随着单块磁盘在数据安全、性能、容量上呈现出的局限,磁盘阵列(Redundant Arrays of Inexpensive/Independent Disks,RAID)出现了,RAID把多块独立的磁盘按不同的方式组合起来,形成一个磁盘组,以获得比单块磁盘更高的数据安全、性能、容量。
一. 常见的RAID 级别
RAID有RAID0~RAID7几种级别,另外还有一些复合的RAID模式,比如:RAID10、RAID01、RAID50、RAID53。
常用的RAID模式有RAID0、RAID1、RAID5、RAID10。
1. RAID0
RAID0也就是常说的数据条带化(Data Stripping),数据被分散存放在阵列中的各个物理磁盘上,需要2块及以上的硬盘,成本低,性能和容量随硬盘数递增,在所有的RAID级别中,RAID 0的速度是最快的,但是RAID 0没有提供冗余或错误修复能力,如果一个磁盘(物理)损坏,则所有的数据都无法使用。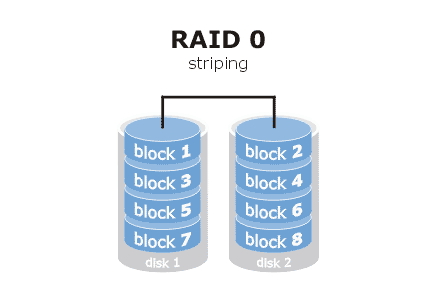
对于有容灾模式的RAID阵列,某块磁盘损坏时,只要换上新的硬盘即可,阵列系统会自动同步数据到新的硬盘。(不支持热插拔的话,需要先关机再开机)
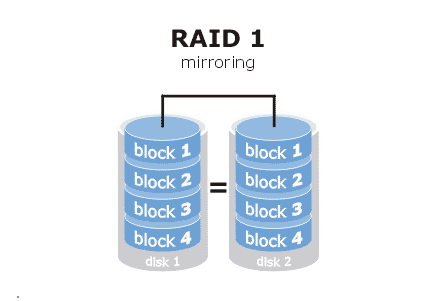
2. RAID1
RAID1也就是常说的数据镜像(Data Mirroring),2块及以上的硬盘(偶数个),被分为2组,数据在每组磁盘中各有一份,若其中一组有磁盘损坏,另一组可以保证数据访问不会中断。RAID1同RAID0一样,有很好的读取速度,但是写的速度,有所下降。
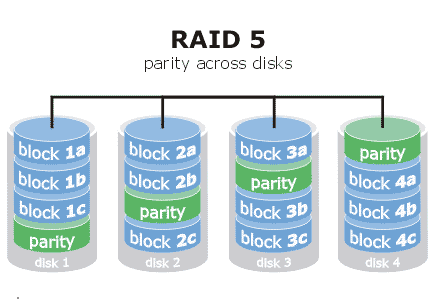
3. RAID5
RAID 5 是一种数据安全、性能、容量、成本、可行性都相对兼顾的解决方案,正因此,类似的RAID2、RAID3、RAID4、RAID6很少得以实际应用。
RAID5需要3块及以上的硬盘, 它不是对存储的数据直接进行备份,而是把数据和相对应的奇偶校验信息存储到组成阵列的各个磁盘上,简单来说就是:任意坏掉一块盘时,另外的N-1块盘可以利用奇偶校验信息,把这块坏掉的磁盘上的数据恢复出来。
RAID 5可以理解为是RAID 0和RAID 1的折衷方案,有和RAID 0相近似的数据读取速度,有比RAID1低的容灾能力(RAID5只允许一块磁盘损坏),因为多了奇偶校验信息,写入数据的速度比RAID1慢。
4. RAID10
RAID10,名称上便可以看出是RAID0与RAID1的结合体,显然需要至少4块磁盘。不过,先RAID0后RAID1,还是先RAID1后RAID0,是不一样的。
RAID01,是先做RAID0,然后对2组RAID0再做RAID1,假设此时某个RAID0坏掉一块磁盘,这个RAID0随即不可用,所有的IO全部指向剩下的那个RAID0;
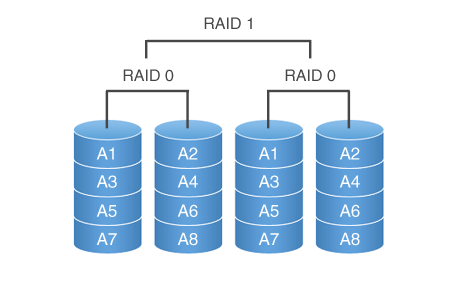
RAID10,是先做RAID1,然后对2组RAID1再做RAID0,假设此时某个RAID1坏掉一块磁盘,当前RAID1仍然能提供服务,并且另一个RAID1也同时可以坏掉一块磁盘。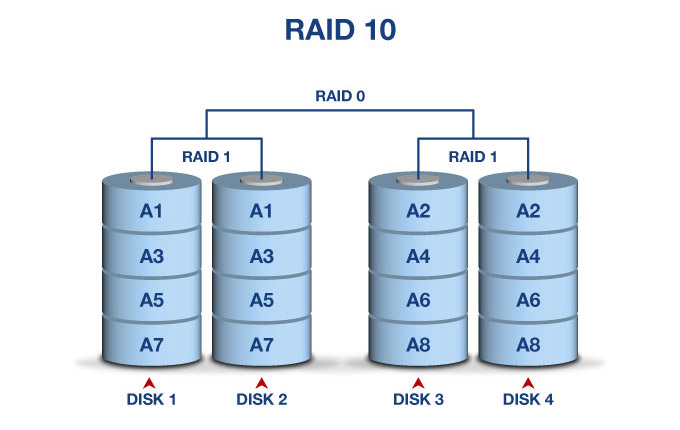
所以,我们通常选择RAID10,而不是RAID01。
5. 不同RAID级别的读写性能
假设都用4块磁盘,RAID0,RAID1,RAID5,RAID10在多线程/多CPU情况下,都可以同时读取多块磁盘,读的性能都很不错;
写的性能(IOPS)依次递减,大致是:RAID0 > RAID10 > RAID1 > RAID5。
二. RAID的空间计算
在做RAID时,通常选择统一规格的磁盘,如果真的有不同空间大小、不同读写速度的磁盘,阵列系统会以空间小、速度低的为标准,空间大、速度高的磁盘向下兼容。比如:100G,50G的2块磁盘做RAID0,得到的空间为50G*2 = 100G。
RAID的空间计算公式:
RAID0的空间:Disk Size * N
RAID1的空间:(Disk Size * N)/2
RAID5的空间:((N-1)/N) * (Disk Size * N) = (N-1) * Disk Size
RAID10的空间:(Disk Size * N/2)/2 + (Disk Size * N/2)/2 = (Disk Size * N)/2
假设都用4块磁盘,每块磁盘都为100G
RAID0的空间:100G * 4 = 400G
RAID1的空间:(100G * 4)/2 = 200G
RAID5的空间:(4-1) * 100G = 300G
RAID10的空间: (100G * 4)/2 = 200G
三. RAID的IOPS计算
1. 单块硬盘的IOPS是固定的
关于单块磁盘IOPS的计算,在” 0. 磁盘读写与数据库的关系”中有详细的方法,但通常这个值是相对固定的,不需要重复计算,参考如下: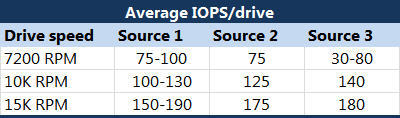
可以发现,同样转数,不同型号的单块磁盘,IOPS都维持在一个类似的数量级。
2. RAID的IOPS计算
有了单块磁盘的IOPS,那么多块磁盘的IOPS计算就很简单了,比如,对于RAID0或者单纯串联磁盘(JBOD: just a bunch of disks)的存储来说,10块175 IOPS的磁盘的总IOPS就是10*175 = 1750 IOPS。
但是对于其他RAID级别并不是这样,因为RAID有多次写IO的开销存在,简单来说就是:对RAID发起一次写IO,RAID内部会有不止一次的写IO发生,RAID内部的IO开销如下: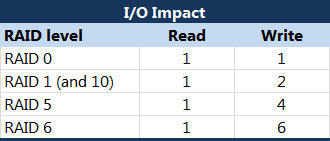
从图中得到公式:用户读IO+N*用户写IO = 总IOPS (N就是RAID内部的IO开销次数)
假设用户读写请求各一半(50%),同样还是以10块175 IOPS的磁盘为例:
50% * 用户总IO请求数 + N * (50% * 用户总IO请求数) = 175 IOPS * 10
以RAID1为例,那么N = 2,上式变为:1.5 *用户总IO请求数 = 1750 IOPS
用户总IO请求数 = 1167 IOPS
这就是10块175 IOPS的磁盘做了RAID1,所能提供的IOPS。
3. RAID的IOPS计算在现实中的应用
在实际使用中,我们通常不是计算现有RAID的IOPS,而是反过来:选择好磁盘规格,RAID模式,测试出系统的读写比例,系统需要达到的IOPS,然后看看,需要多少块硬盘来完成阵列,才能达到这样的IOPS需求?
假设:选择了175 IOPS的磁盘,做RAID1,系统读写比例为60%:40%,系统需要达到2000 IOPS
问:要配置多少块这样规格的硬盘?
把上面的公式改为通用公式:
reads * Workload_IOPS + writes_impact * (writes * Workload_IOPS) = 175 * M
60% * 2000 + 2 * (40% * 2000) = 175 * M
M = 16 (也就是说,要达到指定的2000 IOPS,RAID1需要配置16块175 IOPS的磁盘)
可能有人会觉得,系统的读写请求比例,系统需要达到多少IOPS,并不知道,如果没有前期测试的话,那么只能根据经验来估测了。
四. RAID在数据库存储上的应用
以SQL Server数据库为例,看下不同的RAID级别适用于什么场景:
RAID0,由于没有容灾机制,很少被单独使用。
有人提到过tempdb可以放在RAID0,因为tempdb不用担心丢数据,事实上tempdb故障了,SQL Server是不能正常运行的,所以这么做是不推荐的,建议把tempdb当成用户数据库来对待;
RAID1,操作系统、SQL Server实例、日志文件;
RAID5,数据文件,备份文件;
RAID10,所有类型都适用,不过考虑成本,通常不会全部使用RAID10。