转载自:”http://www.heartthinkdo.com/?p=2884
本文概览:介绍了在选型分布式系统时,我们期待的功能有哪些。xxl-job的功能概览。
1 问题背景
目前定时任务,只是在某一个固定机器上配置cron脚本。想引入一个分布式调度平台,对于这个平台我们亟需的功能呢?
1.1 期待的功能
我们经过比较目前开源分布式任务调度框架,选择了xxl-job,这个框架满足了我们所期待一个分布式任务调度平台的功能,而且还有一些意外的功能。
1、自动合理分配机器,避免在同一个时间点,任务都集中到同一个机器。 ( )
)
2、自动编排任务。 ()
比如说task1….taskN,这个N个任务需要顺序执行,所以我们估算每个任务执行时长,去确定每个任务的执行时间点,但是某个任务因为处理数据变多或者其他因素时长变长,此时就会造成任务重叠。如果要解决这种重叠,又需要手动的配置各个任务执行时间点。
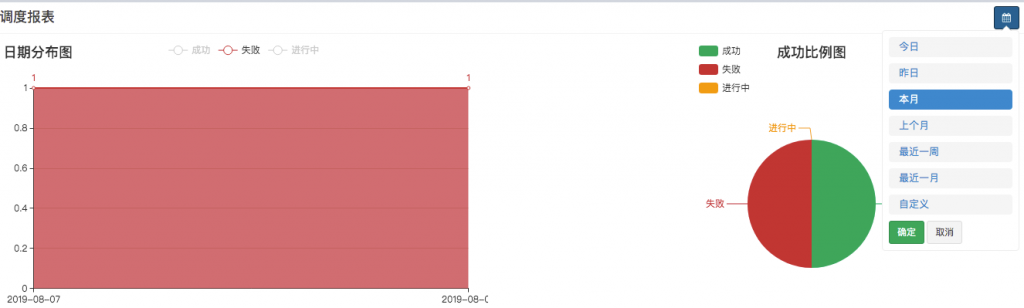
3、缺失任务运营
(1) 一共多少个任务 ()
(2)一个时间点有多少任务运行(需要记录任务开始时间和结束时间) ()
(3)当前正在运行哪些务 ()
在出现线上问题时,迅速查看有哪些任务正在执行
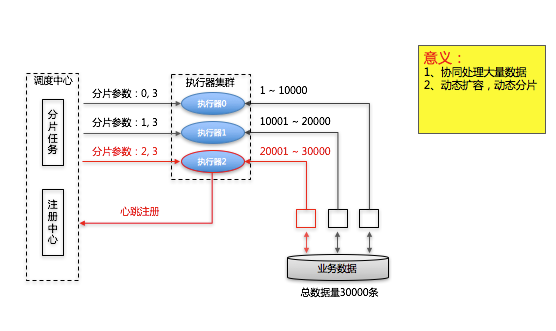
4、任务分片 ()
考虑到个别任务文件量很大,执行慢。采用措施有:
- 文件划分成多个子文件
- 先解析文件入库,然后库数据进行划分(通过startIndex和endIndex来指定)。这里通过对数据库进行分片处理。因为 解析文件速度很快,而且文件还需要校验完整性,所以一般分批策略都是选择对数据库分片。
5、运行超时报警 ()
运行超时会自动kill掉这个任务。
6、任务执行进度查看 ()
通过在线日志打印进度
7、任务异常处理 ()
- “故障转移”发生在调度阶段,在执行器集群部署时,如果某一台执行器发生故障,该策略支持自动进行Failover切换到一台正常的执行器机器并且完成调度请求流程。
- “失败重试”发生在”调度 + 执行”两个阶段,支持通过自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
除了上面我们能够想到功能,在查看xxl-job时还有额外的功能:
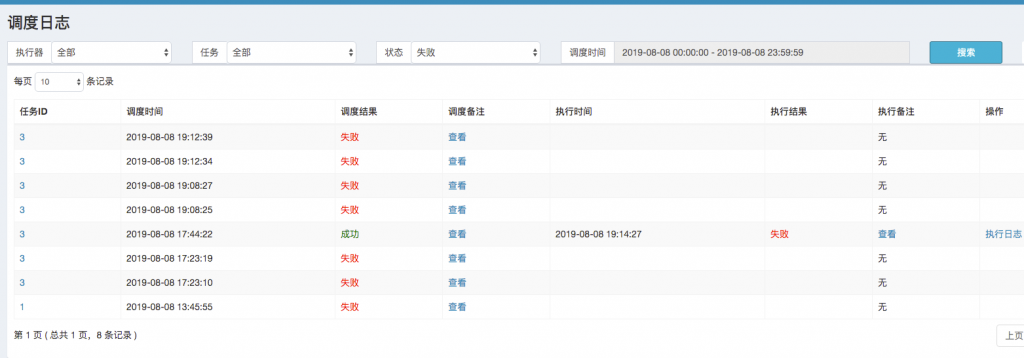
1、定时任务报错信息汇总 ()
通过日期区间查询那些任务失败。可以查看当天有哪些失败的任务
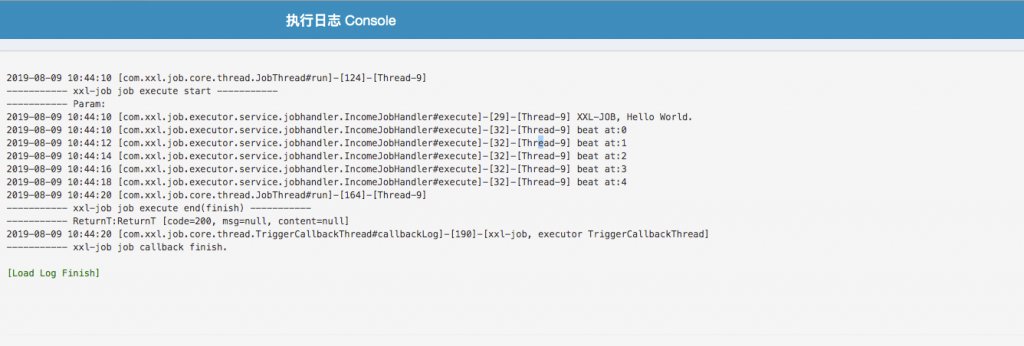
2、在线查看日志 ( )
可以用来打印执行进度。(打印总条数、打印已处理的个数来展示进度信息)
1.2 XXL-JOB功能概览
如下是官网提供的所有功能:
2 xxl-job介绍
2.1 架构图
分为两大模块:调度中心 和 执行器服务。
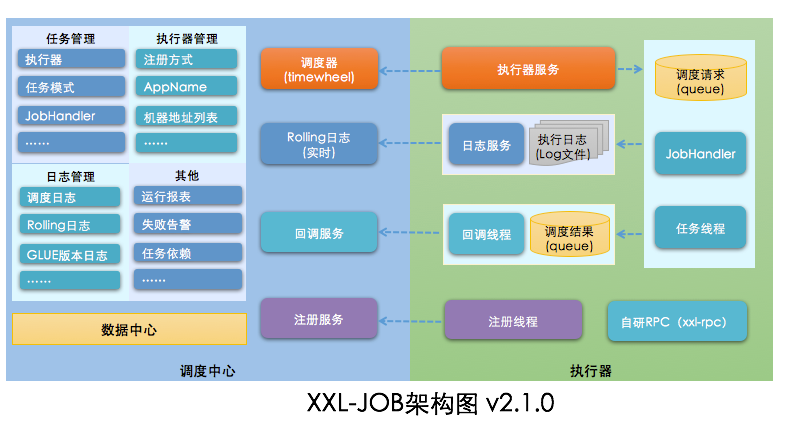
2.2 数据流程
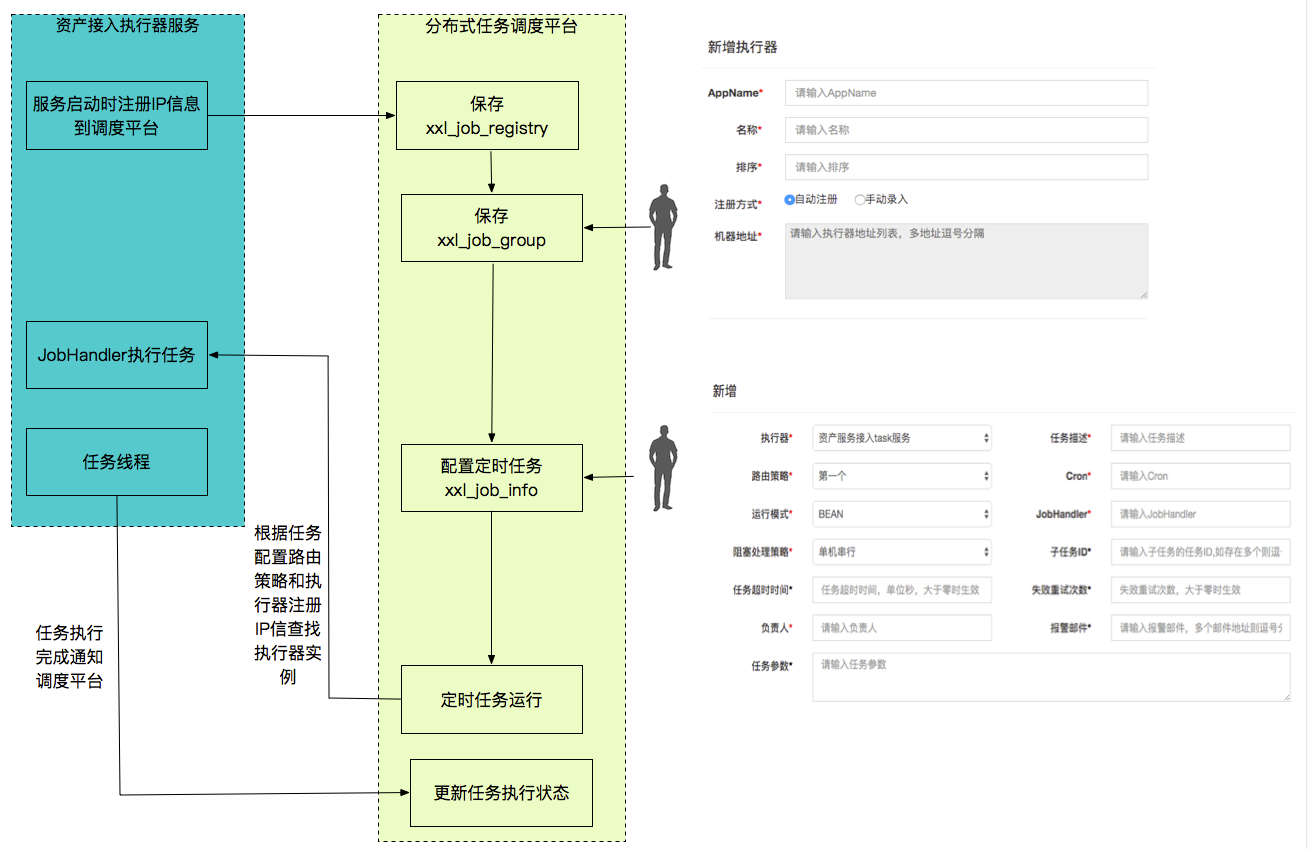
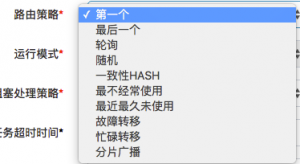
1、调度平台选择哪一个执行器?在配置任务时,通过这个调度策略来指定。
2.3 数据表含义
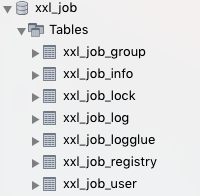
1、xxl_job_group。保存执行器服务的名称。
这个表信息需要手动新增的。字段说明:
- order。任务管理页面中下拉框的顺序。
对应如下信息

2、xxl_job_info。定时任务执行信息
3、xxl_job_registry。保存执行器服务的注册的IP信息,便于调度中心选择一个机器执行。
如下:一个服务registry_key只能有一个记录,多个IP都追加到regitry_values
4、xxl_job_logglue。任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
3 XXL-job改造
1、没有短信报警
在JobFailMonitorHelper.failAlarm代码中进行扩展。
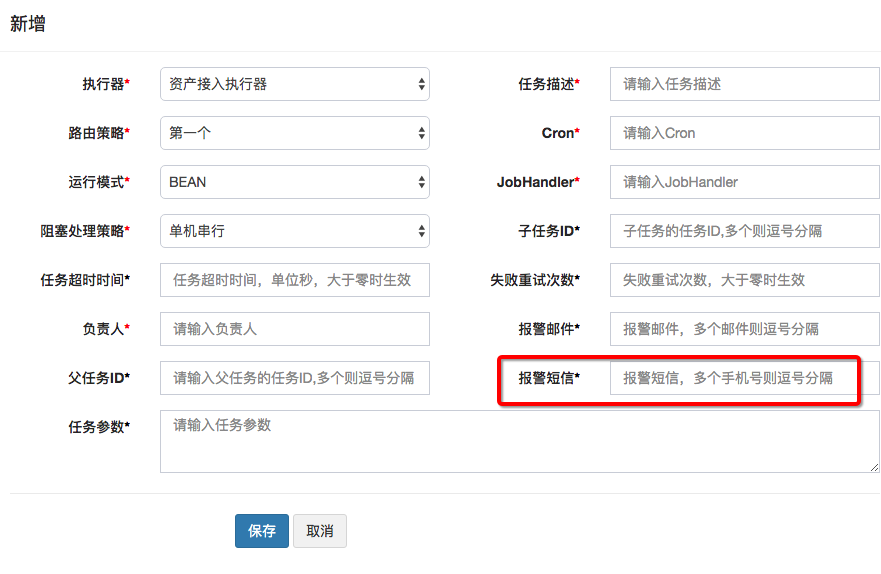
2、没有任务依赖功能
目前只提供了一种功能,一个任务执行完成之后,自动触发它的子任务。但是却没有提供如下功能:如果一个任务需要依赖多个父任务,只有所有父任务执行完成之后,才能执行这个任务。
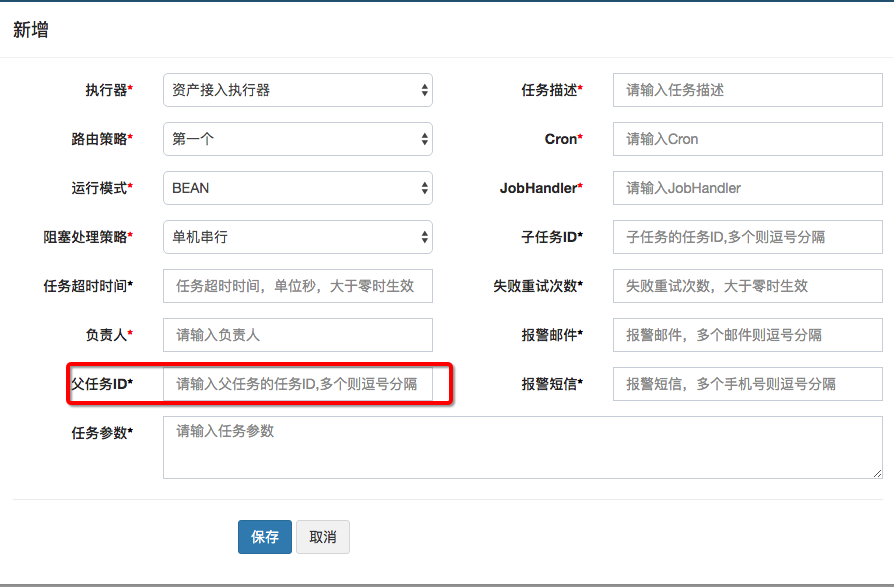
关于当前的依赖功能还有几点说明:
- 如果一个任务T配置了子任务ST,这个子任务ST也配置了cron自动触发,那么这个ST会在T执行完成之后触发一次,在cron时间点到达时候再触发一次
- 如果有多个任务T1,T2等都配置了子任务ST,则T1、T2等每个任务执行完成都会触发一次ST。
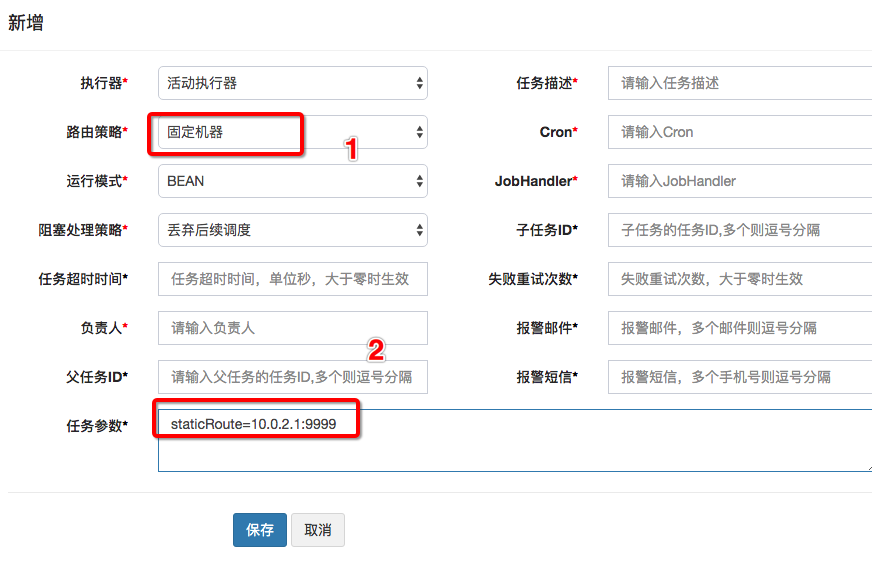
3、固定路由
指定执行器的IP机器,调度到指定的机器。最终实现如下:
- 路由策略选择:固定机器
- 任务参数新增:staticRoute=10.60.65.22:9999
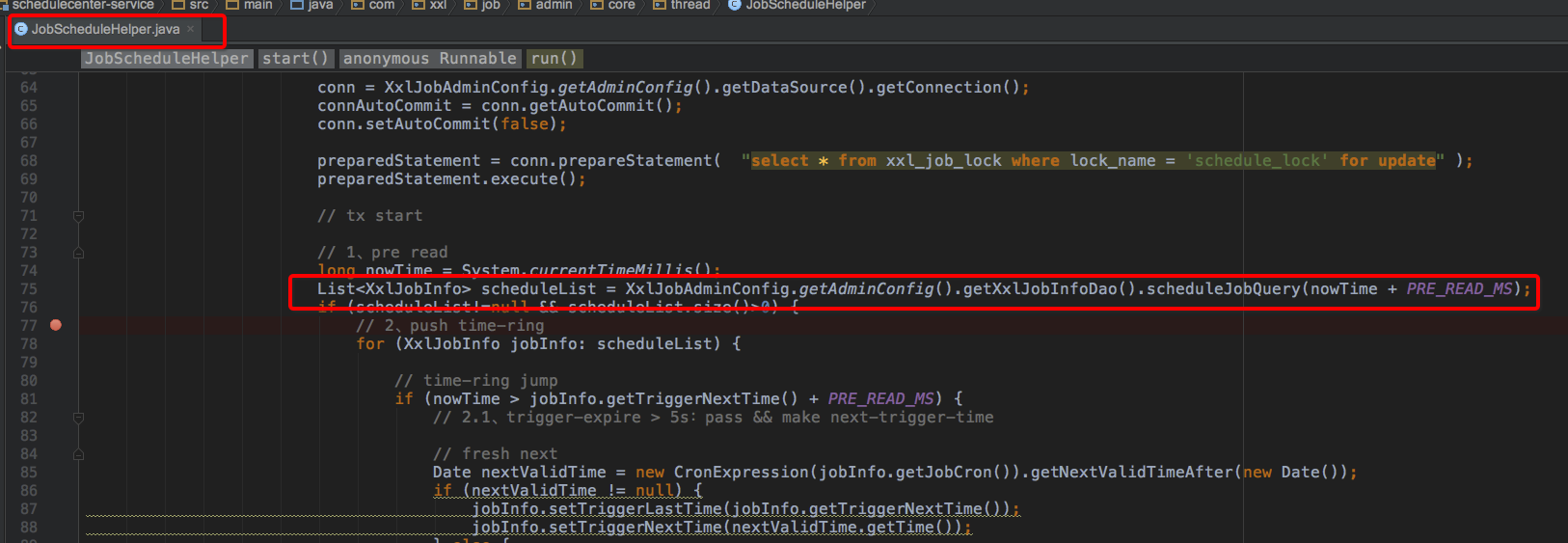
4、任务重复调度问题
(1)数据库分为了主从两种方式,查询如下sql走了从库:
SELECT *
FROM xxl_job_info AS t
WHERE t.trigger_status = 1
and t.trigger_next_time< #{maxNextTime}
(2)问题解决
上面的查询走写库。
附:开源对比
参考:https://blog.csdn.net/guyue35/article/details/84883408
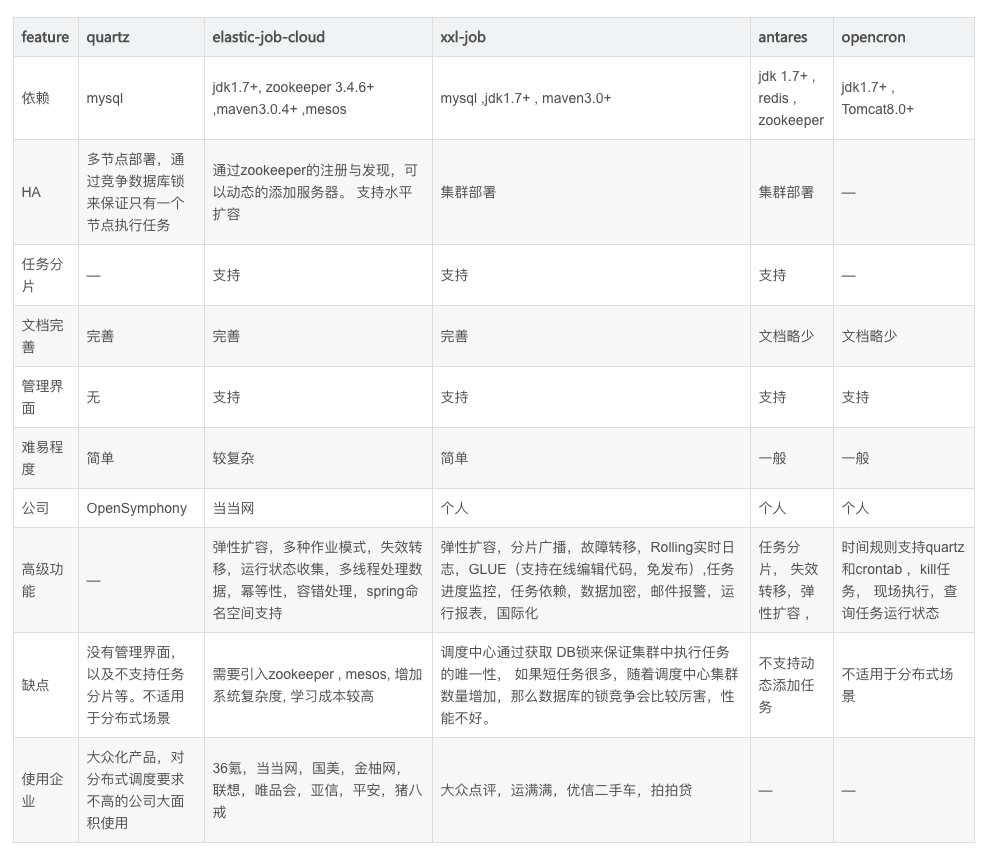
总结,选型xxl-job。原因:从功能上xxl-job和elastic-job差不多,考虑到如下:
- 使用xxl-job用户量大,有问题好解决。
- 容易扩展自定义功能,即易于二次开发。比如固定路由功能、短信报警等。
-
elastic-search是基于jar的。xxl-job是微服务。这个就涉及到了中间件是服务还是jar的对比了,当我们需要对调度中间件进行升级时,如果是jar,那么所有的引用jar的服务都需要做一次升级,成本较高。基于服务的中间件,只需要升级中间件服务就可以了。
-
xxl-job除了mysql,无外部依赖,可靠性高于elastic-search(依赖zookeeper)。