为什么需要一致性哈希
Hash,一般翻译做散列,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
在分布式缓存服务中,经常需要对服务进行节点添加和删除操作,我们希望的是节点添加和删除操作尽量减少数据-节点之间的映射关系更新。
假如我们使用的是哈希取模( hash(key)%nodes ) 算法作为路由策略:
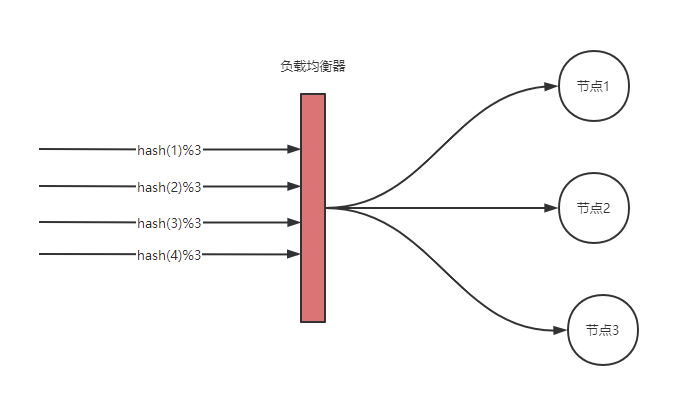
哈希取模的缺点在于如果有节点的删除和添加操作,对 hash(key)%nodes 结果影响范围太大了,造成大量的请求无法命中从而导致缓存数据被重新加载。
基于上面的缺点提出了一种新的算法:一致性哈希。一致性哈希可以实现节点删除和添加只会影响一小部分数据的映射关系,由于这个特性哈希算法也常常用于各种均衡器中实现系统流量的平滑迁移。
一致性哈希工作原理
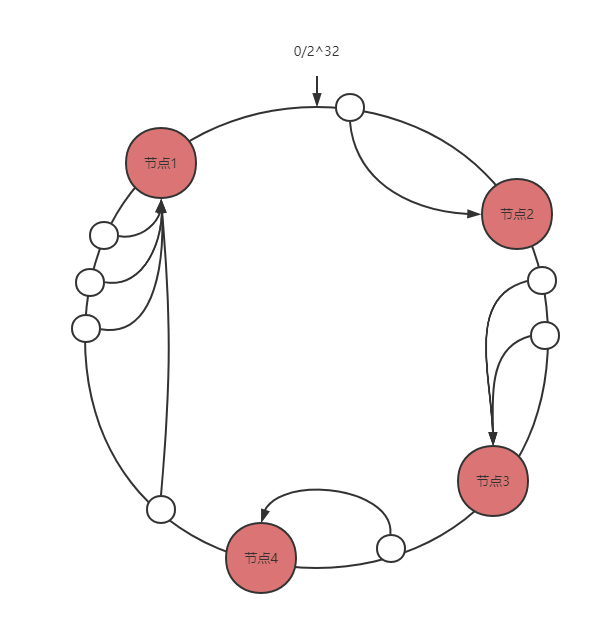
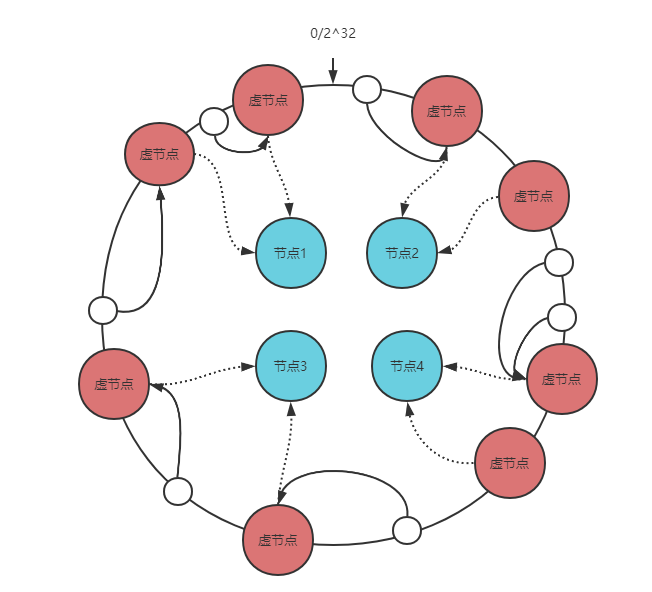
首先对节点进行哈希计算,哈希值通常在 2^32-1 范围内。然后将 2^32-1 这个区间首尾连接抽象成一个环并将节点的哈希值映射到环上,当我们要查询 key 的目标节点时,同样的我们对 key 进行哈希计算,然后顺时针查找到的第一个节点就是目标节点。
根据原理我们分析一下节点添加和删除对数据范围的影响。
-
节点添加
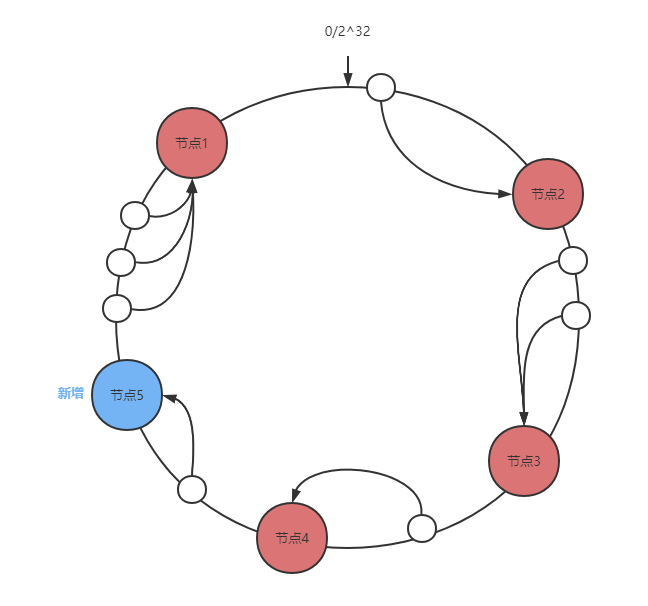
只会影响新增节点与前一个节点(新增节点逆时针查找的第一个节点)之间的数据。
-
节点删除
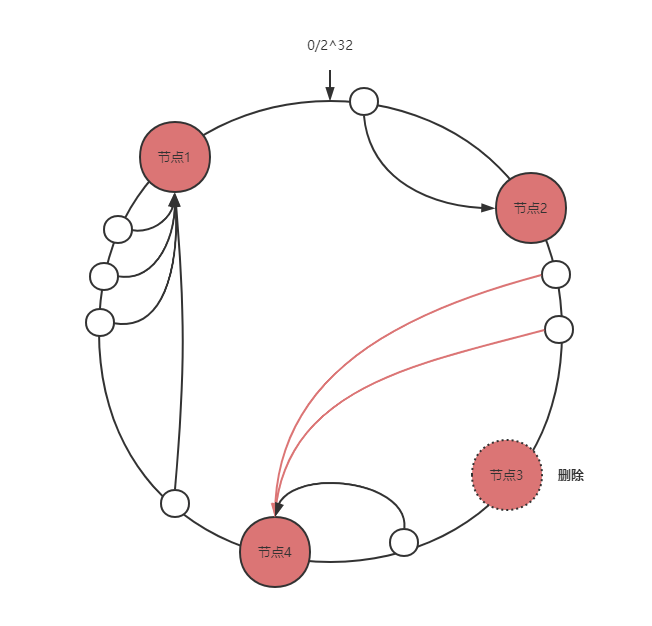
只会影响删除节点与前一个节点(删除节点逆时针查找的第一个节点)之间的数据。
这样就完了吗?还没有,试想一下假如环上的节点数量非常少,那么非常有可能造成数据分布不平衡,本质上是环上的区间分布粒度太粗。
怎么解决呢?不是粒度太粗吗?那就加入更多的节点,这就引出了一致性哈希的虚拟节点概念,虚拟节点的作用在于让环上的节点区间分布粒度变细。
一个真实节点对应多个虚拟节点,将虚拟节点的哈希值映射到环上,查询 key 的目标节点我们先查询虚拟节点再找到真实节点即可。
代码实现
基于上面的一致性哈希原理,我们可以提炼出一致性哈希的核心功能:
- 添加节点
- 删除节点
- 查询节点
我们来定义一下接口:
ConsistentHash interface {
Add(node Node)
Get(key Node) Node
Remove(node Node)
}
现实中不同的节点服务能力因硬件差异可能各不相同,于是我们希望在添加节点时可以指定权重。反应到一致性哈希当中所谓的权重意思就是我们希望 key 的目标节点命中概率比例,一个真实节点的虚拟节点数量多则意味着被命中概率高。
在接口定义中我们可以增加两个方法:支持指定虚拟节点数量添加节点,支持按权重添加。本质上最终都会反应到虚拟节点的数量不同导致概率分布差异。
指定权重时:实际虚拟节点数量 = 配置的虚拟节点 * weight/100
ConsistentHash interface {
Add(node Node)
AddWithReplicas(node Node, replicas int)
AddWithWeight(node Node, weight int)
Get(key Node) Node
Remove(node Node)
}
接下来考虑几个工程实现的问题:
-
虚拟节点如何存储?
很简单,用列表(切片)存储即可。
-
虚拟节点 - 真实节点关系存储
map 即可。
-
顺时针查询第一个虚拟节点如何实现
让虚拟节点列表保持有序,二分查找第一个比 hash(key) 大的 index,list[index] 即可。
-
虚拟节点哈希时会有很小的概率出现冲突,如何处理呢?
冲突时意味着这一个虚拟节点会对应多个真实节点,map 中 value 存储真实节点数组,查询 key 的目标节点时对 nodes 取模。
-
如何生成虚拟节点
基于虚拟节点数量配置 replicas,循环 replicas 次依次追加 i 字节 进行哈希计算。
go-zero 源码解析
core/hash/consistenthash.go
花了一天时间把 go-zero 源码一致性哈希源码看完,写的真好啊,各种细节都考虑到了。
go-zero 使用的哈希函数是 MurmurHash3,GitHub:https://github.com/spaolacci/murmur3
go-zero 并没有进行接口定义,没啥关系,直接看结构体 ConsistentHash:
// Func defines the hash method.
// 哈希函数
Func func(data []byte) uint64
// A ConsistentHash is a ring hash implementation.
// 一致性哈希
ConsistentHash struct {
// 哈希函数
hashFunc Func
// 确定node的虚拟节点数量
replicas int
// 虚拟节点列表
keys []uint64
// 虚拟节点到物理节点的映射
ring map[uint64][]interface{}
// 物理节点映射,快速判断是否存在node
nodes map[string]lang.PlaceholderType
// 读写锁
lock sync.RWMutex
}
key 和虚拟节点的哈希计算
在进行哈希前要先将 key 转换成 string
// 可以理解为确定node字符串值的序列化方法
// 在遇到哈希冲突时需要重新对key进行哈希计算
// 为了减少冲突的概率前面追加了一个质数prime来减小冲突的概率
func innerRepr(v interface{}) string {
return fmt.Sprintf("%d:%v", prime, v)
}
// 可以理解为确定node字符串值的序列化方法
// 如果让node强制实现String()会不会更好一些?
func repr(node interface{}) string {
return mapping.Repr(node)
}
这里 mapping.Repr 里会判断 fmt.Stringer 接口,如果符合,就会调用其 String 方法。go-zero 代码如下:
// Repr returns the string representation of v.
func Repr(v interface{}) string {
if v == nil {
return ""
}
// if func (v *Type) String() string, we can't use Elem()
switch vt := v.(type) {
case fmt.Stringer:
return vt.String()
}
val := reflect.ValueOf(v)
if val.Kind() == reflect.Ptr && !val.IsNil() {
val = val.Elem()
}
return reprOfValue(val)
}
添加节点
最终调用的是 指定虚拟节点添加节点方法
// 扩容操作,增加物理节点
func (h *ConsistentHash) Add(node interface{}) {
h.AddWithReplicas(node, h.replicas)
}
添加节点 - 指定权重
最终调用的同样是 指定虚拟节点添加节点方法
// 按权重添加节点
// 通过权重来计算方法因子,最终控制虚拟节点的数量
// 权重越高,虚拟节点数量越多
func (h *ConsistentHash) AddWithWeight(node interface{}, weight int) {
replicas := h.replicas * weight / TopWeight
h.AddWithReplicas(node, replicas)
}
添加节点 - 指定虚拟节点数量
// 扩容操作,增加物理节点
func (h *ConsistentHash) AddWithReplicas(node interface{}, replicas int) {
// 支持可重复添加
// 先执行删除操作
h.Remove(node)
// 不能超过放大因子上限
if replicas > h.replicas {
replicas = h.replicas
}
// node key
nodeRepr := repr(node)
h.lock.Lock()
defer h.lock.Unlock()
// 添加node map映射
h.addNode(nodeRepr)
for i := 0; i < replicas; i++ {
// 创建虚拟节点
hash := h.hashFunc([]byte(nodeRepr + strconv.Itoa(i)))
// 添加虚拟节点
h.keys = append(h.keys, hash)
// 映射虚拟节点-真实节点
// 注意hashFunc可能会出现哈希冲突,所以采用的是追加操作
// 虚拟节点-真实节点的映射对应的其实是个数组
// 一个虚拟节点可能对应多个真实节点,当然概率非常小
h.ring[hash] = append(h.ring[hash], node)
}
// 排序
// 后面会使用二分查找虚拟节点
sort.Slice(h.keys, func(i, j int) bool {
return h.keys[i] < h.keys[j]
})
}
删除节点
// 删除物理节点
func (h *ConsistentHash) Remove(node interface{}) {
// 节点的string
nodeRepr := repr(node)
// 并发安全
h.lock.Lock()
defer h.lock.Unlock()
// 节点不存在
if !h.containsNode(nodeRepr) {
return
}
// 移除虚拟节点映射
for i := 0; i < h.replicas; i++ {
// 计算哈希值
hash := h.hashFunc([]byte(nodeRepr + strconv.Itoa(i)))
// 二分查找到第一个虚拟节点
index := sort.Search(len(h.keys), func(i int) bool {
return h.keys[i] >= hash
})
// 切片删除对应的元素
if index < len(h.keys) && h.keys[index] == hash {
// 定位到切片index之前的元素
// 将index之后的元素(index+1)前移覆盖index
h.keys = append(h.keys[:index], h.keys[index+1:]...)
}
// 虚拟节点删除映射
h.removeRingNode(hash, nodeRepr)
}
// 删除真实节点
h.removeNode(nodeRepr)
}
// 删除虚拟-真实节点映射关系
// hash - 虚拟节点
// nodeRepr - 真实节点
func (h *ConsistentHash) removeRingNode(hash uint64, nodeRepr string) {
// map使用时应该校验一下
if nodes, ok := h.ring[hash]; ok {
// 新建一个空的切片,容量与nodes保持一致
newNodes := nodes[:0]
// 遍历nodes
for _, x := range nodes {
// 如果序列化值不相同,x是其他节点
// 不能删除
if repr(x) != nodeRepr {
newNodes = append(newNodes, x)
}
}
// 剩余节点不为空则重新绑定映射关系
if len(newNodes) > 0 {
h.ring[hash] = newNodes
} else {
// 否则删除即可
delete(h.ring, hash)
}
}
}
查询节点
// 根据v顺时针找到最近的虚拟节点
// 再通过虚拟节点映射找到真实节点
func (h *ConsistentHash) Get(v interface{}) (interface{}, bool) {
h.lock.RLock()
defer h.lock.RUnlock()
// 当前没有物理节点
if len(h.ring) == 0 {
return nil, false
}
// 计算哈希值
hash := h.hashFunc([]byte(repr(v)))
// 二分查找
// 因为每次添加节点后虚拟节点都会重新排序
// 所以查询到的第一个节点就是我们的目标节点
// 取余则可以实现环形列表效果,顺时针查找节点
index := sort.Search(len(h.keys), func(i int) bool {
return h.keys[i] >= hash
}) % len(h.keys)
// 虚拟节点->物理节点映射
nodes := h.ring[h.keys[index]]
switch len(nodes) {
// 不存在真实节点
case 0:
return nil, false
// 只有一个真实节点,直接返回
case 1:
return nodes[0], true
// 存在多个真实节点意味这出现哈希冲突
default:
// 此时我们对v重新进行哈希计算
// 对nodes长度取余得到一个新的index
innerIndex := h.hashFunc([]byte(innerRepr(v)))
pos := int(innerIndex % uint64(len(nodes)))
return nodes[pos], true
}
}
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。