https://www.cnblogs.com/wqbin/p/13219025.html
概述
MySQL中临时表主要有两类,包括外部临时表和内部临时表。
临时表
- 内部临时表:内部临时表主要有两类
- 一类是information_schema中临时表
- 另一类是会话执行查询时,如果执行计划中包含有“Using temporary”时,会产生临时表
- 外部临时表:外部临时表是通过语句create temporary table...创建的临时表,临时表只在本会话有效,会话断开后,临时表数据会自动清理。
区别:
内部临时表与外部临时表的一个区别在于,我们看不到内部临时表的表结构定义文件frm。
而外部临时表的表定义文件frm,一般是以#sql{进程id}_{线程id}_序列号组成,因此不同会话可以创建同名的临时表。
临时表的特点
临时表VS普通表
临时表与普通表的主要区别在于是否在实例,会话,或语句结束后,自动清理数据。比如,内部临时表,我们在一个查询中,如果要存储中间结果集,而查询结束后,临时表就会自动回收,不会影响用户表结构和数据。
另外就是,不同会话的临时表可以重名,所有多个会话执行查询时,如果要使用临时表,不会有重名的担忧。5.7引入了临时表空间后,所有临时表都存储在临时表空间(非压缩)中,临时表空间的数据可以复用。
临时表并非只支持Innodb引擎,还支持myisam引擎,memory引擎等。因此,临时表我们看不到实体(idb文件),但其实不一定是内存表,也可能存储在临时表空间中。
临时表 VS 内存表
临时表既可以innodb引擎表,也可以是memory引擎表。这里所谓的内存表,是说memory引擎表,通过建表语句create table ...engine=memory,数据全部在内存,表结构通过frm管理,同样的内部的memory引擎表,也是看不到frm文件中,甚至看不到information_schema在磁盘上的目录。
在MySQL内部,information_schema里面的临时表就包含两类:innodb引擎的临时表和memory引擎的临时表。比如TABLES表属于memory临时表,而columns,processlist,属于innodb引擎临时表。
内存表所有数据都在内存中,在内存中数据结构是一个数组(堆表),所有数据操作都在内存中完成,对于小数据量场景,速度比较快(不涉及物理IO操作)。
但内存毕竟是有限的资源,因此,如果数据量比较大,则不适合用内存表,而是选择用磁盘临时表(innodb引擎),这种临时表采用B+树存储结构(innodb引擎),innodb的bufferpool资源是共享的,临时表的数据可能会对bufferpool的热数据有一定的影响,另外,操作可能涉及到物理IO。
memory引擎表实际上也是可以创建索引的,包括Btree索引和Hash索引,所以查询速度很快,主要缺陷是内存资源有限。
使用内部临时表
场景
我们先看一下什么时候会使用到内部临时表?
Using temporary
测试表结构如下:

CREATE TABLE `test1` ( `sms_id` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `app_id` int(1) NOT NULL DEFAULT '0', `payment` double NOT NULL DEFAULT '0', KEY `sms_id` (`sms_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
前面提到执行计划中包含有时,会使用临时表,这里列两个主要的场景。
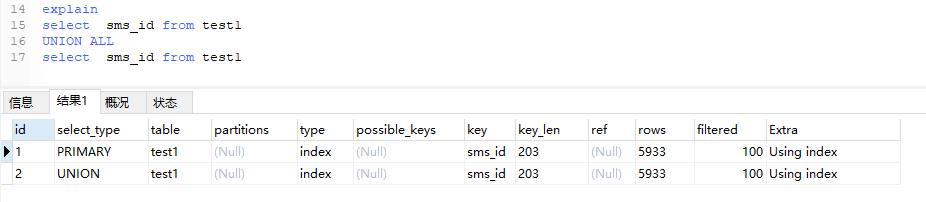
场景1:union 场景
union操作的含义是,取两个子查询结果的并集,重复的数据只保留一行,通过建立一个带主键的临时表,就可以解决“去重”问题,通过临时表存储最终的结果集,所以能看到执行计划中Extra这一项里面有“Using temporary”。
与union相关的一个操作是union all,后者也是将两个子查询结果合并,但不解决重复问题。所以对于union all,没有“去重”的含义,因此也就不需要临时表了。

场景2:group by

group by的含义是按指定列分组,并默认按照指定列有序。上面的SQL语句含义是将test1中的数据按app_id列分组,统计每种app_id列值的记录数目。
从执行计划中看到了"Using temporary;Using filesort":
- 对于group by而言,我们首先需要统计每个值出现的数目,这就需要借助临时表来快速定位,如果不存在,则插入一条记录,如果存在,并累加计数,所以看到了"Using temporary";
- 然后又因为group by隐含了排序含义,所以还需要按照app_id列进行对记录排序,所以看到了"Using filesort"。
1).消除filesort
实际上,group by也可以显示消除“排序含义”。

可以看到,语句中加上“order by null”后,执行计划中,不再出现“Using filesort”。
2).消除临时表

可以看到执行计划中已经没有了“Using temporary”,所以group by并非一定依赖临时表,临时表在group by中的作用主要是“去重”。
所以,实际上有另外一种方式,不使用临时表,直接利用sort_buffer排序(sort_buffer不够时,进行文件排序,具体而言是每一个有序数组作为一个单独文件,然后进行外排归并),然后再扫描得到聚合后的结果集。
3).SQL_BIG_RESULT
同时我们语句中用到了“SQL_BIG_RESULT”这个hint,正是因为这个hint导致了我们没有使用临时表,先说说SQL_BIG_RESULT和SQL_SMALL_RESULT的含义。
-
SQL_SMALL_RESULT:显示指定用内存表(memory引擎)
-
SQL_BIG_RESULT:显示指定用磁盘临时表(myisam引擎或innodb引擎)
两者区别在于,使用磁盘临时表可以借助主键做去重排序,适合大数据量;使用内存表写入更快,然后在内存中排序,适合小数据量。下面是从MySQL手册中摘录的说明。
SQL_BIG_RESULT or SQL_SMALL_RESULT can be used with GROUP BY or DISTINCT to tell the optimizer that the result set has many rows or is small, respectively. For SQL_BIG_RESULT, MySQL directly uses disk-based temporary tables if needed, and prefers sorting to using a temporary table with a key on the GROUP BY elements. For SQL_SMALL_RESULT, MySQL uses fast temporary tables to store the resulting table instead of using sorting. This should not normally be needed.
使用外部临时表
create temporary t1(...............)engine=innodb;
MySQL 要给这个 InnoDB 表创建一个 frm 文件保存表结构定义,还要有地方保存表数据。
这个 frm 文件放在临时文件目录下,文件名的后缀是.frm,前缀是“#sql{进程 id}_{线程 id}_序列号”。可以使用 select @@tmpdir 命令,来显示实例的临时文件目录。
而关于表中数据的存放方式,在不同的 MySQL 版本中有着不同的处理方式:
- 在 5.6 以及之前的版本里,MySQL 会在临时文件目录下创建一个相同前缀、以.ibd 为后缀的文件,用来存放数据文件;
- 而从 5.7 版本开始,MySQL 引入了一个临时文件表空间,专门用来存放临时文件的数据。因此,就不需要再创建 ibd 文件了。
从文件名的前缀规则,可以看到,其实创建一个叫作 t1 的 InnoDB 临时表,MySQL 在存储上认为创建的表名跟普通表 t1 是不同的,因此同一个库下面已经有普通表 t1 的情况下,还是可以再创建一个临时表 t1 的。
举例:

这个进程的进程号是 1234,session A 的线程 id 是 4,session B 的线程 id 是 5。所以你看到了,session A 和 session B 创建的临时表,在磁盘上的文件不会重名。
MySQL 维护数据表,除了物理上要有文件外,内存里面也有一套机制区别不同的表,每个表都对应一个 table_def_key。
- 一个普通表的 table_def_key 的值是由“库名 + 表名”得到的,所以如果你要在同一个库下创建两个同名的普通表,创建第二个表的过程中就会发现 table_def_key 已经存在了。
- 而对于临时表,table_def_key 在“库名 + 表名”基础上,又加入了“server_id+thread_id”。
也就是说,session A 和 sessionB 创建的两个临时表 t1,它们的 table_def_key 不同,磁盘文件名也不同,因此可以并存。
在实现上,每个线程都维护了自己的临时表链表。这样每次 session 内操作表的时候,先遍历链表,检查是否有这个名字的临时表,如果有就优先操作临时表,如果没有再操作普通表;在 session 结束的时候,对链表里的每个临时表,执行 “DROP TEMPORARY TABLE + 表名”操作。
这时候你会发现,binlog 中也记录了 DROP TEMPORARY TABLE 这条命令。你一定会觉得奇怪,临时表只在线程内自己可以访问,为什么需要写到 binlog 里面?
MYSQL中information_schema简介
一、information_schema简介
在MySQL中,把 information_schema 看作是一个数据库,确切说是信息数据库。其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权 限等。在INFORMATION_SCHEMA中,有数个只读表。它们实际上是视图,而不是基本表,因此,你将无法看到与之相关的任何文件。
information_schema数据库表说明:
SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。
TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。
COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。
STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。
USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。
SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。
TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。
COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。
CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。
COLLATIONS表:提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。
TABLE_CONSTRAINTS表:描述了存在约束的表。以及表的约束类型。
KEY_COLUMN_USAGE表:描述了具有约束的键列。
ROUTINES表:提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。
VIEWS表:给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。
TRIGGERS表:提供了关于触发程序的信息。必须有super权限才能查看该表