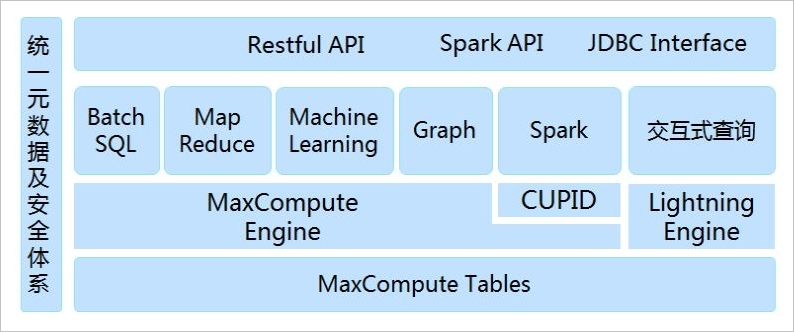
功能:
数据通道
-
TUNNEL是MaxCompute为您提供的数据传输服务,提供高并发的离线数据上传下载服务。支持每天TB/PB级别的数据导入导出,特别适合于全量数据或历史数据的批量导入。Tunnel为您提供Java编程接口,并且在MaxCompute的客户端工具中,提供对应的命令实现本地文件与服务数据的互通。
-
针对实时数据上传的场景,MaxCompute提供了延迟低、使用方便的DataHub服务,特别适用于增量数据的导入。DataHub还支持多种数据传输插件,例如Logstash、Flume、Fluentd、Sqoop等,同时支持日志服务Log Service中的投递日志到MaxCompute,进而使用DataWorks进行日志分析和挖掘。
- 计算及分析任务
MaxCompute支持多种计算模型,详情如下:
- SQL:MaxCompute以表的形式存储数据,支持多种数据类型,并对外提供SQL查询功能。您可以将MaxCompute作为传统的数据库软件操作,但其却能处理TB、PB级别的海量数据。
说明
- MaxCompute SQL不支持事务、索引,也不支持Update或Delete操作。
- MaxCompute的SQL语法与Oracle、MySQL有一定差别,您无法将其他数据库中的SQL语句无缝迁移至MaxCompute中。详情请参见与其他SQL语法的差异。
- MaxCompute主要用于100GB以上规模的数据计算,因此MaxCompute SQL最快支持在分钟或秒钟级别完成查询返回结果,但无法在毫秒级别返回结果。
- MaxCompute SQL的优点是学习成本低,您不需要了解复杂的分布式计算概念。如果您具备数据库操作经验,便可快速熟悉MaxCompute SQL的使用。
- UDF:即用户自定义函数。
MaxCompute提供了很多内建函数来满足您的计算需求,同时您还可以通过创建自定义函数来满足不同的计算需求。
- MapReduce:MaxCompute MapReduce是MaxCompute提供的Java MapReduce编程模型,它可以简化开发流程,更为高效。您若使用MaxCompute MapReduce,需要对分布式计算概念有基本了解,并有相对应的编程经验。MaxCompute MapReduce为您提供Java编程接口。
- Graph:MaxCompute提供的Graph功能是一套面向迭代的图计算处理框架。图计算作业使用图进行建模,图由点 (Vertex)和边(Edge)组成,点和边包含权值(Value)。通过迭代对图进行编辑、演化,最终求解出结果,典型应用:PageRank、单源最短距离算法 、K-均值聚类算法等。
- SQL:MaxCompute以表的形式存储数据,支持多种数据类型,并对外提供SQL查询功能。您可以将MaxCompute作为传统的数据库软件操作,但其却能处理TB、PB级别的海量数据。
- SDK
SDK是MaxCompute提供给开发者的工具包,当前支持Java SDK及Python SDK。
- 安全
MaxCompute提供了功能强大的安全服务,为您的数据安全提供保护,详情请参见安全指南。
参考资料:1.https://help.aliyun.com/document_detail/27800.html?spm=a2c4g.11186623.6.547.3ec77a55TkBUgk
MaxCompute与DataWorks
DataWorks是基于MaxCompute计算和存储,提供工作流可视化开发、调度运维托管的一站式海量数据离线加工分析平台。在数加(一站式大数据平台)中,DataWorks控制台即为MaxCompute控制台。
MaxCompute和DataWorks一起向用户提供完善的ETL和数仓管理能力,以及SQL、MR、Graph等多种经典的分布式计算模型,能够更快速地解决用户海量数据计算问题,有效降低企业成本,保障数据安全。更多使用说明请参见DataWorks什么是DataWorks。
说明 您可以将DataWorks理解成MaxCompute的一种Web客户端。MaxCompute是DataWorks的一种计算引擎。
MaxCompute与数据集成
MaxCompute可以通过数据集成加载不同数据源(例如:MySQL数据库等)数据,同样也可以通过数据集成把MaxCompute的数据导出到各种业务数据库。
数据集成功能已经集成到DataWorks作为数据同步任务进行配置、运行。您可直接在DataWorks上配置MaxCompute数据源,再配置读取MaxCompute表或者写入MaxCompute表任务,数据的导入和导出整个过程只需在一个平台上进行操作。
MaxCompute与机器学习PAI
机器学习PAI是基于MaxCompute的一款机器学习算法平台。它实现了数据无需搬迁,便可进行从数据处理、模型训练、服务部署到预测的一站式机器学习。创建MaxCompute项目,开通机器学习,即可通过机器学习平台的算法组件对MaxCompute数据进行模型训练等操作。详情请参见机器学习PAI操作文档。
MaxCompute与QuickBI
数据在MaxCompute进行加工处理后,将Project添加为QuickBI数据源,即可在QuickBI页面对MaxCompute表数据进行报表制作,实现数据可视化分析。
MaxCompute与AnalyticDB for MySQL
AnalyticDB for MySQL是海量数据实时高并发在线分析(Realtime OLAP)的云计算服务,与MaxCompute结合实现大数据驱动业务系统的场景。通过MaxCompute离线计算挖掘,产出高质量数据后,导入分析型数据库,供业务系统调用分析。
- 通过DMS for AnalyticDB for MySQL的导入导出功能进行配置。
- 通过DataWorks配置数据同步任务,配置MaxCompute Reader和配置AnalyticDB for MySQL 2.0 Writer。
......
MaxCompute的表格有两种类型:内部表和外部表(MaxCompute2.0版本开始支持外部表)。
- 对于内部表,所有的数据都被存储在MaxCompute中,表中列的数据类型可以是MaxCompute支持的任意一种数据类型。
- 对于外部表,MaxCompute并不真正持有数据,表格的数据可以存放在OSS或OTS中 。MaxCompute仅会记录表格的Meta信息,您可以通过MaxCompute的外部表机制处理OSS或OTS上的非结构化数据,例如视频、音频、基因、气象、地理信息等。
分区表是指在创建表时指定分区空间,即指定表内的一个或者某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立的文件夹,该文件夹下是该分区所有数据文件。而分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。分类的标准就是分区字段,可以是一个,也可以是多个。
分区表的意义在于优化查询。查询表时通过WHERE子句查询指定所需查询的分区,避免全表扫描,提高处理效率,降低计算费用。
参考资料:1.https://help.aliyun.com/document_detail/27820.html?spm=a2c4g.11186623.6.554.165939a4ucghb8
--创建一个二级分区表,以日期为一级分区,地域为二级分区
CREATE TABLE src (key string, value bigint) PARTITIONED BY (pt string,region string);
--正确使用方式。MaxCompute在生成查询计划时只会将'20170601'分区下region为'hangzhou'二级分区的数据纳入输入中。
select * from src where pt='20170601'and region='hangzhou';
--错误的使用方式。在这样的使用方式下,MaxCompute并不能保障分区过滤机制的有效性。pt是STRING类型,当STRING类型与BIGINT(20170601)比较时,MaxCompute会将二者转换为DOUBEL类型,此时有可能会有精度损失。
select * from src where pt = 20170601;
MaxCompute表的生命周期(Lifecycle),指表(分区)数据从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表(分区)将被MaxCompute自动回收。这个指定的时间就是生命周期。- 生命周期单位:Days(天),只接受正整数。
- 对于非分区表,如果表数据在生命周期Days天内没有被修改,经过Days天后此表将会被MaxCompute自动回收(类似
DROP TABLE操作)。生命周期从最后一次表数据被修改的时间(LastDataModifiedTime)起开始计算。 - 对于分区表,每个分区可以分别被回收。在生命周期Days天内数据未被修改的分区,经过指定的天数后此分区将会被回收,否则会被保留。每个分区的生命周期是从最后一次分区数据被修改的时间
LastDataModifiedTime起开始计算。不同于非分区表,分区表的最后一个分区被回收后,该表不会被删除。
- 生命周期只能设定到表级别,不能在分区级设置生命周期。创建表时即可指定生命周期。
- 如果您没有为表指定生命周期,则表(分区)不会根据生命周期规则被MaxCompute自动回收。
资源类型
- File类型。
- Table类型:MaxCompute中的表。
说明 MapReduce引用的table类型资源中,table字段类型目前只支持BIGINT、DOUBLE、STRING、DATETIME、BOOLEAN,其他类型暂未支持。
- Jar类型:编译好的Java Jar包。
- Archive类型:通过资源名称中的后缀识别压缩类型,支持的压缩文件类型包括.zip/.tgz/.tar.gz/.tar/jar。