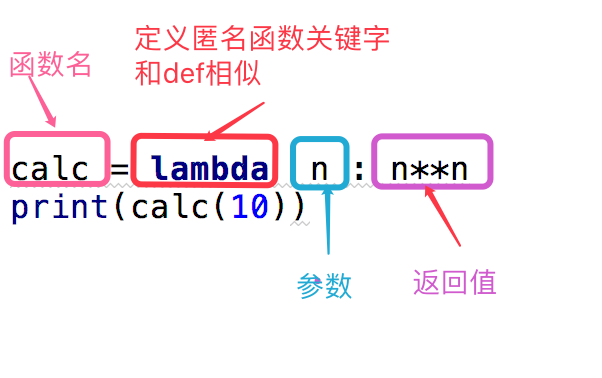
lambda匿名函数
主要是为了解决一些简单的需求而设计的一句话函数
#计算n的n次方 def func(n): return n**n print(func(3)) #27 f = lambda n : n ** n print(func(3)) #27
语法: 函数名 = lambda 参数 : 返回值
注意:
- 函数的参数可以有多个, 多个参数之间用逗号分开
- 匿名函数不管多复杂, 只能写一行, 并且逻辑结束后直接返回数据
- 返回值和正常的函数一样,可以是任意数据类型.
x = lambda a,b : a+b print(x(1,4)) #5
匿名函数lambda的函数名是a, 之所叫匿名函数是因为通过__name__查的时候用的都是统一的名字lambda,这一点和普通函数不一样
def func(n): return n*n a = lambda n : n * n print(a(5)) #25 print(func.__name__) #查看函数的名字 func print(a.__name__) #<lambda> 对比一下查到的函数名
lambda函数中的一个坑,面试很常见
普通函数 def func(x,y): return x,y print(func(1,2)) #(1,2) 返回的是一个元组, 但是通过lambda怎么实现呢? lmd1 = lambda x,y : x , y print(lmd1(1,2)) #NameError: name 'y' is not defined 结果会报错, 因为程序会把这个lambda表达式看成一个元组: 第一个元素是 lambda x,y : x 第二个元素是 y 怎么可以实现普通函数一样的结果呢 lmd2 = lambda x, y : (x,y) print(lmd2(1,2)) #(1,2)
sorted() 排序函数
语法: sorted(iterable, key=None, reverse=False)
iterable: 可迭代对象
key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数
根据函数的运算结果进行排序
reverse: 是否要倒序. True就是倒序
之前讲过普通数列的排序
lst = [11,9,23,13,43,19,8] lst.sort() #list的方法 print(lst) #[8, 9, 11, 13, 19, 23, 43]
内置函数sorted() 提供的通用的排序方法 所有的可迭代的对象都能用 lst = [11,9,23,13,43,19,8] s = sorted(lst) print(s) dic = {1:"a",3:"c",2:"b"} dic2 = sorted(dic) print(dic2) #[1, 2, 3] 对于字典返回的是key值的排序
sorted()和函数组合使用
按照字符串的长度排序 lst = ["西游记","三国演义","葫芦娃","亮剑"] def func(s): return len(s) ll = sorted(lst, key=func, reverse=True) #加上reverse就会反向排序 print(ll) #['三国演义', '西游记', '葫芦娃', '亮剑'] key是排序方案,sorted函数内部会把可迭代对象中的每一个元素拿出来交给后面的key 后面的key算出一个数字,作为当前这个元素的权重,整个函数根据权重重新排序
sorted() 和lambda配合使用
lst = [{"name":"汪峰","age":48},
{"name":"章子怡", "age":30},
{"name":"alex123","age":33}
]
def func(el):
return el["age"]
ll = sorted(lst, key=func) #和普通函数一起使用 根据年纪排序
print(ll)
#[{'name': '章子怡', 'age': 30}, {'name': 'alex', 'age': 33}, {'name': '汪峰', 'age': 48}]
l2 = sorted(lst, key=lambda el: el["age"], reverse=True) #根据年纪 倒序排列 从大到小
print(l2)
#[{'name': '汪峰', 'age': 48}, {'name': 'alex', 'age': 33}, {'name': '章子怡', 'age': 30}]
l3 = sorted(lst, key=lambda el: len(el["name"]), reverse=True) #根据名字的长度
print(l3)
#[{'name': 'alex', 'age': 33}, {'name': '章子怡', 'age': 30}, {'name': '汪峰', 'age': 48}]
filter()筛选函数
语法: filter(function, iterable)
function:用来筛选的函数. 在filter中会自动把iterable中的元素传递给函数,然后函数根据返回的True或者Fasle判断是否保留这个数
iterable: 可迭代对象
#把iterable里的每一个值传递给func,判断True 还是False, 最后把判断结果是True的返回 #把姓张的名字过滤掉 lst = ["张无忌", "张铁林", "赵一宁", "石可心","马大帅"] f = filter(lambda el: el[0] != "张",lst) # print(f) #<filter object at 0x01CE5690> # print("__iter__" in dir(f))#True 判断一下f 是不是可以迭代对象 for i in f: print(i)
结果:
赵一宁
石可心
马大帅
#当func是None的时候, 过滤出来的是可迭代对象里面的不为空的值 lst = [1,2,3,4,[],{},None] f = filter(None,lst) for i in f: print(i) 结果是 1 2 3 4
map() 映射函数
语法: map(function, iterable) 对可迭代对象中的每一个元素进行映射, 分别取值执行function
#计算相同位置的和 和zip()一样有水桶效应 根据list中元素少的那个计算求和 lst = [1,3,5,7,9] lst2 = [2,4,6,8,10] m = map(lambda x,y: x+y, lst,lst2) print(list(m)) #[3, 7, 11, 15, 19]
计算列表中每个元素的平方,返回一个新列表 print(list(map(lambda x: x * x, [1,2,3,4]))) #[1, 4, 9, 16]