第十一讲:
2个node环境下replica shard 是如何分配的
1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
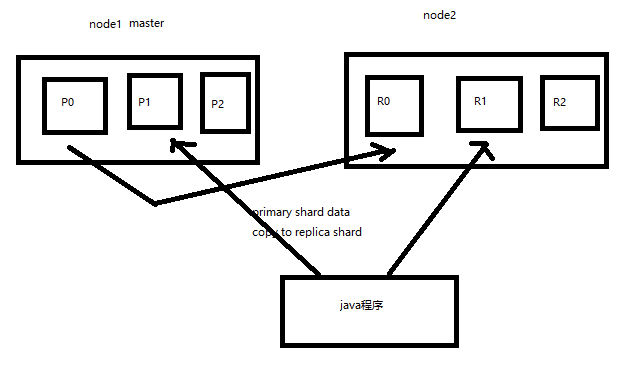
当primary shard 的replica shard被分配后 他的数据会拷贝到replica shard中
读请求 primary 和 replica都可以响应
第十二讲:横向扩容过程、如何超出扩容极限、如何提升容错性
1、图解横向扩容过程,如何超出扩容极限,以及如何提升容错性
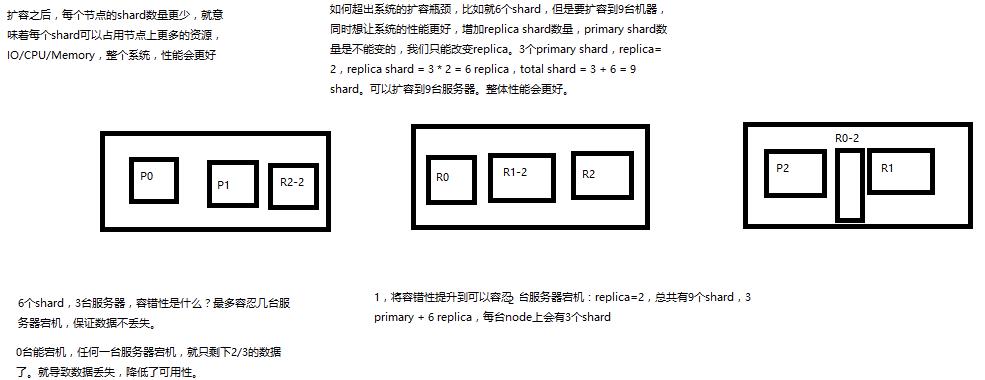
(1)primary&replica自动负载均衡,6个shard,3 primary,3 replica
(2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
(3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
(4)超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
(5)3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳0台机器宕机
(6)这里的这些知识点,你综合起来看,就是说,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量;另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失
保证数据的完整性!!!
看几个primary shard 几个node 一个node能存放几个shard
第十三讲! master选举 replica容错 数据恢复
1、图解Elasticsearch容错机制:master选举,replica容错,数据恢复
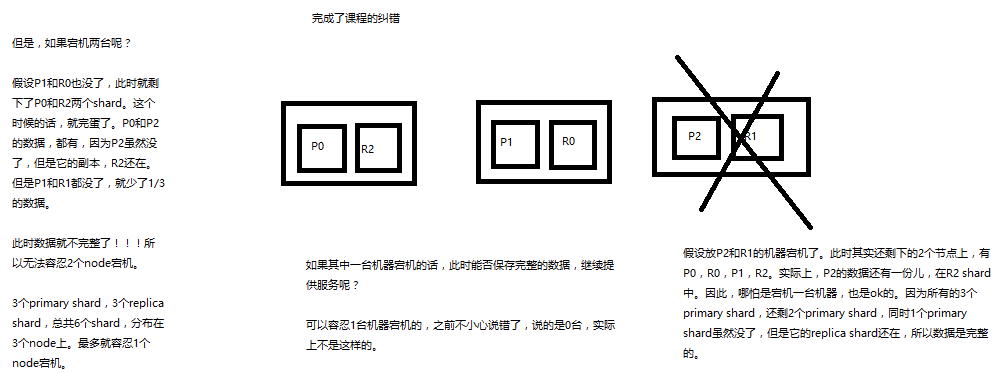
(1)9 shard,3 node
(2)master node宕机,自动master选举,red
(3)replica容错:新master将replica提升为primary shard,yellow
(4)重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green

当一个primary shard宕机之后 选举新的master (此时的状态为red) 当选聚完新的master之后变成yellow 重启故障的node ,new master 将确实的副本copy一份到该node上 此时状态变为greeen
第十四讲!
1、_index元数据
2、_type元数据
3、_id元数据
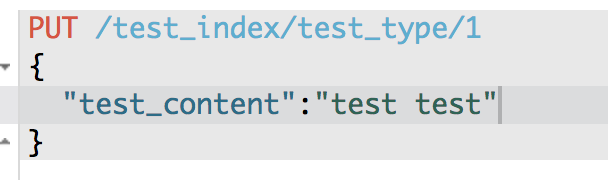
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"test_content": "test test"
}
}
------------------------------------------------------------------------------------------------------------------------------------------
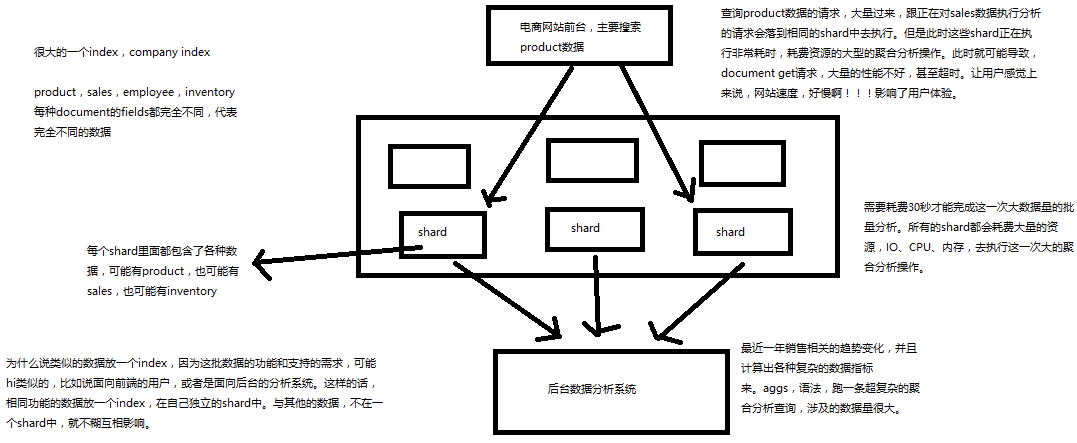
1、_index元数据
(1)代表一个document存放在哪个index中
(2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
(3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
(4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
2、_type元数据
(1)代表document属于index中的哪个类别(type)
(2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,生鲜商品,日化商品,等等。
(3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号
3、_id元数据
(1)代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document
(2)我们可以手动指定document的id(put /index/type/id),也可以不指定,由es自动为我们创建一个id
第十五讲!document id 的生成
1、手动指定document id
2、自动生成document id
------------------------------------------------------------------------------------------------------------
1、手动指定document id
(1)根据应用情况来说,是否满足手动指定document id的前提:
一般来说,是从某些其他的系统中,导入一些数据到es时,会采取这种方式,就是使用系统中已有数据的唯一标识,作为es中document的id。举个例子,比如说,我们现在在开发一个电商网站,做搜索功能,或者是OA系统,做员工检索功能。这个时候,数据首先会在网站系统或者IT系统内部的数据库中,会先有一份,此时就肯定会有一个数据库的primary key(自增长,UUID,或者是业务编号)。如果将数据导入到es中,此时就比较适合采用数据在数据库中已有的primary key。
如果说,我们是在做一个系统,这个系统主要的数据存储就是es一种,也就是说,数据产生出来以后,可能就没有id,直接就放es一个存储,那么这个时候,可能就不太适合说手动指定document id的形式了,因为你也不知道id应该是什么,此时可以采取下面要讲解的让es自动生成id的方式。
(2)put /index/type/id
PUT /test_index/test_type/2
{
"test_content": "my test"
}
2、自动生成document id
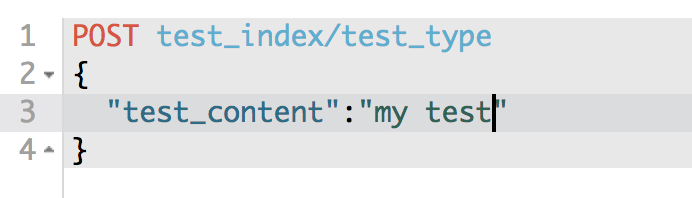

(1)post /index/type
POST /test_index/test_type
{
"test_content": "my test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
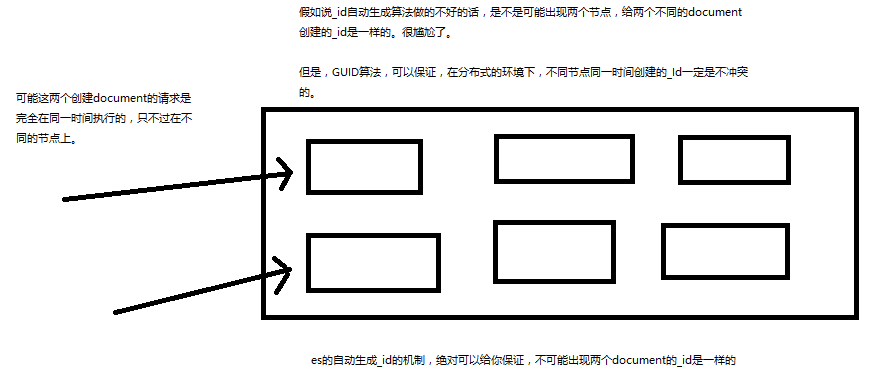
(2)自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
第十六讲!
1、_source元数据
put /test_index/test_type/1
{
"test_field1": "test field1",
"test_field2": "test field2"
}
get /test_index/test_type/1
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
}
_source元数据:就是说,我们在创建一个document的时候,使用的那个放在request body中的json串,默认情况下,在get的时候,会原封不动的给我们返回回来。
------------------------------------------------------------------------------------------------------------------
2、定制返回结果
定制返回的结果,指定_source中,返回哪些field
GET /test_index/test_type/1?_source=test_field1,test_field2
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field2": "test field2"
}
}
第十七讲!
1、document的全量替换
2、document的强制创建
3、document的删除
------------------------------------------------------------------------------------------------------------------------
1、document的全量替换
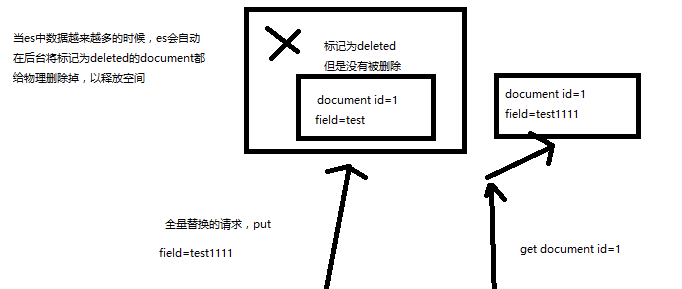
(1)语法与创建文档是一样的,如果document id不存在,那么就是创建;如果document id已经存在,那么就是全量替换操作,替换document的json串内容
(2)document是不可变的,如果要修改document的内容,第一种方式就是全量替换,直接对document重新建立索引,替换里面所有的内容
(3)es会将老的document标记为deleted,然后新增我们给定的一个document,当我们创建越来越多的document的时候,es会在适当的时机在后台自动删除标记为deleted的document
------------------------------------------------------------------------------------------------------------------------
2、document的强制创建
(1)创建文档与全量替换的语法是一样的,有时我们只是想新建文档,不想替换文档,如果强制进行创建呢?
(2)PUT /index/type/id?op_type=create,PUT /index/type/id/_create
------------------------------------------------------------------------------------------------------------------------
3、document的删除
(1)DELETE /index/type/id
(2)不会理解物理删除,只会将其标记为deleted,当数据越来越多的时候,在后台自动删除
第十八讲!
1、深度图解剖析Elasticsearch并发冲突问题

第十九讲!
1、深度图解剖析悲观锁与乐观锁两种并发控制方案

es使用乐观锁
A使用的version版本为1 当插入输入时 如果当前的version也是1 就直接插入
如果当前的version=2 不同 说明数据已经被其他人修改过了 则重新读取es中的数据 重新执行 写入
悲观锁:方便直接加锁 并发能力很低
乐观锁:并发能力很高 不加锁 麻烦 每次更新要先对比
第二十讲!
1、图解Elasticsearch内部如何基于_version进行乐观锁并发控制
(1)_version元数据
PUT /test_index/test_type/6
{
"test_field": "test test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
第一次创建一个document的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1
删除后 再添加同样的一个id 版本号还是会更新 不是立即的物理删除
{
"found": true,
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
我们会发现,在删除一个document之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1
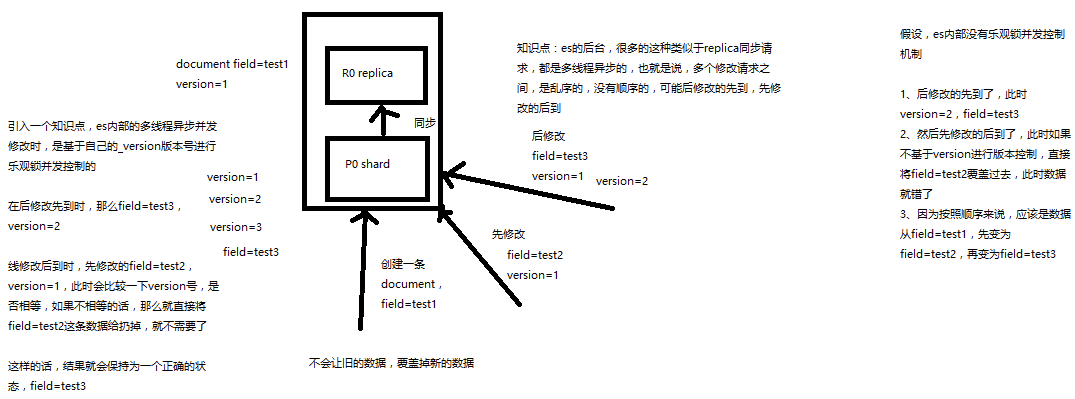
直接把之前修改的还迟到的那个结果扔掉 使用后修改先到的结果作为最终结果