0、安装jdk
1、配置hosts文件
2、建立hadoop运行账号
3、配置ssh免密码登录
4、在namenode上配置hadoop
4.1、修改hadoop-env.sh文件
4.2、修改yarn-env.sh文件
4.3、修改core-site.xml文件
4.4、修改hdfs-site.xml文件
4.5、修改mapred-site.xml文件
4.6、修改yarn-site.xml文件
5、配置masters和slaves文件
6、向各节点复制hadoop
7、格式化namenode
8、启动hadoop
9、用jps检验各后台进程是否成功启动
10、启动yarn
11、启动历史服务器
12、测试wordcount程序
附:SSH原理
安装jdk
//将jdk解压到software目录下
tar -xzvf jdk-7u79-linux-x64.tar.gz -C ../software/
//配置jdk的环境变量
[wangqi@node000 ~]$ cd ~
[wangqi@node000 ~]$ ls -al
total 36
drwx------. 4 wangqi wangqi 4096 Dec 21 10:48 .
drwxr-xr-x. 9 root root 4096 Dec 21 09:53 ..
-rw-------. 1 wangqi wangqi 18 Dec 21 09:58 .bash_history
-rw-r--r--. 1 wangqi wangqi 18 Feb 22 2013 .bash_logout
-rw-r--r--. 1 wangqi wangqi 176 Feb 22 2013 .bash_profile
-rw-r--r--. 1 wangqi wangqi 124 Feb 22 2013 .bashrc
drwxrwxr-x. 2 wangqi wangqi 4096 Dec 21 10:39 download
drwxrwxr-x. 3 wangqi wangqi 4096 Dec 21 10:42 software
-rw-------. 1 wangqi wangqi 689 Dec 21 10:48 .viminfo
//在.bash_profile中添加用户环境变量
[wangqi@node000 ~]$ vim .bash_profile
JAVA_HOME=/home/wangqi/software/jdk1.7.0_79
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/db.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME PATH CLASSPATH
//使环境变量生效
[wangqi@node000 ~]$ source .bash_profile
//验证jdk是否安装成功
[wangqi@node000 ~]$ javac -version
javac 1.7.0_79
配置hosts文件
所有的节点都需要/etc/hosts文件,使彼此之间都能把主机名解析为对应ip。
[wangqi@node000 software]$ sudo vim /etc/hosts
10.254.201.200 node000
10.254.201.201 node001
10.254.201.202 node002
这里我们有三台机器,需要在每台机器的hosts文件中配置主机名和对应的ip,使其可以相互访问。
建立hadoop运行账号
为了安全起见,最好在各个机器上建立专门用于hadoop开发的账号。
[root@node001 home]# useradd wangqi
[root@node001 home]# passwd wangqi
Changing password for user wangqi.
New password:
BAD PASSWORD: it is too short
BAD PASSWORD: is too simple
Retype new password:
passwd: all authentication tokens updated successfully.
ssh配置
在每台机器上都生成公钥私钥。
[wangqi@node000 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/wangqi/.ssh/id_rsa):
Created directory '/home/wangqi/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/wangqi/.ssh/id_rsa.
Your public key has been saved in /home/wangqi/.ssh/id_rsa.pub.
The key fingerprint is:
e3:ca:fb:16:15:6b:c1:90:ab:af:5f:b2:1e:65:e5:ab wangqi@node000
The key's randomart image is:
+--[ RSA 2048]----+
| .+ |
| . + |
| . +. |
| . +o |
| .Soo . |
| ...+ . |
| .+.. . |
| . .o= . |
| =B= E |
+-----------------+
然后把公钥放到授权key中。
[wangqi@node000 ~]$ cd .ssh
[wangqi@node000 .ssh]$ ls
id_rsa id_rsa.pub
[wangqi@node000 .ssh]$ cp id_rsa.pub authrized_keys
[wangqi@node000 .ssh]$ ls
authrized_keys id_rsa id_rsa.pub
最后把各个几点的authorized_keys的内容互相拷贝到对方的此文件中,这样就可以免密码彼此ssh登录。
在namenode上配置hadoop
1)修改hadoop-env.sh文件
[wangqi@node000 ~]$ cd software/hadoop-2.6.0/etc/hadoop/
取消JAVA_HOME注释并做如下修改:
export JAVA_HOME=/home/wangqi/software/jdk1.7.0_79
保存退出。
注:不同版本的hadoop的配置文件所在的位置可能不一样。
2)修改yarn-env.sh文件
vim etc/hadoop/yarn-env.sh
export JAVA_HOME=/home/wangqi/software/jdk1.7.0_79
3)修改core-site.xml文件
<configuration> <property> <name>fs.default.name</name> <value>hdfs://node000:10000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///home/wangqi/software/hadoop-2.6.0/tmp</value> </property> </configuration>
注:
1、fs.default.name表示namenode的IP地址和监听端口。namenode与datanode之间的通信就是通过该端口来完成的。
2、hadoop.tmp.dir 表示hadoop的临时文件存储目录
3、hadoop.tmp.dir中指定的tmp文件夹不用自己创建,格式化namenode时会自动创建
4)修改hdfs-site.xml文件
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node000:40090</value> <description>namenode get the newest fsimage via dfs.secondary.http-address</description> </property> <property> <name>dfs.namenode.http-address</name> <value>node000:40070</value> <description>secondary get fsimage and edits via dfs.namenode.http-address</description> </property> <property> <name> dfs.namenode.name.dir </name> <value>file:///home/wangqi/software/hadoop-2.6.0/hdfs/name</value> <description>the place where store the namenode</description> </property> <property> <name> dfs.datanode.data.dir </name> <value>file:///home/wangqi/software/hadoop-2.6.0/hdfs/data</value> <description>the place where store the datanode</description> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
注:
1、dfs.namenode.secondary.http-address表示辅助名称节点http服务的地址和端口。
2、dfs.namenode.http-address表示名称节点web ui监听地址和端口。
3、dfs.namenode.name.dir表示名称节点所使用的元数据的保存路径。
4、dfs.datanode.data.dir表示数据节点存储数据块的路径,可以写多块硬盘,逗号分隔。把这些位置分散在每个节点上的所有磁盘上可以实现磁盘I/O平衡,会显著改进磁盘I/O性能。
5、dfs.replication表示hdfs数据块的复制份数,默认3,理论上份数越多跑数速度越快,但是需要的存储空间也更多。因为我们现在是伪分布式,即只有一个节点,因此只能复制一份。
说明:
1、路径应该写成file://的格式。
2、这里配置的dfs.namenode.secondary.http-address和dfs.namenode.http-address都有默认配置,我是因为机器上有其他人已经部署了hadoop,为了防止端口被占用,因此显示指定了。
3、dfs.namenode.name.dir和dfs.datanode.data.dir我们显示指定时,需要保证其中hdfs这一级目录已经创建(name和data这一级目录不用创建,格式化namenode时会自动创建name目录,启动dfs时会自动创建data目录)。
5)修改mapred-site.xml文件
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.address</name> <value>node000:60040</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>node000:60030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node000:60020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node000:60888</value> </property> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/tmp/hadoop-yarn/staging</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value> </property> </configuration>
注:
1、mapreduce.framework.name表示执行mapreduce任务时的运行时框架。
2、mapreduce.jobtracker.address表示jobtracker的ip地址和端口号
2、mapreduce.jobtracker.http.address表示jobtracker的http服务的ip地址和端口号。
3、mapreduce.jobhistory.address表示MapReduce JobHistory服务器进程间通信(IPC)的主机和端口号。
4、mapreduce.jobhistory.webapp.address表示MapReduce JobHistory服务器Web UI 的主机和端口号。
5、yarn.app.mapreduce.am.staging-dir表示提交的job的暂存目录。
6、mapreduce.jobhistory.done-dir表示在什么目录下存放已经运行完的Hadoop作业记录。
7、mapreduce.jobhistory.intermediate-done-dir表示在什么目录下存放正在运行的Hadoop作业记录。
6)修改yarn-site.xml文件
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node001:9032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node001:9030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node001:9031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node001:9033</value> </property> <property> <name> yarn.resourcemanager.webapp.address </name> <value>node001:9088</value> </property> </configuration>
注:
1、yarn.resourcemanager.webapp.address表示RM web应用的http地址和端口。
修改masters和slaves文件
[wangqi@node000 sbin]$ vim ~/software/hadoop-2.6.0/etc/hadoop/masters
node000
[wangqi@node000 sbin]$ vim ~/software/hadoop-2.6.0/etc/hadoop/slaves
node001
node002
注:
1、masters文件中指定的是secondary namenode的主机名,不是namenode
将配置好的hadoop发送到从节点
[wangqi@node000 sbin]$ scp -r ~/software/hadoop-2.6.0/
wangqi@10.254.201.201:~/software/
[wangqi@node000 sbin]$ scp -r ~/software/hadoop-2.6.0/
wangqi@10.254.201.202:~/software/
另外,因为我这边的机器上,其他人已经部署了hadoop,为了防止端口被占用,还需要修改各从节点中的hdfs-site.xml文件。(如果机器上没有其他人部署了hadoop,则省略这步操作)
1)修改从节点201中的hdfs-site.xml文件
将从节点201的hdfs-site.xml文件修改如下:
[wangqi@node001 software]$ vim hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node000:40090</value> <description>namenode get the newest fsimage via dfs.secondary.http-address</description> </property> <property> <name>dfs.namenode.http-address</name> <value>node000:40070</value> <description>secondary get fsimage and edits via dfs.namenode.http-address</description> </property> <property> <name>dfs.name.dir</name> <value>file:///home/wangqi/software/hadoop-2.6.0/hdfs/name</value> <description>the place where store the namenode</description> </property> <property> <name>dfs.data.dir</name> <value>file:///home/wangqi/software/hadoop-2.6.0/hdfs/data</value> <description>the place where store the datanode</description> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.datanode.address</name> <value>node001:60010</value> </property> <property> <name>dfs.datanode.http.address</name> <value>node001:60075</value> </property> <property> <name>dfs.datanode.ipc.address</name> <value>node001:60020</value> </property> </configuration>
注:
1、dfs.datanode.address表示数据节点传输数据时的地址和端口。
2、dfs.datanode.http.address表示数据节点http服务的地址和端口。
3、dfs.datanode.ipc.address表示数据节点IPC(进程间通信)服务地址和端口。
2)修改从节点202中的hdfs-site.xml文件
对从节点202中hdfs-site.xml文件的修改和上面一样,只是把node001修改成了node002,如下:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node000:40090</value> <description>namenode get the newest fsimage via dfs.secondary.http-address</description> </property> <property> <name>dfs.namenode.http-address</name> <value>node000:40070</value> <description>secondary get fsimage and edits via dfs.namenode.http-address</description> </property> <property> <name>dfs.name.dir</name> <value>file:///home/wangqi/software/hadoop-2.6.0/hdfs/name</value> <description>the place where store the namenode</description> </property> <property> <name>dfs.data.dir</name> <value>file:///home/wangqi/software/hadoop-2.6.0/hdfs/data</value> <description>the place where store the datanode</description> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.datanode.address</name> <value>node002:60010</value> </property> <property> <name>dfs.datanode.http.address</name> <value>node002:60075</value> </property> <property> <name>dfs.datanode.ipc.address</name> <value>node002:60020</value> </property> </configuration>
格式化分布式文件系统
[wangqi@node000 bin]$ ./hadoop namenode -format
或者
[wangqi@node000 bin]$ ./hdfs namenode -format
15/12/28 12:12:06 INFO common.Storage: Storage directory
/home/wangqi/software/hadoop-2.6.0/hdfs/name has been successfully formatted.
15/12/28 12:12:06 INFO namenode.NNStorageRetentionManager: Going to retain 1 images
with txid >= 0
15/12/28 12:12:06 INFO util.ExitUtil: Exiting with status 0
15/12/28 12:12:06 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node001/10.254.201.201
************************************************************/
启动hdfs
[wangqi@node000 sbin]$ ./start-dfs.sh
15/12/25 15:51:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [node000]
node000: starting namenode, logging to
/home/wangqi/software/hadoop-2.6.0/logs/hadoop-wangqi-namenode-node000.out
node001: starting datanode, logging to
/home/wangqi/software/hadoop-2.6.0/logs/hadoop-wangqi-datanode-node001.out
node002: starting datanode, logging to
/home/wangqi/software/hadoop-2.6.0/logs/hadoop-wangqi-datanode-node002.out
Starting secondary namenodes [node000]
node000: starting secondarynamenode, logging to
/home/wangqi/software/hadoop-2.6.0/logs/hadoop-wangqi-secondarynamenode-node000.out
15/12/25 15:51:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
检测守护进程启动情况
[wangqi@node000 sbin]$ jps
100266 Jps
99858 NameNode
100092 SecondaryNameNode
[wangqi@node001 software]$ jps
39666 DataNode
39759 Jps
[wangqi@node002 software]$ jps
239950 Jps
239858 DataNode
启动yarn
[wangqi@node000 sbin]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/wangqi/software/hadoop-2.6.0/logs/yarn-wangqi-resourcemanager-node000.out
node001: starting nodemanager, logging to
/home/wangqi/software/hadoop-2.6.0/logs/yarn-wangqi-nodemanager-node001.out
node002: starting nodemanager, logging to
/home/wangqi/software/hadoop-2.6.0/logs/yarn-wangqi-nodemanager-node002.out
[wangqi@node000 sbin]$ jps
11901 ResourceManager
12176 Jps
11437 NameNode
11663 SecondaryNameNode
[wangqi@node001 hadoop-2.6.0]$ jps
5520 Jps
5166 DataNode
5323 NodeManager
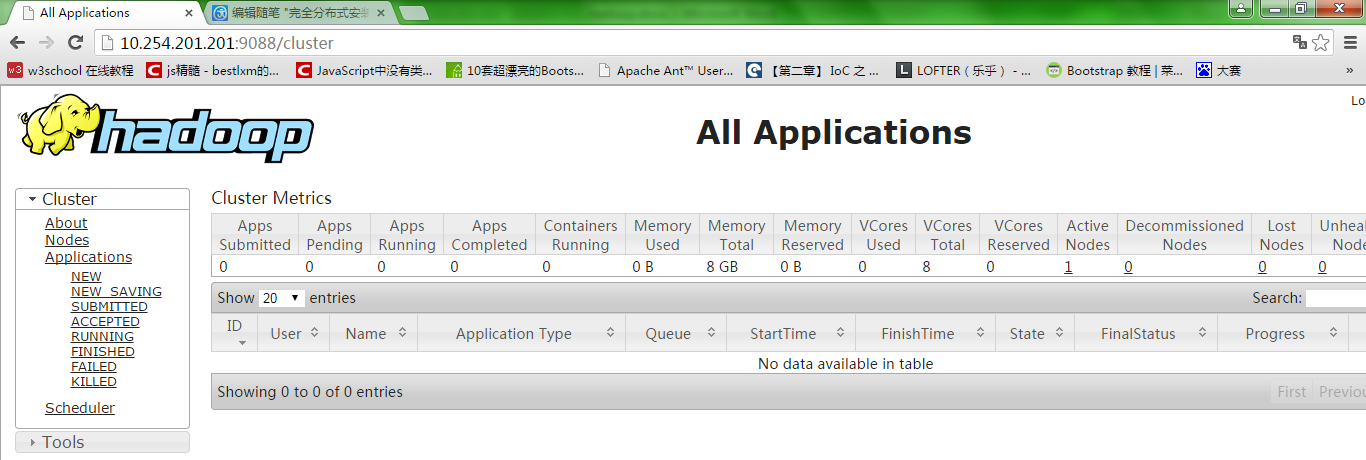
此时hadoop集群已全部部署完成。
在浏览器中输入:http://10.254.201.201:9088/,结果如下:
启动历史服务器
[wangqi@node001 sbin]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to
/home/wangqi/software/hadoop-2.6.0/logs/mapred-wangqi-historyserver-node001.out
测试WordCount程序
1、在hdfs上创建input目录
[wangqi@node001 input]$ hdfs dfs -mkdir -p /user/wangqi/in
[wangqi@node001 input]$ hdfs dfs -ls -R /
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:14 /user
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:14 /user/wangqi
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:14 /user/wangqi/in
注:一定要创建成/user/wangqi/in(其中wangqi是创建的用户),因为后面执行mapreduce任务时,会在user/wangqi目录下找in目录,否则会报错:
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://node001:10000/user/wangqi/input
2、在本机上创建input目录,并写入两个文件
[wangqi@node001 ~]$ mkdir input
[wangqi@node001 input]$ echo "hello world" > test1.txt
[wangqi@node001 input]$ echo "hello hadoop" > test2.txt
[wangqi@node001 input]$ cat test1.txt
hello world
[wangqi@node001 input]$ cat test2.txt
hello hadoop
3、将文件上传到hadoop的input目录下
[wangqi@node001 input]$ hdfs dfs -put ./* /user/wangqi/in/
[wangqi@node001 input]$ hdfs dfs -ls -R /
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:14 /user
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:14 /user/wangqi
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:17 /user/wangqi/in
-rw-r--r-- 2 wangqi supergroup 12 2015-12-28 16:17 /user/wangqi/in/test1.txt
-rw-r--r-- 2 wangqi supergroup 13 2015-12-28 16:17 /user/wangqi/in/test2.txt
4、运行示例程序WordCount
[wangqi@node001 input]$ hadoop jar /home/wangqi/software/hadoop-2.6.0/share/hadoop/mapreduce/sources/hadoop-mapreduce-exampls-2.6.0-sources.jar org.apache.hadoop.examples.WordCount in out
15/12/28 16:18:39 INFO client.RMProxy: Connecting to ResourceManager at
node001/10.254.201.201:9032
15/12/28 16:18:40 INFO input.FileInputFormat: Total input paths to process : 2
15/12/28 16:18:40 INFO mapreduce.JobSubmitter: number of splits:2
15/12/28 16:18:40 INFO mapreduce.JobSubmitter: Submitting tokens for job:
job_1451286103870_0007
15/12/28 16:18:40 INFO impl.YarnClientImpl: Submitted application
application_1451286103870_0007
15/12/28 16:18:40 INFO mapreduce.Job: The url to track the job:
http://node001:9088/proxy/application_1451286103870_0007/
15/12/28 16:18:40 INFO mapreduce.Job: Running job: job_1451286103870_0007
15/12/28 16:18:47 INFO mapreduce.Job: Job job_1451286103870_0007 running in uber
mode : false
15/12/28 16:18:47 INFO mapreduce.Job: map 0% reduce 0%
15/12/28 16:18:53 INFO mapreduce.Job: map 100% reduce 0%
15/12/28 16:18:59 INFO mapreduce.Job: map 100% reduce 100%
15/12/28 16:18:59 INFO mapreduce.Job: Job job_1451286103870_0007 completed
successfully
15/12/28 16:19:00 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=55
FILE: Number of bytes written=317236
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=245
HDFS: Number of bytes written=25
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=7461
Total time spent by all reduces in occupied slots (ms)=3882
Total time spent by all map tasks (ms)=7461
Total time spent by all reduce tasks (ms)=3882
Total vcore-seconds taken by all map tasks=7461
Total vcore-seconds taken by all reduce tasks=3882
Total megabyte-seconds taken by all map tasks=7640064
Total megabyte-seconds taken by all reduce tasks=3975168
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=41
Map output materialized bytes=61
Input split bytes=220
Combine input records=4
Combine output records=4
Reduce input groups=3
Reduce shuffle bytes=61
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=94
CPU time spent (ms)=3510
Physical memory (bytes) snapshot=698580992
Virtual memory (bytes) snapshot=2897805312
Total committed heap usage (bytes)=603979776
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=25
File Output Format Counters
Bytes Written=25
5、查看结果
[wangqi@node001 input]$ hdfs dfs -ls -R /
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:14 /user
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:18 /user/wangqi
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:17 /user/wangqi/in
-rw-r--r-- 2 wangqi supergroup 12 2015-12-28 16:17 /user/wangqi/in/test1.txt
-rw-r--r-- 2 wangqi supergroup 13 2015-12-28 16:17 /user/wangqi/in/test2.txt
drwxr-xr-x - wangqi supergroup 0 2015-12-28 16:18 /user/wangqi/out
-rw-r--r-- 2 wangqi supergroup 0 2015-12-28 16:18
/user/wangqi/out/_SUCCESS
-rw-r--r-- 2 wangqi supergroup 25 2015-12-28 16:18
/user/wangqi/out/part-r-00000
[wangqi@node001 input]$ hdfs dfs -cat /user/wangqi/out/part-r-00000
hadoop 1
hello 2
world 1
异常处理
Got exception: org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1451316339594 found 1451288164469
Note: System times on machines may be out of sync. Check system time and time zones.
这是因为datanode与namenode之间未设置时间同步,所以引起该异常。解决方案是将多个datanode与namenode进行时间同步,即在每个服务器上执行ntpdate time.nist.gov命令,如下:
[wangqi@node002 ~]$ sudo ntpdate time.nist.gov
附:SSH原理
为了更好的理解SSH免密码登录原理,我们先来说说SSH的安全验证,SSH采用的是”非对称密钥系统”,即耳熟能详的公钥私钥加密系统,其安全验证又分为两种级别。
1. 基于口令的安全验证
这种方式使用用户名密码进行联机登录,一般情况下我们使用的都是这种方式。整个过程大致如下:
(1)客户端发起连接请求。
(2)远程主机收到用户的登录请求,把自己的公钥发给客户端。
(3)客户端接收远程主机的公钥,然后使用远程主机的公钥加密登录密码,发送给远程主机。
(4)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
在linux上,如果你是第一次登录对方主机,系统会出现下面的提示:
The authenticity of host '10.254.201.202 (10.254.201.202)' can't be established.
RSA key fingerprint is a6:fb:54:f6:ae:54:dd:c3:23:12:c8:2d:ca:d6:3f:12.
这段话的意思是,无法确认host主机的真实性,只知道它的公钥指纹,问你还想继续连接吗?
所谓"公钥指纹",是指公钥长度较长(这里采用RSA算法,长达1024位),很难比对,所以对其进行MD5计算,将它变成一个128位的指纹再进行比较,就容易多了,上例中的是a6:fb:54:f6:ae:54:dd:c3:23:12:c8:2d:ca:d6:3f:12。
很自然的一个问题就是,用户怎么知道远程主机的公钥指纹应该是多少?回答是没有好办法,远程主机必须在自己的网站上贴出公钥指纹,以便用户自行核对。
假定经过风险衡量以后,用户决定接受这个远程主机的公钥。
Are you sure you want to continue connecting (yes/no)? yes
系统会出现一句提示,表示10.254.201.202主机已经得到认可。
Warning: Permanently added '10.254.201.202' (RSA) to the list of known hosts.
然后,会要求输入密码。
wangqi@10.254.201.202's password:
如果密码正确,就可以登录了。
当远程主机的公钥被接受以后,它就会被保存在文件$HOME/.ssh/known_hosts之中。下次再连接这台主机,系统就会认出它的公钥已经保存在本地了,从而跳过警告部分,直接提示输入密码。
每个SSH用户都有自己的known_hosts文件,分别在自己的$HOME目录下,此外操作系统也有一个这样的文件,通常是/etc/ssh/ssh_known_hosts,保存一些对所有用户都可信赖的远程主机的公钥。
注:当网络中有另一台冒牌服务器冒充远程主机时,客户端的连接请求被服务器B拦截,服务器B将自己的公钥发送给客户端,客户端就会将密码加密后发送给冒牌服务器,冒牌服务器就可以拿自己的私钥获取到密码,然后为所欲为。因此当第一次链接远程主机时,在上述步骤的第(3)步中,会提示您当前远程主机的”公钥指纹”,以确认远程主机是否是正版的远程主机,如果选择继续后就可以输入密码进行登录了,当远程的主机接受以后,该台服务器的公钥就会保存到 ~/.ssh/known_hosts文件中。
2. 基于公钥的安全验证
使用密码登录,每次都必须输入密码,非常麻烦。好在SSH还提供了公钥登录,可以省去输入密码的步骤。
所谓"公钥登录",原理很简单,就是用户将自己的公钥储存在远程主机上。登录的时候,远程主机会向用户发送一段随机字符串,用户用自己的私钥加密后,再发回来。远程主机用事先储存的公钥进行解密,如果成功,就证明用户是可信的,直接允许登录shell,不再要求输入密码,这和之前的ssh账号密码也没有直接关系。
这种方法要求用户必须提供自己的公钥。如果没有现成的,可以直接用ssh-keygen生成一个:
$ ssh-keygen
运行上面的命令以后,系统会出现一系列提示,可以一路回车。其中有一个问题是,要不要对私钥设置口令(passphrase),如果担心私钥的安全,这里可以设置一个。
运行结束以后,在$HOME/.ssh/目录下,会新生成两个文件:id_rsa.pub和id_rsa。前者是你的公钥,后者是你的私钥。
这时再输入下面的命令,将公钥传送到远程主机host上面:
scp id_rsa.pub wangqi@10.254.201.202:~/
好了,从此你再登录远程主机,就不需要输入密码了。
如果还是不行,就打开远程主机的/etc/ssh/sshd_config这个文件,检查下面几行前面"#"注释是否取掉。
RSAAuthentication yes
PubkeyAuthentication yes #是否允许使用公钥验证方式登录
AuthorizedKeysFile .ssh/authorized_keys #允许登录的主机的公钥存放文件,默认为用#户家目录下的.ssh/authorized_keys
然后,重启远程主机的ssh服务。
3.关于authorized_keys文件
远程主机将用户的公钥,保存在登录后的用户主目录的$HOME/.ssh/authorized_keys文件中。公钥就是一段字符串,只要把它追加在authorized_keys文件的末尾就行了。
如果不使用上面的ssh-copy-id命令,改用下面的命令也可以:
# scp -P 22 id_rsa.pub root@192.168.1.77:/root/.ssh/authorized_keys
root@192.168.1.77's password: <-- 输入机器Server的root用户密码
id_rsa.pub 100% 218 0.2KB/s 00:00
如果远程主机的authorized_keys文件已经存在,也可以往里添加公钥:
先将公钥文件上传到远程主机中,
#scp -P 22 ~/.ssh/id_rsa.pub root@192.168.1.91:/root/
SSH到登陆到远程主机,将公钥追加到 authorized_keys 文件中
cat /root/id_rsa.pub >> /root/.ssh/authorized_keys
或直接运行命令:
cat ~/.ssh/id_dsa.pub|ssh -p 22 root@192.168.1.91 `cat - >> ~/.ssh/authorized_keys`
写入authorized_keys文件后,公钥登录的设置就完成了。
Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程。以namenode到datanode为例子:Namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。当namenode通过ssh连接datanode时,datanode就会生成一个随机数并发送给namenode。namenode收到随机数之后再用私钥进行加密,并将加密数回传给datanode,datanode用公钥解密成功后就允许namenode进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端namenode公钥复制到datanode上。