特征识别反爬虫
我们可以将爬虫的爬取过程分为网络请求、文本获取和数据提取3个部分。
信息校验型反爬虫主要出现在网络请求阶段,这个阶段的反爬虫理念以预防为主要目的,尽可能拒绝爬虫程序的请求。
动态渲染和文本混淆则出现在文本获取及数据提取阶段,这个阶段的反爬虫理念以保护数据为主要目的,尽可能避免爬虫获得重要数据。
特征识别反爬虫是指通过客户端的特征、属性或用户行为特点来区分正常用户和爬虫程序的手段
本章我们要介绍的特征识别反爬虫也是以预防为主要目的,直指爬虫出现的源头。
接下来,我们一起学习特征识别反爬虫的原理和绕过技巧
WebDriver 识别
我们之前了解到,爬虫程序可以借助渲染工具从动态网页中获取数据。
“借助”其实是通过对应的浏览器驱动 (即 WebDriver) 向浏览器发出指令的行为。
也就是说,开发者可以根据客户端是否包含浏览器驱动这一特征来区分正常用户和爬虫程序
开发者如何检测客户端是否包含浏览器驱动呢?
哪些渲染工具有这些特征呢?本节我们将探讨浏览器驱动的相关知识
- 打开网页
- 定位按钮并点击
- 从页面中提取文章内容
- 打印文章内容
from selenium.webdriver import Chrome import time browser = Chrome() browser.get('http://www.porters.vip/features/webdriver.html') # 定位按钮并点击 browser.find_element_by_css_selector('.btn.btn-primary.btn-lg').click() # 定位到文章内容元素 elements = browser.find_element_by_css_selector('#content') time.sleep(1) # 打印文章内容 print(elements.text) browser.close()结果
请不要使用自动化测试工具访问网页
代码运行后得到的结果与页面显示的结果不同,这次又遇到了什么样的反爬虫呢?
既然使用 Selenium 套件无法获得目标数据,那我们就用 Puppeteer 试试,对应的代码如下
import asyncio from pyppeteer import launch async def main(): browser = await launch() page = await browser.newPage() await page.goto('http://www.porters.vip/features/webdriver.html') # 定位按钮元素并点击 await page.click('.btn.btn-primary.btn-lg') # 等待 1 秒 await asyncio.sleep(1) # 网页截图保存 await page.screenshot({'path': 'webdriver.png'}) await browser.close() asyncio.get_event_loop().run_until_complete(main())结果同样显示 请不要使用自动化测试工具访问网页
结果说明使用 Puppeteer 也无法获得目标数据。
根据网页给出的提示信息,我们知道网页将这两次请求所用的工具判定为“自动化测试工具”
要想获得目标数据,就要找到网页判定客户端是否为“自动化测试工具”的依据,然后再考虑解决办法
Web Driver 识别原理
仔细观察网页中的代码,我们注意到 HTML 代码中的按钮设定了 onmousemove 事件
该事件绑定了名为 verify webdriver 的 JavaScript 方法
function verify_webdriver(){ var webr = navigator.webdriver; elements = document.getElementById('content'); if (webr){ elements.innerHTML = "请不要使用自动化测试工具访问网页"; }else{ elements.innerHTML = "原来这个方法使用了 Navigator 对象 (即 windows. navigator对象) 的 webdriver 属性来判断客户端是否通过 WebDriver 驱动浏览器。
如果检测到客户端的 webariver 属性,则在文章内容标签处显示 “请不要使用自动化测试工具访问网页”, 否则显示正确的文章内容。
由于 Selenium 通过 WebDriver 驱动浏览器,客户端的 webdriver 属性存在, 所以无法获得目标数据。在 Puppeteer 文档中介绍到, Puppeteer 根据 Devtools 协议控制 Chrome 浏览器或Chromium 测览器,虽然没有提到是否使用 WebDriver, 但事实证明 Puppeteer 也存在 webdriver 属性
Navigator 对象,它的属性列表中就有 webdriver 的介绍
开发者正是利用 Navigator 对象完成的对客户端是否使用 WebDriver 的判断。
平时大家在网上查阅文章时见到的类似“ Selenium 检测”或“ Chrome 检测”等词,指的就是 Webdriver 识别。
WebDriver 识别的绕过方法
要注意的是, navigator. webdriver 只适用于使用 Web Drive r的渲染工具,对于 Splash 这种使
用 WebKit 内核开发的渲染工具来说是无效的。我们可以用 Splash 获取目标数据, Splash脚
本如下
function main(splash, args) assert (splash: go(args ur1)) assert( splash: wait(0.5)) --定位按钮 local bton= splash: select('btn. btn-primary btn-lg') assert(splash: wait(1)) --鼠标悬停 bton:mouse_hover() --点击按钮 bton:mouse_click() assert(splash:wait(1)) return { -- 返回页面截图 png = splash:png(), }模态框中显示的是文章内容。这说明只要我们使用的渲染工具没有 wearier属性,就能获得
目标数据
WebDriver 检测的结果有3种,分别是true、 false 和 undefined。
当我们使用的渲染工具有webdriver属性时,navigator. webdriver 的返回值就是true
反之则会返回fa1se或者 undefine
了解了 WebDriver 识别的原理和返回值后,我们就能想出应对的办法了。既然 WebDriver 的识别依赖 navigator, webariver 的返回值,那么我们在触发 verify_webdriver() 方法前将navigator.wearier 的值改为 false 或者 undefined 即可。
Selenium 套件和 Puppeteer 都提供了运行 JavaScript 代码的方法,接下来我们就尝试使用 JavaScript 修改 navigator. webdriver 的值
Selenium 套件对应的 Python 代码为
from selenium.webdriver import Chrome import time browser = Chrome() browser.get('http://www.porters.vip/features/webdriver.html') # 编写修改 navigator.webdriver 的值为 JavaScript 代码 script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});' # 运行 JavaScript 代码 browser.execute_script(script) time.sleep(1) # 定位按钮并点击 browser.find_element_by_css_selector('.btn.btn-primary.btn-lg').click() # 定位到文章内容元素 elements = browser.find_element_by_css_selector('#content') time.sleep(1) # 打印文章内容 print(elements.text) browser.close()这个时候页面结果就被打印出来了
这说明使用 Javascript 修改 navigator, webdriver 属性值的方法是可行的
要注意的是,这种修改该属性值的方法只在当前页面有效,当浏览器打开新标签或新窗口时需要
重新执行改变 navigator. webdriver 值的 Javascript 代码除此之外,还有一种方法可以绕过 navigator. webdriver 的检测 mitmproxy (详见htps:∥
mitmproxy.org/) 是一个开源的交互式 HTTPS 代理,客户端可以使用它提供的 API 来过滤 JavaScript 文件中检测 navigator. webdriver属性值的代码mitmproxy 在此过程中作为浏览器和服务器的中间人,每一次请求和响应都会经过 mitmproxy
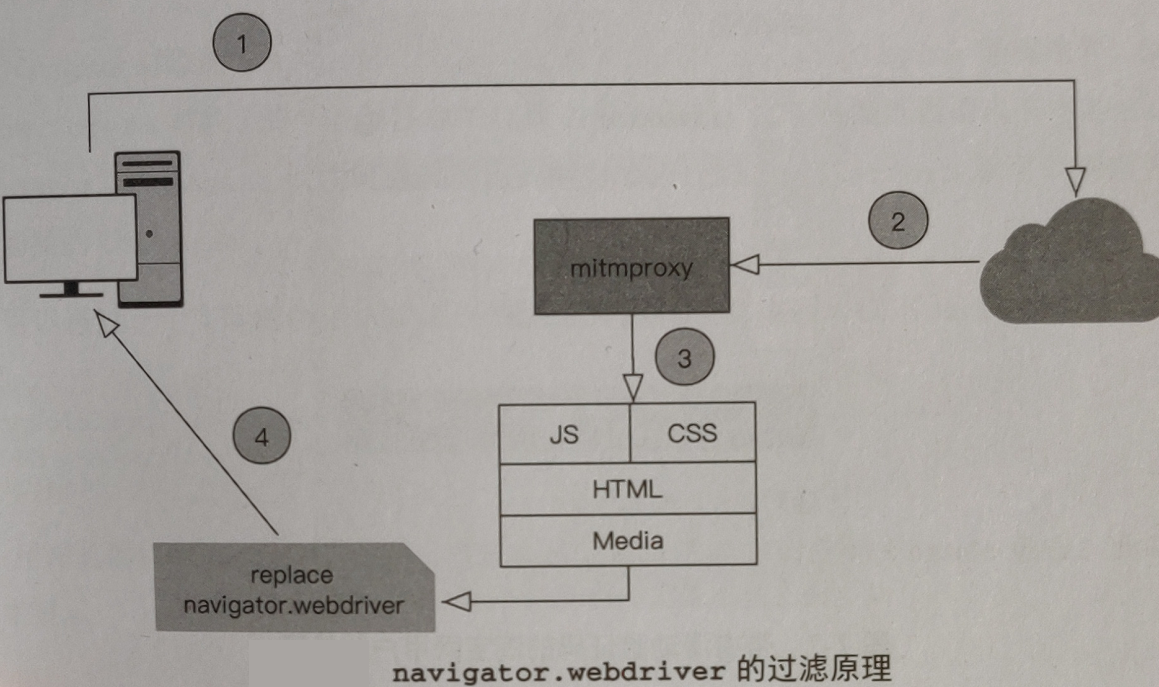
正是由于 mitmproxy 中间人的角色,所以设置好过滤规则后,无论是重新打开标签还是新窗口
都不会重置 navigator.webdriver 的属性值
浏览器特征
判断客户端身份的特征条件不仅有 WebDirver,还包括客户端的操作系统信息和硬件信息等
开发者将这些特征值作为区分正常用户和爬虫程序的条件
除了 Navigator 对象的 serAgent、 cookieEnable、 platform、 plugins 等属性外, Screen对象(即 window. screen对象)的一些属性也可以作为判断依据。
比如将浏览器请求头中的 User- Agent 值与 navigator. userAgent 属性值进行对比
结合 navigator. platform 就可以判断客户端是否使用随机切换的 User-Agent
我们可以通过一个实际的例子来验证这种想法
<script> console.log("userAgent:" + navigator.userAgent); console.log("platform:" + navigator.platform); </script>然后用浏览器打开该 HTML 文件,接着唤起开发者工具并切换到 Console面板。此时可以看到
userAgent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.36 Safari/537.36 platform:Win32在浏览器请求头中的 User- Agent 值与 navigator. userAgent 属性值是相同的,如果值不同则将以客户端视为爬虫程序。
User-gent中的操作系统显示为 Win32 ,如果 navigator.platfom属性值与此不符,那么也可以将该客户端视为爬虫程序。
WebDriver 示例反爬虫
我们使用 Puppeteer 截图,Puppeteer 允许设置浏览器窗口的宽和高
import asyncio from pyppeteer import launch async def main(): browser = await launch() page = await browser.newPage() await page.goto('http://www.porters.vip/features/browser.html') await page.setViewport({'width': 1000, 'height': 1000}) await page.screenshot({'path': 'browser.png'}) await browser.close() asyncio.get_event_loop().run_until_complete(main())运行后得到图片
我们来对比一下 3 种渲染工具访问示例网址页面后得到的特征属性值,不同之处
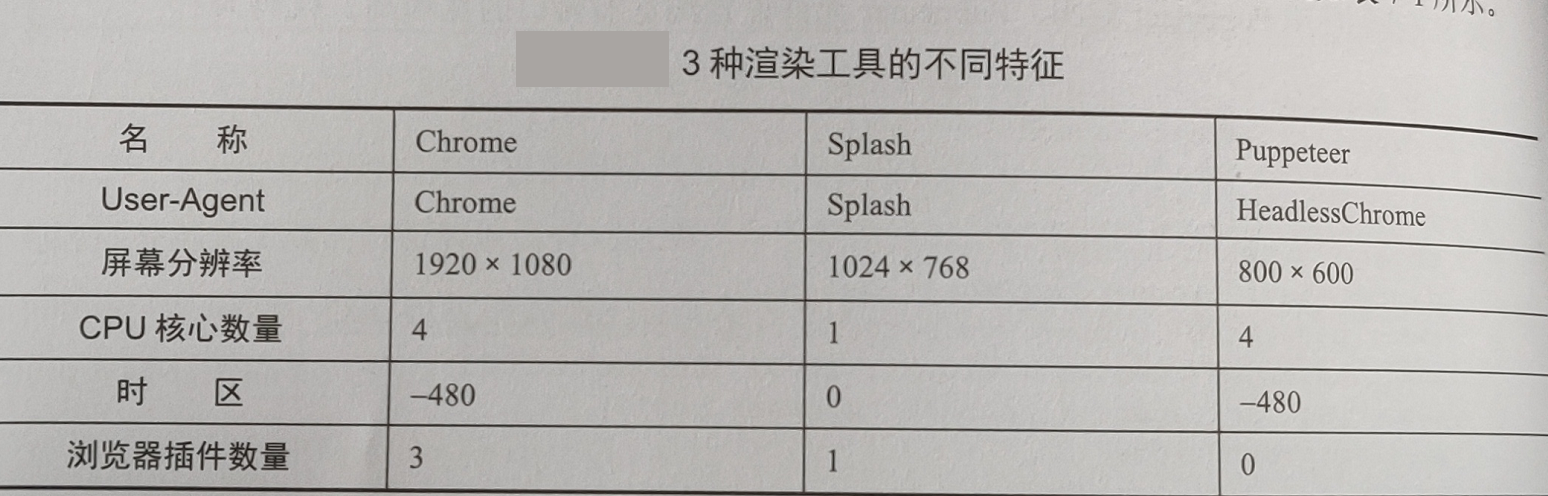
首先是 User-Agent 属性, Splash 和 Puppeteer 都有明显的标识,所以 User-Agent 属性值可以作为客户端特征。
接着看屏幕分辨率,3 种工具的分辨率都不同,所以屏幕分辨率也可以作为客户端特征。
核心数量方面,由于阿里云 ECS 是 1 核,所以 Splash 显示为 1 核。一般个人计算机的核心数量为 2 个以上,除非客户端的计算机运行在虚拟机中或是年代久远的。因此,CPU 核心数量同样可以作为客户端特征
不同渲染工具的浏览器插件数量也是不相同的,虽然插件数量与渲染工具关联并不大(这个
要受插件安装影响),但这个属性值可以作为客户端特征。事实上,只要有可能出现不同结果的属性,就可以作为客户端特征,所以时区属性值也包含在内
属性值可以作为特征并不代表服务器端通过单个属性值就能确认客户端身份,它们只是服务器端判断客户端身份的依据之一
要注意的是,这些属性的值可以通过 JavaScript进行更改,所以这种特征识别方式得到的结果是不可靠的
访问频率限制统过实战
访问频率指的是单位时间内客户端向服务器端发出网络请求的次数,它是描述网络请求频繁程度的量
正常用户浏览网页的频率不会像爬虫程序那么高,开发者可以将访问频率过高的客户端视为爬虫程序
任务:连续10次访问目标网页,要求响应状态码为200。
这个任务看起来挺简单的,我们可以直接用 Requests库发起请求
import requests for i in range(10): res = requests.get('http://www.porters.vip/features/rate.html') print(res.status_code)结果
200 200 200 200 200 200 503 503 503 503如果加上 time.sleep(1) 就能保证每次请求都是 200
实际上,爬虫总是希望请求评率越搞越好,这样才能够在最短的时间内完成爬取任务
刚才使用的 time.sleep(1) 这种降低请求频率的方法并不是爬虫工程师最好的选择
面对根据 IP 地址实现的访问频率限制反爬虫,我们可以使用多台机器共同爬取
假如数据总量为 5 万条,目标网站限速为 1r/s ,使用 time.sleep(1) 这种方式完成爬取任务需要耗费的时间约为13.9小时。
此时将爬取机器从 1 台增加到10台 (10个IP) 那么爬取时间就会降低到 1.39 小时。
这种使用多台机器共同爬取的方法称为多机爬取,如果这些机器分布在不同的地域,并且它们使用的是相同的 URL 队列组合就是分布式爬虫。
分布式爬虫分为 对等分布式 和 主从分布式

使用分布式爬虫后,就可以在单位时间内发起更多的请求。
这种方式能够有效地应对访问频率限制,但经济成本很高
除了增加机器外,还可以使用 IP 切换的方式提高访问频率。
假如用一台机器作为代理,轮流使用本机 IP 和代理 IP 发起请求,就能够将请访问频率提高 1 倍, 9 个代理能够将访问频率提升9倍
想要在 1 台机器上提高访问频率,可以使用多个 IP 代理。
IP 代理其实是维护一个 IP 池,爬虫程序每次发出请求时都从 IP 池中取出 1 个 IP 作为代理
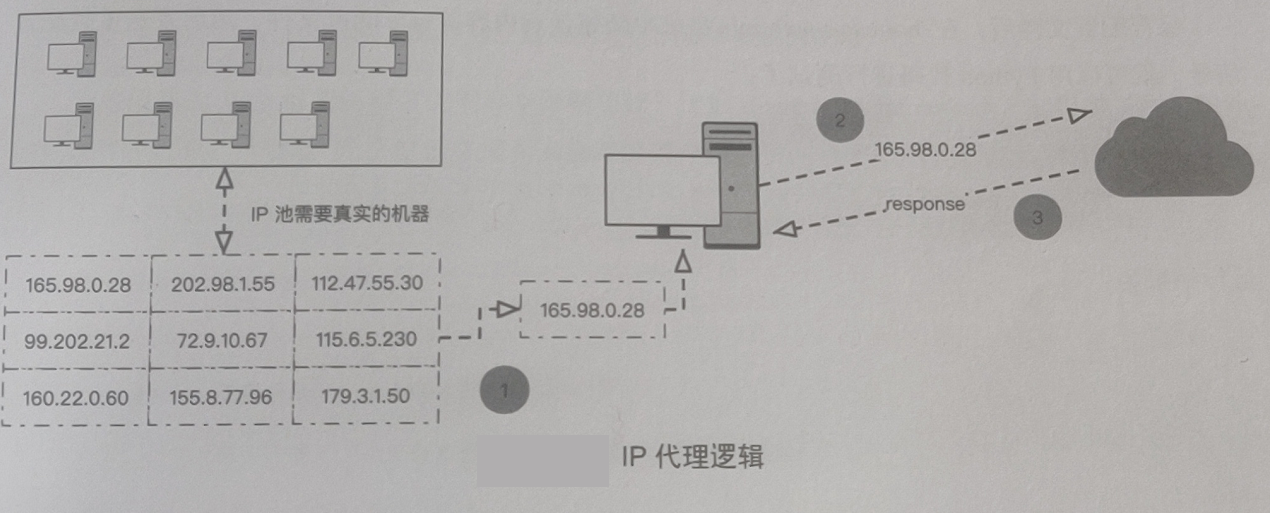
要注意的是 IP 池中的 IP 地址需要由真实的机器(通常是服务器)提供代理服务,我们将这些
提供代理服务的机器的P地址收集起来,汇聚成一个“池”,所以叫作 IP 池。可以自己搭建用于 IP 代理的服务器,也可以直接从提供代理服务的商家购买 IP
访问频率限制的原理
开发者认为访问频率过高的是爬虫程序。
要限制爬虫程序的请求频率,首先就是要找到并确定客户端的身份标识,然后根据标识记录该客户端的请求次数,并且拒绝单位时间内请求次数过多的客户端请求。
提到客户端身份标识,我们想到的第一个答案就是 IP 地址。
可以用 Nginx 实现根据 IP 地址限制爬虫访问频率的功能
浏览器指纹知识扩展
除了 IP 地址之外,用于确定客户端身份的标识还有登录后的用户凭证(如 Cookie 或 Token )和
览器指纹Cookie 和 Token 通常由后端程序生成,所以对该标识的限制任务也由后端程序完成。
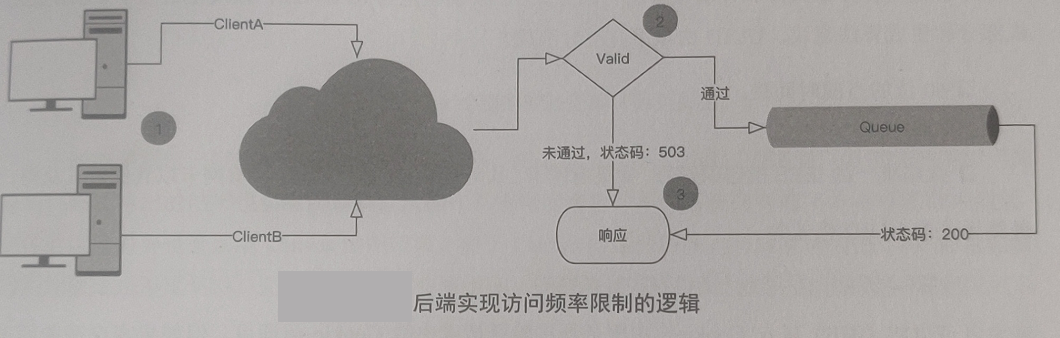
后端程序会维护用户身份标识和单位时间内的请求次数队列。
每次客户端发起请求时,后端程序会将请求携带的 Cookie 或 Token 信息与队列中的用户身份标识进行对比。
如果队列中没有该用户标识记录或单位时间内请求次数未达到阈值,则响应该请求,并且将队列中对应的请求次数进行累加,反之则拒绝该请求后端实现访问频率限制的逻辑
一些成熟的 web 框架就附带访问频率限制功能,比如 django rest framework,它提供了用于限速的模块 Throttling。
该模块允许对已登录和未登录的用户进行访问频率限制
访间频率限制的单位时间可以是每秒、每分钟、每小时、每天等。对于使用 Cookie 或Token作为依据的访问频率限制方法,我们只需要申请足够多的账号,获取每个账号登录后得到的 Cookie 植或 Token 值,就可以像搭建 IP 池一样搭建一个用户身份凭证池。
每次请求时从凭证池中取出一个 Cookie 值或 Token 值,并在代码中使用该值伪造用户身份。
浏览器指纹也称为客户端指纹,是指由多种客户端特征信息组成的字符串结果。
组成浏览器指纹的特征信息包括硬件信息(如屏幕的分辨率和色值、CPU的核心数与类型等)、浏览器信息如之前提到的 platform、插件列表和 User-Agent属性值等)和不可重复信息(如 IP 地址、已登录用户的Cookie等)。
其中不可重复信息实际上是可以人为改变的。
这些信息组合成的字符串结果的重复概率比较低,但如果是某个网咖或者学校统一采购的计算机,不同设备就很有可能得到相同的指纹信息,因为它们的硬件配置相同,而且在同一个网段,所以重复的概率就会增加
考虑到这个问题,有人提出利用 UUID、 Canvas 和 Webgl 技术获得“唯一”指纹。
UUID 是通用唯一识别码( Universally Unique Identifier)的缩写,是一种软件建构标准,亦为开
放软件基金会在分布式计算环境领域的一部分。UUID 的规范为RFC4122,该规范给出了 UUID 的组成部分和生成算法建议。
UUID由以下几部分组成。
- 60位的当前时间戳。
- 时钟序列
- 全局唯一的 IEEE 机器识别号,如果有网卡,从网卡 MAC 地址获得,没有网卡以其他方式获得
最终生成的 UUD
开发者可以将 UUID 写人 Cookie,由服务器端验证请求中的 Cookie 值即可。
但如果客户端关闭 Cookie,那么指纹就失效了。
Canvas 是 HTML5 新增的组件,开发者可以使用 JavaScript 在网页上绘制图案和动效。
由 Canvas 绘制的图片可以进行 Base64 编码,得到很长的字符串,业内将这样的字符串称为 Canvas 指纹。
Canvas 不依赖 Cookie,所以即使客户端关闭 Cookie 也不会影响服务器端获取 Canvas 生成的指纹。

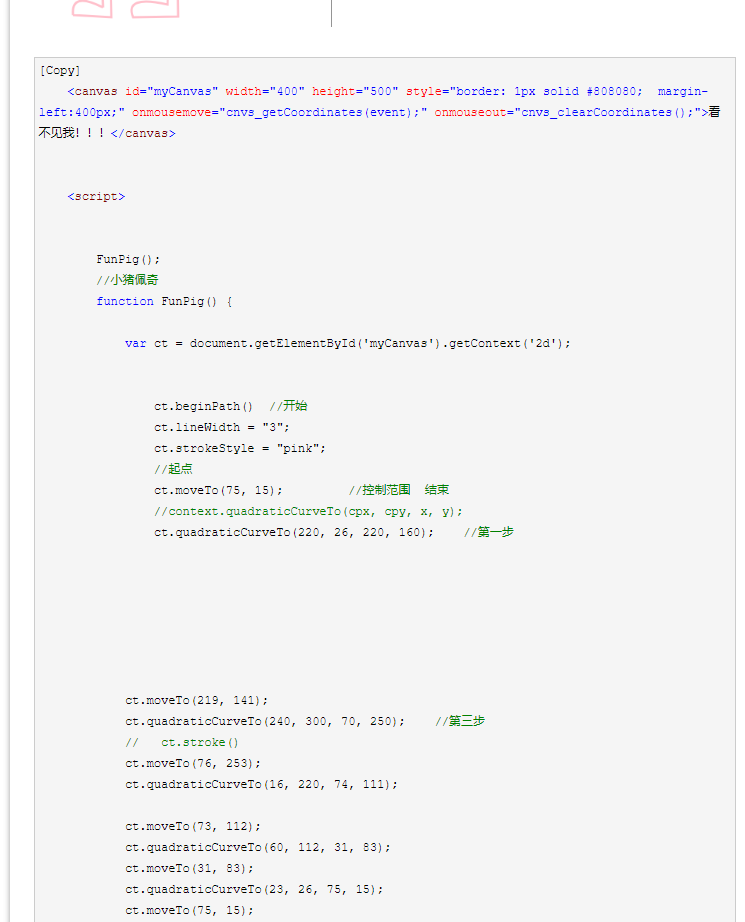
<canvas id="test-canvas" width="500 height="200">
不同的浏览器一般使用不同的图像处理引擎、图像导出选项、图像压缩级别,即使是使用相同的绘制代码,得出的结果也会有所差别。
从操作系统角度来看,不同系统拥有的字体有可能是不同的,字体的渲染差异也会影响 Canvas 绘图结果。
由于 Canvas 的这些特性,开发者认为由 Canvas 绘制成的图片值也是不重复的。
要使用 Canvas 生成指纹,我们需要完成绘图、图片数据读取和数据压缩等任务
Canvas 浏览器指纹展示页主要用于显示 Canvas 绘图的图片数据和该数据的 MD5 加密值
单一的 Canvas 指纹、 WebGL 指纹和 Navigato r对象属性都不能作为客户端的身份标识,但将这些指纹与属性值组合在一起,就能够降低指纹重复的概率。
Fingerprint.js(详见hps:/ fingerprints. com/zh)
是一个开源的指纹检测库,该库通过 JavaScript 从浏览器中收集信息,然后提取可用数据,并将数据加密成一个独特的识别码。Fingerprint.js 使用最先进的识别方法,包括画布指纹追踪、音频采样、 WebGL
指纹识别、字体检查和浏览器插件探测等
隐藏链接反爬虫
隐藏链接反爬虫指的是在网页中隐藏用于检测爬虫程序的链接的手段。
被隐藏的链接不会显示在页面中,正常用户无法访问,但爬虫程序有可能将该链接放入待爬队列,并向该链接发起请求。
开发者可以利用这个特点区分正常用户和爬虫程序
比如爬虫程序找到的链接有 /detail/ 和 /details/,那么开发者将会 /details 穿插在链接中
并设置样式为 display: none
该 CSS 样式的作用是隐藏标签,所以我们在页面只看到 6 件商品,但爬虫程序却提取到 8 件商品的URL。
根据两个这个现象,我们可以大胆猜测这种网站的反爬虫逻辑:
只要客户端访问 URL 为 /details/ 的接口,就将该客户端视为爬虫,并且拒绝来自该 IP 的请求
本章总结
无论是爬虫程序还是我们使用的工具,都有可能存在一些特性,开发者可以根据这些特性来区分
正常用户和爬虫程序。要注意的是,这些特性并非是不可改变的。
爬虫工程师可以根据一些现象猜测目标网站使用的反爬虫手段,然后做出应对