MHA介绍
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中, MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中
(通过将从库提升为主库),大概0.5-2秒内即可完成
自动故障检测和自动故障转移
MHA能够在一个已经存在的复制环境中监控MySQL,当检测到Master故障后能够实现自动故障转移,通过鉴定出最“新”的Salve的relay log,并将其应用到所有的Slave,这样MHA就能够保证各个slave之间的数据一致性,即使有些slave在主库崩溃时还没有收到最新的relay log事件。一个slave节点能否成为候选的主节点可通过在配置文件中配置它的优先级。由于master能够保证各个slave之间的数据一致性,所以所有的slave节点都有希望成为主节点。在通常的replication环境中由于复制中断而极容易产生的数据一致性问题,在MHA中将不会发生。
注:在MHA的高可用环境的,主库宕机了,MHA服务将停止,如何恢复MHA服务了,需要把宕机的主库加入到高可用环境(也就是把宕机的主库变成从库)在重新启动MHA
交互式(手动)故障转移
MHA可以手动地实现故障转移,而不必去理会master的状态,即不监控master状态,确认故障发生后可通过MHA手动切换
在线切换Master到不同的主机
MHA能够在0.5-2秒内实现切换,0.5-2秒的写阻塞通常是可接受的,所以你甚至能在非维护期间就在线切换master。诸如升级到高版本,升级到更快的服务器之类的工作,将会变得更容易。
MHA优势
- 自动故障转移快
- 主库崩溃不存在数据一致性问题
- 配置不需要对当前mysql环境做重大修改
- 不需要添加额外的服务器(仅一台manager就可管理上百个replication)
- 性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
- 只要replication支持的存储引擎,MHA都支持,不会局限于innodb
MHA组成
MHA由Manager节点和Node节点组成。 MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。 MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
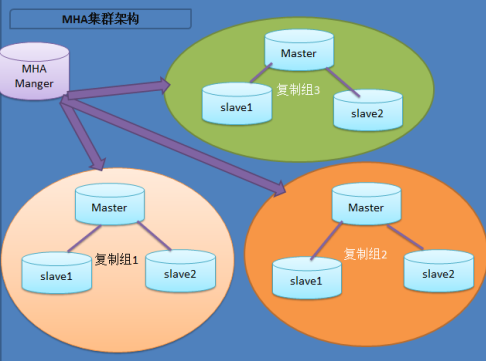
MHA工作原理
- 从宕机崩溃的master保存二进制日志事件(binlog events);
- 识别含有最新更新的slave;
- 应用差异的中继日志(relay log)到其他的slave;
- 应用从master保存的二进制日志事件(binlog events);
- 提升一个slave为新的master;
- 使其他的slave连接新的master进行复制;
MHA安装
准备四个节点,其中一个是管理节点,三个是一主两从的环境
MHA项目地址
https://code.google.com/p/mysql-master-ha/
主从环境我这已近搭建好
环境如下:
| 主机名 | ip |
| mycat01 | 10.0.0.200 |
| master01 | 10.0.0.201 |
| master02 | 10.0.0.204 |
| slave02 | 10.0.0.203 |
注:master01 是主库 master02是从库 ,slave02 是从库,一主两从
mha 管理节点需要mysql命令环境
-
在所有节点上安装node节点
yum install –y perl-DBD-MySQL
rpm -ivh mha4mysql-node-0.54-0.noarch.rpm -
在管理节点上安装manager节点
yum install -y perl-Config-Tiny
yum install -y perl-Log-Dispatch
yum install -y perl-Parallel-ForkManager
rpm -ivh mha4mysql-manager-0.55-0.el6.noarch.rpm -
在四个节点的/etc/hosts中添加主机内容:
10.0.0.200 mycat01
10.0.0.201 master01
10.0.0.204 master02
10.0.0.202 slave01 -
在管理节点创建配置文件
[root@mycat01 ~]# cat /etc/app1.cnf [server default] # mysql user and password user=root password=123456 ssh_user=root # working directory on the manager manager_workdir=/var/log/masterha/app1 # working directory on MySQL servers remote_workdir=/var/log/masterha/app1 repl_user=repl repl_password=123456 user=root ping_interval=1 remote_workdir=/tmp [server1] hostname=master01 port=3306 master_binlog_dir=/usr/local/mysql/data [server2] hostname=master02 port=3306 master_binlog_dir=/usr/local/mysql/data #candidate_master=1 #check_repl_delay=0 [server3] hostname=slave01 port=3306 master_binlog_dir=/usr/local/mysql/data
- 在所有节点的my.cnf 文件 添加一下内容
log-bin=mysql-bin relay_log_purge=0 log-slave-updates=true
添加完记得重启所有mysql环境
- 所有节点(管理节点和node节点)实现无密码登录
MHA manager通过SSH访问所有的node节点,各个node节点也同样需要通过SSH来相互发送不同的relay log 文件,所以有必要在每一个node和manager上配置SSH无密码登陆。 - 设置目录和软连接
mkdir /var/log/masterha/app1 –p #管理节点 存放mha日志
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog #所有节点
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql #所有节点
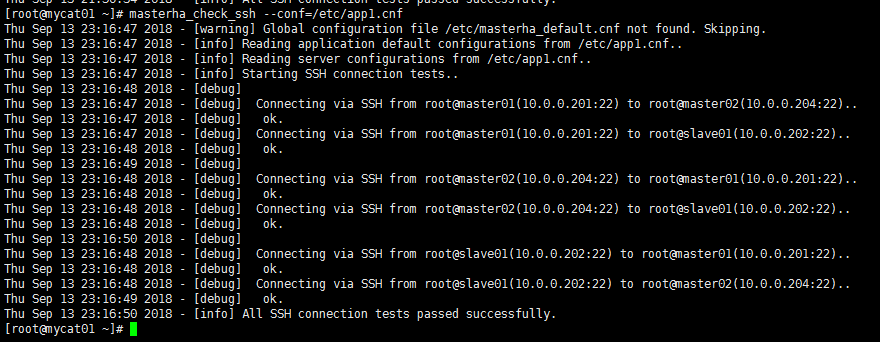
- 检测所有节点SSH连接是否配置正常
MHAmanager可通过masterha_check_ssh脚本检测SSH连接是否配置正常
masterha_check_ssh --conf=/etc/app1.cnf
- 在管理节点检查复制配置
为了让MHA正常工作,所有的master和slave必须在配置文件中正确配置,MHA可通过masterha_check_repl 脚本检测复制是否正确配置
masterha_check_repl --conf=/etc/app1.cnf
如果主从复制正常会出现
MySQL Replication Health is OK
- 开启Manager
当你正确配置了mysql复制,正确安装了manager和node节点,SSH配置也正确,那么下一步就是开启manager,可通过 masterha_manager 命令开启
nohup masterha_manager --conf=/etc/app1.cnf >/var/log/masterha/app1/mha_manager.log > /dev/null 2>&1
-
检查manager状态
当MHA manager启动监控以后,如果没有异常则不会打印任何信息。我们可通过masterha_check_status命令检查manager的状态,以下是范例#masterha_check_status --conf=/etc/app1.cnf app1 (pid:3287) is running(0:PING_OK), master:master
-
测试master的自动故障转移
现在master运行正常,manager监控也正常,下一步就是停止master,测试自动故障
转移,可以简单地停止master上的mysqld服务
[root@master01 bin]# /etc/init.d/mysql.server stop
Shutting down MySQL………… SUCCESS!
这时候检查manager的log日志,看看slave1是否成功成为新的master,并且slave2从slave1中复制。 -
查看MHA切换日志
vim /var/log/masterha/app1/mha_manager.log
Master failover to master02(10.0.0204:3306) completed successfully.
会出现迁移成功的字样。
注:有一个主库停止了服务,故障切换完毕, mha的服务也会停止
ok MHA搭建完成
MHA 配置文件介绍
cat /etc/masterha/app1.cnf [server default] manager_workdir=/var/log/masterha/app1.log //设置manager的工作目录 manager_log=/var/log/masterha/app1/manager.log //设置manager的日志 master_binlog_dir=/data/mysql //设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是 mysql的数据目录 master_ip_failover_script= /usr/local/bin/master_ip_failover //设置自动failover时候的切换脚本 master_ip_online_change_script= /usr/local/bin/master_ip_online_change //设置手动切换时候的切换脚本 password=123456 //设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码 user=root 设置监控用户root ping_interval=1 //设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover remote_workdir=/tmp //设置远端mysql在发生切换时binlog的保存位置 repl_password=123456 //设置复制用户的密码 repl_user=repl //设置复制环境中的复制用户名 report_script=/usr/local/send_report //设置发生切换后发送的报警的脚本 secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 # //一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server02 shutdown_script="" //设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用) ssh_user=root //设置ssh的登录用户名 [server1] hostname=10.0.0.201 port=3306 [server2] hostname=10.0.0.204 port=3306 candidate_master=1 //设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个 主库不是集群中事件最新的 slave check_repl_delay=0 //默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为 一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个 新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换 的过程中一定是新的master [server3] hostname=10.0.0.202 port=3306
设置relay log的清除方式(在每个slave节点上):
mysql -e ‘set global relay_log_purge=0’
注意:
MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能
MHA 手动模拟故障
mha 没有开启服务
-
先关闭两个从库的slave进程
mysql> stop slave; -
在主库上执行插入操作,而从库没办法同步
mysql> insert into temp2 values(5000,’abc’);
Query OK, 1 row affected (0.00 sec) - 主库MySQL直接关闭,两个从库开启复制进程,依旧没有最数据
[root@master01 ~]# /etc/init.d/mysql.server stop Shutting down MySQL…. SUCCESS! 从库查询刚插入的数据 mysql> select * from temp2 where id=5000; Empty set (0.00 sec)
- 开启mha进程,发现完成主从切换
查看日志
[root@mycat01 app1]# tail -10 mha_manager.log Invalidated master IP address on master01. The latest slave master02(10.0.0.204:3306) has all relay logs for recovery. Selected master02 as a new master. master02: OK: Applying all logs succeeded. master02: OK: Activated master IP address. slave01: This host has the latest relay log events. Generating relay diff files from the latest slave succeeded. slave01: OK: Applying all logs succeeded. Slave started, replicating from master02. master02: Resetting slave info succeeded. Master failover to master02(10.0.0.204:3306) completed successfully.
主库已近切换到master02了
5. 查看新的主从是否有5000这条记录
mysql> select * from temp2 where id=5000; +——+——+ | id | name | +——+——+ | 5000 | abc |
插入成功
可以通过binlog 分析
[root@master01 app1]# mysqlbinlog -v /var/log/masterha/app1/saved_master_binlog_from_master01_3306_20180909014109.binlog
MHA手动切换
手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,具体命令如下:
我还原先前的主从关系
-
先关闭mha进程,确保不会自动执行切换
[root@mycat01 ~]# masterha_stop –conf=/etc/app1.cnf -
再关闭maser主库
[root@master01 ~]# /etc/init.d/mysql.server stop
Shutting down MySQL………… SUCCESS! -
执行手动切换
[root@mycat01 ~]# masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=master01 --dead_master_port=3306 --new_master_ip=10.0.0.204 --new_master_port=3306
-
开启mha进程,可以查看日志确定是否切换成功
-
去数据库验证show slave statusG;
MHA在线切换
还原先前主从环境
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
在线切换步骤如下:
- 首先,停掉MHA监控:
[root@mycat01 ~]# masterha_stop –conf=/etc/app1.cnf - 其次,进行在线切换操作
(模拟在线切换主库操作,原主库10.0.0.201变为slave,
10.0.204提升为新的主库)
[root@mycat01 ~]# masterha_master_switch –conf=/etc/app1.cnf –master_state=alive –new_master_host=master02 –new_master_port=3306 –orig_master_is_new_slave –running_updates_limit=10000
-orig_master_is_new_slave 切换时加上此参数是将原 master 变为 slave 节点,如果不加此参数,原来的 master 将不启动
–running_updates_limit=10000,故障切换时,候选master 如果有延迟的话, mha 切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由
recover 时relay 日志的大小决定
- 去数据库验证 show slave statusG;
MHA vip漂移
记得还原先前主从环境
为什么要做vip地址 ?
简单点就是为了数据库发生故障期间,感觉不到数据库发生了故障,所以才需要vip漂移
当然这个你想用keepalive 做vip 取决于你
- 在master节点上执行ifconfig eth0:2 10.0.0.210/24
- 在管理监控节点上配置/usr/local/bin/master_ip_failover
master_ip_failover内容如下
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '10.0.0.210/24';
my $key = '2';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => $command,
'ssh_user=s' => $ssh_user,
'orig_master_host=s' => $orig_master_host,
'orig_master_ip=s' => $orig_master_ip,
'orig_master_port=i' => $orig_master_port,
'new_master_host=s' => $new_master_host,
'new_master_ip=s' => $new_master_ip,
'new_master_port=i' => $new_master_port,
);
exit &main();
sub main {
print "
IN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===
";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host
";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@
";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host
";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK
";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user@$new_master_host " $ssh_start_vip "`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user@$orig_master_host " $ssh_stop_vip "`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port
";
}
-
在监控节点的/etc/app1.cnf中添加此文件
master_ip_failover_script=/usr/local/bin/master_ip_failover -
测试当把master关机之后, VIP漂移到了新的主节点上
[root@master01 bin]# /etc/init.d/mysql.server stop
Shutting down MySQL………… SUCCESS!