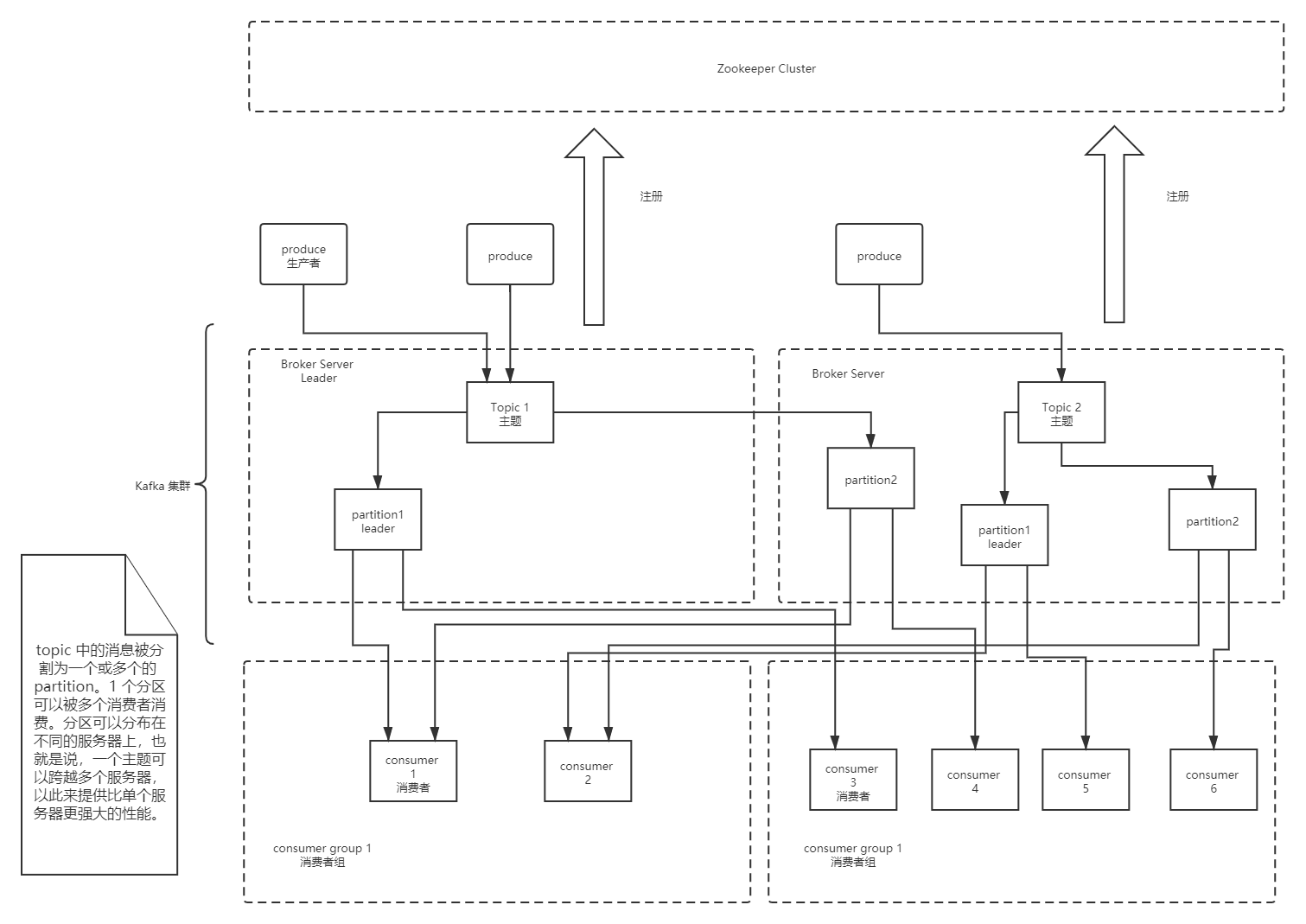
topic
Topic 被称为主题,在 kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表,或者文件系统中的文件夹。
partition
partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个 提交日志。消息以追加的形式写入分区,先后以顺序的方式读取。
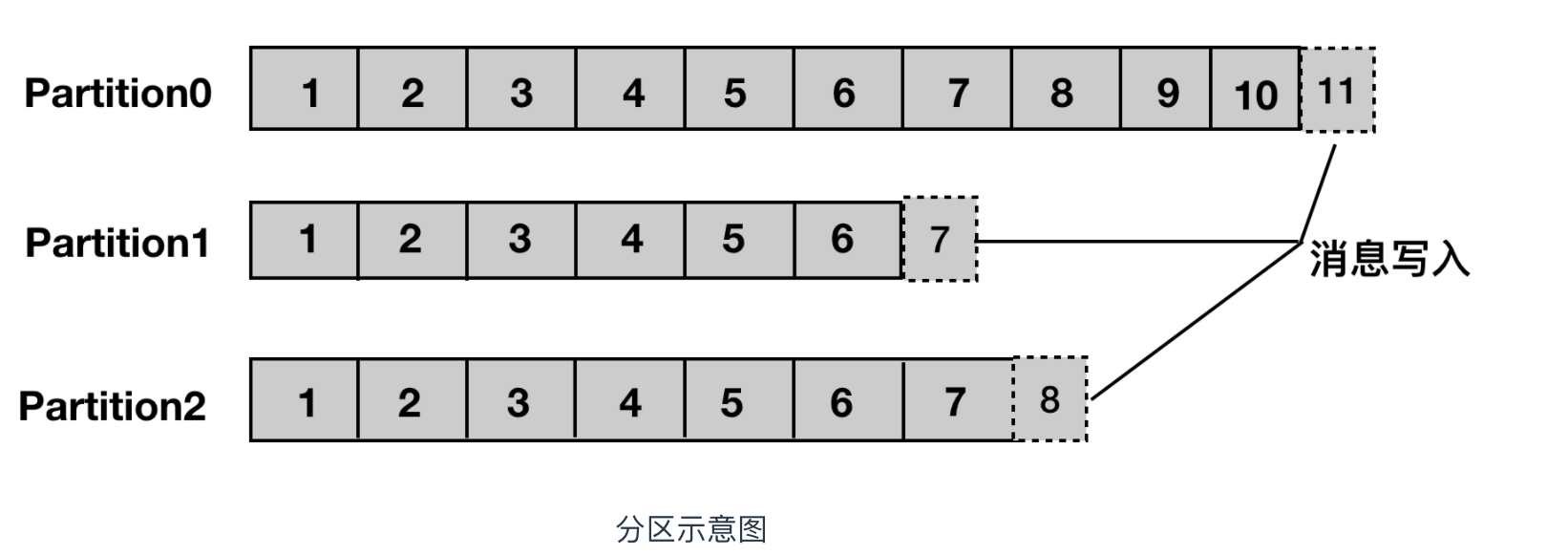
segment
Segment 被译为段,将 Partition 进一步细分为若干个 segment,每个 segment 文件的大小相等。
broker
Kafka 集群包含一个或多个服务器,每个 Kafka 中服务器被称为 broker。broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
broker 是集群的组成部分,每个集群中都会有一个 broker 同时充当了 集群控制器(Leader)的角色,它是由集群中的活跃成员选举出来的。每个集群中的成员都有可能充当 Leader,Leader 负责管理工作,包括将分区分配给 broker 和监控 broker。集群中,一个分区从属于一个 Leader,但是一个分区可以分配给多个 broker(非Leader),这时候会发生分区复制。这种复制的机制为分区提供了消息冗余,如果一个 broker 失效,那么其他活跃用户会重新选举一个 Leader 接管。
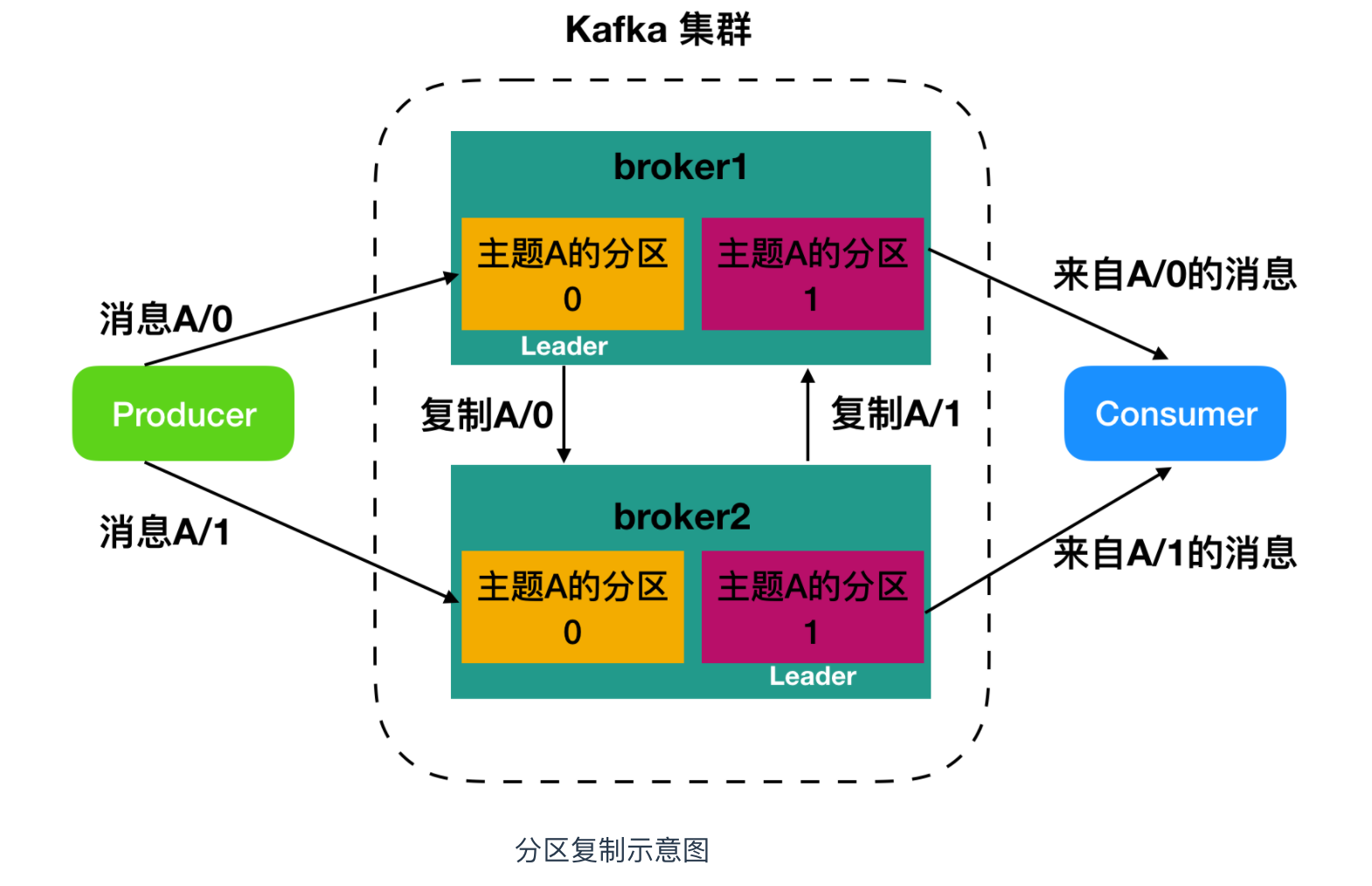
producer
生产者,即消息的发布者,其会将某 topic 的消息发布到相应的 partition 中。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。
consumer
消费者,即消息的使用者,一个消费者可以消费多个 topic 的消息,对于某一个 topic 的消息,其只会消费同一个 partition 中的消息

broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=9092 #当前kafka对外提供服务的端口默认是9092
host.name=192.168.1.7 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/usr/local/kafka/kafka_2.12-2.3.0/log #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=192.168.1.7:2181,192.168.1.8:2181,192.168.1.9:2181 #设置zookeeper的连接端口