来自:Python数据分析与挖掘实战——张良均著
1. 分析方法与过程
本次建模针对京东商城上“美的”品牌热水器的消费者评论数据,在对文本进行基本的机器预处理、中文分词、停用词过滤后,通过建立包括栈式自编码深度学习、语义网络与LDA主题模型等多种数据挖掘模型,实现对文本评论数据的倾向性判断以及所隐藏的信息的挖掘并分析,得到有价值的内在内容。
2. 评论数据预处理
文本数据的预处理主要由3个部分组成:文本去重、机械压缩去词、短句删除。
2.1 文本去重
1. 文本去重,就是去除文本评论数据中重复的部分。
去重的原因:
(1). 一些电商平台避免客户长时间不评论,设置一道程序,用户超过规定时间不评论,系统会自动评论。(比如国美)
(2). 同一个人出现重复评论,比如:同一个人购买多种热水器为了省事,复制粘贴,就会出现在同样或相近的评论,当然不乏有价值的评论,但只是第一条有作用。
(3). 由于语言的特点,大多数情况下,不同人之间有价值的评论不会出现重复,比如:“好好好好好好”,“XX牌热水器 XX升”或者复制、粘贴上一个人的评论,这种评论显然就只有最早评论才有意义(即第一条)
2. 常见文本去重算法及缺陷
许多文本去重算法通过计算文本之间的相似度,以此为基础去重,包括编辑距离去重、Simhash算法去重等。
编辑距离算法去重是计算两条语料的编辑距离,然后进行阈值判断,如果编辑距离小于阈值则进行去重处理。
比如:"XX 牌热水器 XX升 大品牌高质扯“ 以及 "XX牌热水器 XX升 大品牌 高质扯 用起来真的不错" 的接近重复而又无任何意义的评论,去除的效果是很好的。
但是 有相近的表达的时候就可能也会采取删除操作, 这样就会造成错删。
比如:”还没正式使用, 不知道怎样, 但安装的材料费确实有点高,380" 以及 “还没使用, 不知道质掀如何, 但安装的材料费确实贵,380"。 这组语句的编辑距离只是比上一组大2而已, 但是 很明显这两句都是有意义的, 如果阔值设为10 (该组为9), 就会带来错删问题。
3. 文本去重选用的方法及原因
因为这一类相对复杂的文本去重算法容易去除有用的数据,一般我们会用简单的文本去重思路,只对完全重复的语料下手。
2.2. 机械压缩去词
1. 机械压缩去词的思想
比如:“哈哈哈哈哈哈哈哈哈哈哈”缩成“哈”。
机械压缩去词法不能像分词那样去识别词语。
2. 机械压缩去词处理的语料结构
机械压缩去词处理的语料中重复的部分,从一般的评论偏好角度讲,连续重复只会在开头或者结尾。
比如:”为什么为什么为什么安装费这么贵, 毫无道理! ”以及“真的很好好好好好好好好”。
3. 机械压缩去词处理过程的重复的判断以及压缩规则的阐述
重复的判断可通过建立两个存放国际字符的列表来完成, 先放第一个列表, 再放第二个列表, 一个个读取国际字符, 并按照不同情况, 将其放入带第一或第二个列表或触发压缩判断, 若得出重复(及列表1与列表2有意义的部分完全一对一相同)则压缩去除,这样当然就要有相关的放置判断及压缩规则。
规则1:如果读入的字符与第一个列表的第一个字符相同,而第二个列表没任何放入的国际字符,则将第二个字符放入第二个列表中。
解释:因为一般情况下同一个字再次出现时大多数都是意味着上一个词或是一个语段的结束以及下一个词或下一个语段的开始,比如:

规则2:如果读入的字符与第一个列表的第一个字符相同,而第二个列表也有国际字符,则触发压缩判断,若得出重复,则进行压缩去除,清空第二个列表。
解释:判断连续重复最直接的方法,比如:

规则3:如果读入的字符与第一个列表的第一个字符相同,而第二个列表也有国际字符,则触发压缩判断,若得出不重复,则清空两个列表,把读入的这个字符放入第一个列表第一个位置。
解释:即判断得出两个词是不相同的,都应保留,举例如下。
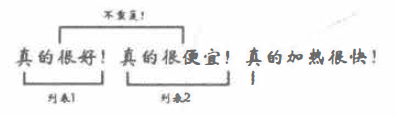
规则4: 如果读入的字符与笫一个列表的第一个字符不相同, 触发压缩判断, 如果得出 重复且列表所含国际字符数目大千等于2, 则进行压缩去除, 清空两个列表, 把读人的这个 放入第一个列表第一个位置。
解释:用以去除下图情况的重复, 并避免如 “滔滔不绝” 这种情况的 "滔” 被删除, 并可顺带压缩去除另一类连续重复, 见下图示例。

规则5: 如果读入的字符与第一个列表的第一个字符不相同, 触发压缩判断, 若得出不 重复且第二个列表没有放入国际字符, 则继续在第一个列表放入国际字符。
解释:没出现重复字就不会有连续重复语料, 第二个列表未启用则继续填入第一个列表, 直至出现重复情况为止。
规则6: 如果读入的字符与第一个列表的第一个字符不相同 触发压缩判断, 若得出不 重复且第二个列表已放入国际字符, 则继续在第二个列表放入国际字符。
解释:类似规则5。
规则7: 读完所有国际字符后, 触发压缩判断, 对第一个列表以及第二个列表有意义部分进行比较, 若得出重复, 则进行压缩去除。
解释:按照上述规则, 在读完所有国际字符后不会再触发压缩判断条件, 故为了避免下图实例连续重复情况, 补充这一规则。

4. 机械压缩去词处理操作流程
根据上述规则,便可以完成对开头连续重复的数理。类似的规则,也可以对处理过的文本再进行一次结尾连续重复的机械压缩去词,算法思想是相近的,只是从尾部开始读词罢了,从结尾开始的处理结束后就得到了已压缩去词完成的精简语料。
输出被压缩的语句和原句的对比,下图截取了一部分前向机械压缩的对比例子,如图:

2.3. 短句删除
1. 短句删除的原因及思想
完成机械压缩去词后,进行最后的预处理:短句删除。
虽然精简的辞藻是一种好习惯,但字数越少表达的意思越少。所以过少字数的评论是没有意义的,比如3个字的,“很不错”,“质量差”等就需要删除。
比如:
(1). 原本就过短的评论,如:“很不错”。
(2). 经机械压缩去词后过短的评论,如:“好好好好好好好好好好好好”。
2. 评论的字数下限的确定
短句删除最重要就是评论的字数下限的确定,一般4~8个国际字符都是较为合理的下限。
3. 文本评论分词
此处用结巴分词。分词结果的准确性对文本挖掘算法很重要,分词不佳,后续算法优秀也无法实现理想的效果。
4. 构建模型
1. 情感倾向性模型
(1). 训练生成词向量,为了将文本情感分析(情感分类)转化为机器学习问题,首先需要将符号数学化。
在NLP中,最常见的词表示方法就是One-hot Representation:将一个词映射成一个很长的单位向量,向量的长度就是词表的大小,如“学习”表示成[0 0 0 1 0 0 0 0 0 0 0 0......],“复习”表示成[0 0 0 0 0 0 0 1 0 0 0 0 0......];这样就完成了词语的数学化表示。
但是,这样就存在“词汇鸿沟”问题:即使两个词之间存在明显的联系但是在向量表示法中体现不出来,无法反映语义关联。
然而,Distributed Representation却能反映出词语与词语之间的距离远近关系,用Distributed Representation表示的向量专门称为词向量 如 “学习 ” 可能被表示成 (0.1,0.l,0.1,0.15,0.2······], "复习 ” 可能被表示成[O.J l,0.12,0. I ,O. l 5,0.22· · · · · ·], 这样, 两个词义相近的词语被表示成词向最后, 它们的距离也是较近的, 词义关联不大的两个词的距离会较远。
word2vec 采用神经网络语言模型 NNLM 和 N-gram 语言模烈 , 每个词都可以表示成一个实数向量。模型如下:
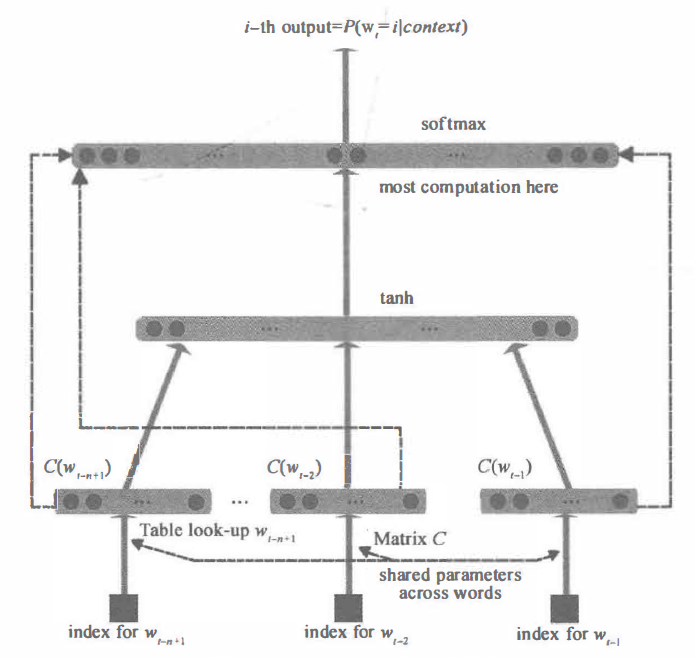
图 15-8 最下方的 Wt-n+1......Wt-2 ,Wt-1就是前 n-1 个词。 现在需要根据这已知的 n-1 个词预测下一个词Wt-0.C(W)表示词W所对应的词向量,存在矩阵C(一个|V|*m的矩阵)中。其中|V|表示词表的大小(语料中的总词数),m表示词向量的维度。W到C(W)的转换就是从矩阵中取出一行。
网络的第一层(输入层)是将C(Wt-n+1),......C(Wt-2),C(Wt-1)这是n-1个向量首尾相接拼起来,形成一个(n-1)m维的向量,记为x。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用d+Hx计算得到。d是一个偏置项。在此之后,使用tanh()作为激活函数。
网络的第三层(输出层)一共有|V|个节点,每个节点yi表示下一个词为i的为归一化log概率。最后使用softmax()激活函数将输出值y归一化成概率。最终,y的的计算公式为:
y = b + Wx + Utanh(d + Hx)
其中,U是隐藏层到输出层的参数,整个模型的多数计算集中在U和隐藏层的矩阵乘法中。矩阵W(一个|V|*(n-1)m的矩阵),这个矩阵包含了从输入层到输出层的直连边。
未完待续!!!