1 SQL中具体操作的优化
1-1 优化1:大批量插入数据
三个策略:
- 因为InnoDB类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率
- 关闭唯一性校验(不对有唯一性约束的列在插入中进行校验)
SET UNIQUE_CHECKS=0 --大批量导入数据前关闭唯一性校验
SET UNIQUE_CHECKS=1 --大批量导入数据前开启唯一性校验
- 手动提交事务
SET AUTOCOMMIT=0 --大批量导入数据前关闭自动提交
SET AUTOCOMMIT=1 --大批量导入数据后开启自动提交
1-2 优化2:优化insert语句
三个优化策略:
- 对一张表插入很多行数据时,应该尽量使用多个值表的insert语句
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
- 在事务中进行数据插入
start transaction;
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
commit;
- 数据有序插入(保持id递增)
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
insert into tb_test values(4,'Tim');
insert into tb_test values(5,'Rose');
1.3 优化3:优化order by语句(排序语句)
准备表格
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(3) NOT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`)
values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
--创建age与salary的复合索引
create index idx_emp_age_salary on emp(age,salary);
基本概念:MySQL的排序策略
MySQL优先使用index实现order by语句结果的返回,只有当索引无法使用时,才会进行filesort操作。
问题:什么时候不用索引直接进行filesort操作?
However, the query uses SELECT *, which may select more columns than key_part1 and key_part2. In that case, scanning an entire index and looking up table rows to find columns not in the index may be more expensive than scanning the table and sorting the results. If so, the optimizer probably does not use the index. If SELECT * selects only the index columns, the index is used and sorting avoided.(当查询字段多于索引字段的时候,优化器会评估扫描全表直接排序是否代价更低。如果查询字段包含索引那么直接使用索引返回查询结果)
实例1:使用filesort进行排序
explain select * from emp order by age,salary;

实例2:直接使用索引进行排序
--下面本质上还是利用了覆盖索引,直接从索引获取数据
explain select id,age,salary from emp order by age,salary;
explain select id,age from emp order by age;
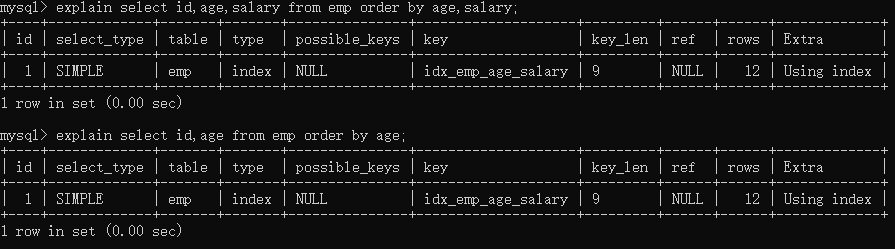
实例3:多字段排序的二个原则(order by后面有多个字段)
原则1:多个字段要么都是升序,要么都是降序。
原则2:order by的字段顺序要与复合索引建立的顺序保持一致。
--2个字段顺序一致,直接从索引返回结果
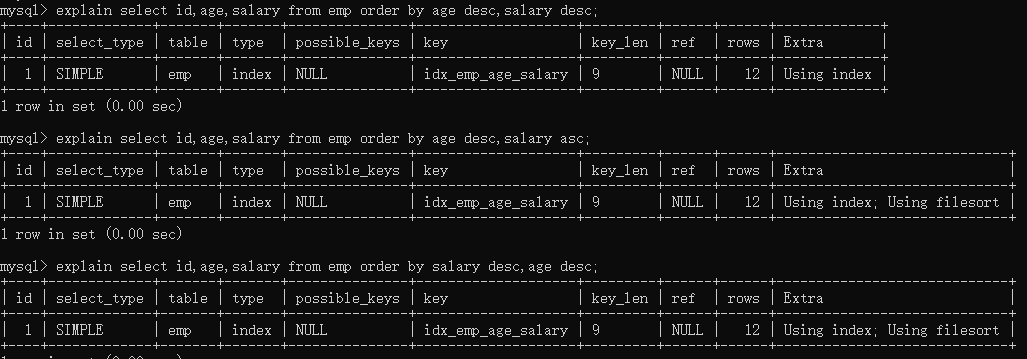
explain select id,age,salary from emp order by age desc,salary desc;
--2个字段一个升序一个降序,需要filesort
explain select id,age,salary from emp order by age desc,salary asc;
实例4:无法避免filesort时,如何进行优化?
优化目标:使用更加高效的一次排序算法
- **两次扫描算法 **(少量信息在内存排序,然后根据排好的顺序取数据,主要开销在于随机IO操作)
- step1:首先根据条件取出排序字段和行指针信息
- step2:然后在排序区sort buffer 中排序,如果sort buffer不够,则在临时表 temporary table 中存储排序结果。
- step3: 完成排序之后,再根据 行指针回表读取记录,该操作可能会导致大量随机I/O操作s
- 一次扫描算法:一次性取出满足条件的所有字段,然后在排序区 sort buffer 中排序后直接输出结果集。排序时内存开销较大,但是排序效率比两次扫描算法要高 。(去除需要的所有数据,直接在内存排序,对内存占用大)
MySQL如何确定使用一次扫描算法还是二次扫描算法?
方法:通过比较系统变量max_length_for_sort_data 与Query语句取出的字段总大小
- max_length_for_sort_data比较大,则使用一次扫描算法,否则二次。
优化策略:可以适当提高 sort_buffer_size 和 max_length_for_sort_data 系统变量 ,让系统使用一次扫描算法提高排序效率。
1.4 优化4: groupby语句优化(建立索引优化)
groupby语句与orderby语句的联系(该语句也可以通过索引优化):
- 由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。
实例1:对只有主键索引的表执行下列语句。

总结: 如果没有排序的要求可通过order by null避免排序提高效率。

总结:对查询的字段建立索引可以提高查询的效率。
1.5 优化5: mysql使用多表查询代替子查询
使用子查询

使用多表查询

总结:使用多表查询能够比较有效的提高查询效率
- 子查询: all,eq_ref,index
- 多表查询:all,ref
1.6 优化6:优化or条件
策略:包含OR的子句要利用索引就必须保证每个条件列都能够利用索引,任意字段没有能够索引,那么所有索引都会失效。
- 注意如果字段中属于复合索引,要满足最左前缀法则。
查看当前的表中具有的索引(一个主键索引和一个复合索引):

--情况1: 使用主键索引以及复合索引的第一个字段
explain select * from emp where id = 1 or age = 30G;
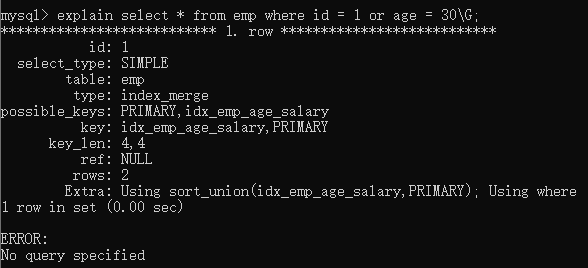
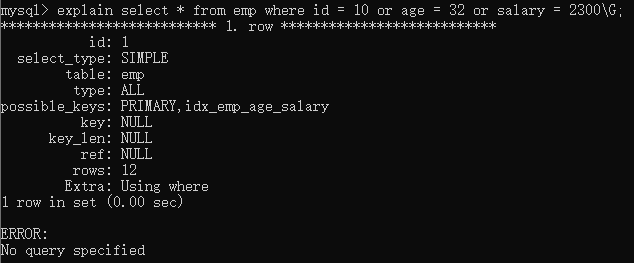
--使用主键索引,复合索引的第一个字段,salary由于无法满足最左匹配原则,导致该字段无法使用复合索引
--因此整个语句都无法使用索引
explain select * from emp where id = 10 or age = 32 or salary = 2300G;
使用union语法替代or语法进行优化(高版本MySQL会自动将or优化为union)
实例1:使用or的type是range,使用union之后type是const,union查找效率要优于or。
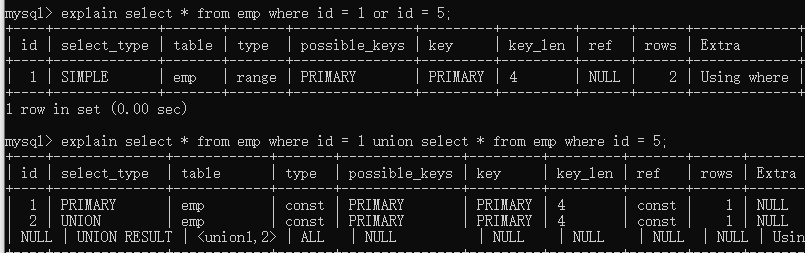
实例2:下面图中将or语法改写为union语法,type字段从index_merage变为const与ref,效率有了提升。

小知识:type 显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
1.7 优化7:优化分页查询
limt使用:就是越往后分页,LIMIT语句的偏移量就会越大,速度也会明显变慢。
实际查询时需要对200万10条记录进行排序,然后返回后10条记录。
select * from tb_item limit 2000000,10;
优化思路1:在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
- 利用了主键,加快了数据排序的速度
select * from tb_item t,(select id from tb_item order by id limit 2000000,10) a where t.id = a.id;
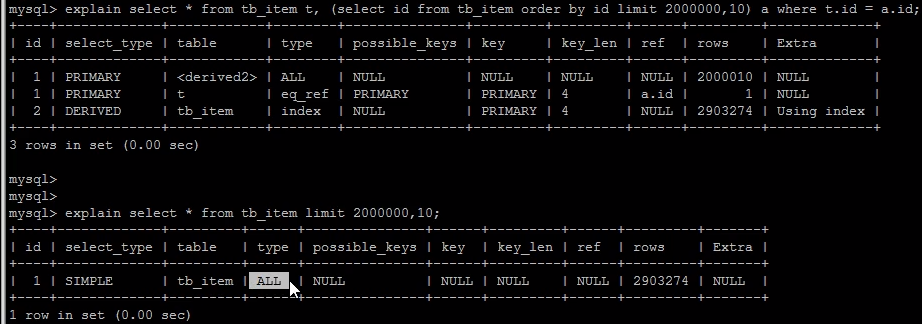
优化思路2:该方案适用于主键自增的表,可以把limit 查询转换成某个位置的查询 。
注意点:主键id内部不能存在断层,必须是连续的,否则id=1000000后的数据优于断层不是第1000000条数据。
explain select * from tb_item where id > 1000000 limit 10;
--利用主键索引快速定位,基本不耗费时间
1-8 优化8:利用SQL提示手动优化索引的使用
select * table use index(索引名) where name = "xxx"; --语句在查询是会考虑使用用户推荐的索引
| 选项 | 说明 | 备注 |
|---|---|---|
| USE INDEX | 添加 use index 来提供希望MySQL去参考的索引列表,就可以让MySQL不再考虑其他可用的索引。 | 不是强制 |
| IGNORE INDEX | 单纯的想让MySQL忽略一个或者多个索引 | |
| FORCE INDEX | 为强制MySQL使用一个特定的索引,可在查询中使用 force index 作为hint 。 |
参考资料
01 mysql优化之(use temporary、use filesort)
04 数据库课程
05 MySQL手册中对于排序的描述(推荐)
20210310