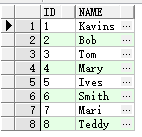
-- Create table create table T_STUDENT ( ID VARCHAR2(10), NAME VARCHAR2(50) ) tablespace USERS pctfree 10 initrans 1 maxtrans 255 storage ( initial 64 next 1 minextents 1 maxextents unlimited );
INSERT INTO T_STUDENT (ID, NAME) VALUES ('1', 'Kavins');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('2', 'Bob');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('3', 'Tom');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('4', 'Mary');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('5', 'Ives');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('6', 'Smith');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('7', 'Mari');
INSERT INTO T_STUDENT (ID, NAME) VALUES ('8', 'Teddy');
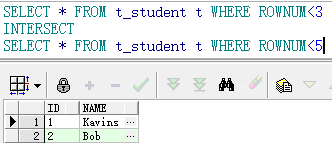
1.交集intersect
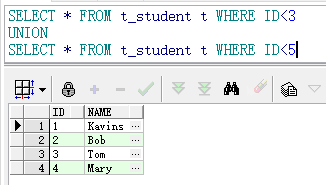
2.并集(union&union all)
1) union 由下面查询结果可以看出,union会自动合并重复的数据
2)union all 不会合并重复数据,而是将两个查询结果直接合并

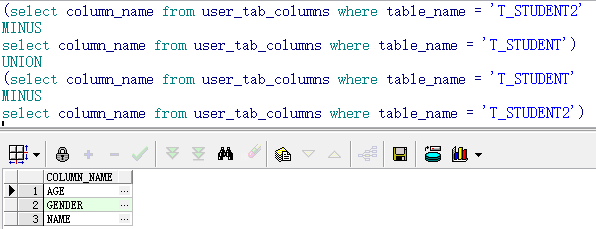
3.差集minus(第一个查询结果减去第二个查询结果)
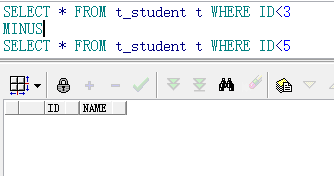
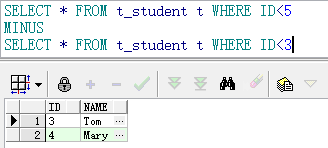
利用minus还可以比较两张表的表结构差异
-- Create table create table T_STUDENT2 ( ID VARCHAR2(10), GENDER VARCHAR2(50), AGE VARCHAR2(10) ) tablespace USERS pctfree 10 initrans 1 maxtrans 255 storage ( initial 16 next 8 minextents 1 maxextents unlimited );
结构差异: