主从复制是为了解决多台服务器之间的数据同步问题
0 主从复制的背景知识
0-0 服务器的要求
互联网应用的性能要求:高并发,高性能,高可用
- 可用性的计算指标 = (全年总的时间-不可用的时间)/全年总的时间
互联网应用对可用性目标是5个9,即99.999%,即服务器宕机时长低于315s,约5.25分钟。
0-1 单台服务器
- 不能满足高并发、高性能,高可用的需求
单机redis存在的风险与问题,为什么需要多台redis服务器?
1)机器故障
2)硬件瓶颈(内存不足)
为了避免单点Redis服务器故障,准备多台服务器,互相连通。 将数据复制多个副本保存在不同的服
务器上, 连接在一起, 并保证数据是同步的。 即使有其中一台服务器宕机,其他服务器依然可以继续
提供服务,实现Redis的高可用, 同时实现数据冗余备份
0-2 多台服务器的方案
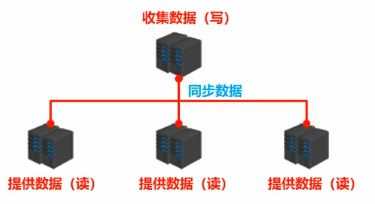
基本组成:
1)提供数据方:master(主服务器)
主服务器,主节点,主库
主客户端
- 接受数据方:slave(从服务器)
从服务器,从节点,从库
从客户端
核心问题:数据同步问题
具体的讲就是master的数据复制到slave中这个工作的处理方式。
0-3 主从复制(复制机制)的定义
定义:在redis中,用户通过执行SLAVEOF命令或者设置slaveof选项,让一个服务器去复制(replicate)另一个服务器。
- 被复制的服务器称为master(提供数据的写入),进行复制的服务器成为slave(提供数据的读取)。
0-3-1 master与slave服务器的特点:
- master:主要执行写操作(增删改),出现变化的数据会自动同步到slave中。
- slave:通常只支持读操作,写操作不允许。
0-3-2 高可用集群的简单介绍
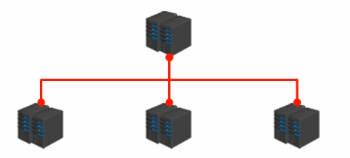
上图是典型的master-slave复制结构
问题1:当某个slave出现问题怎么办?
可用性保证:出现问题的slave服务由其他slave分担。
问题2:当master出现问题怎么办?
可用性保证:临时从一个slave中推选一个master,承担master的职责。
问题3:单台master服务压力太多,如何分担?
策略1:采用多级的结构,在某个slave中增加一级。
策略2:采用多个master构建master集群。
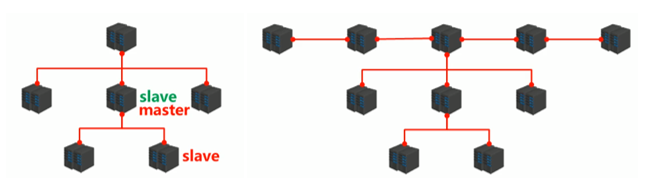
上图中左图采用2层的master-slave复制结构,右图则是采用增加master的数量,采用多个master分担服务避免单个master压力过高。
1 Redis中主从复制基础概念
1-1 主从复制的作用
主从复制主要有以下的作用:
要点:提高读写负载能力,负载均衡从而提高吞吐量与并发量,故障恢复功能
1)提高服务器的服务器的读写负载能力,通过读写分离实现
2)方便进行负载均衡,提高并发量与吞吐量,通过主从结构和读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
3)提供故障恢复(fault tolerance):当master出现问题时,由slave提供服务,实现快速的故障恢复
-
数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
-
实现高可用应用的基础:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
1-2 主从复制的工作流程(三个阶段)
1-2-1 流程概述(重要)

主从复制过程大体可以分为三个阶段:
1)建立连接阶段。 2)数据同步阶段(全量/增量复制) 3)命令传播阶段
| 阶段 | 主从数据同步度 | 发生时机 |
|---|---|---|
| 连接建立阶段 | ||
| 数据同步阶段(全量复制) | 大量数据不一致 | 首次同步或者主从服务器长时间断开 |
| 数据同步阶段(增量复制) | 最近小批量数据不一致 | 首次增量复制后或者主从服务器短时间断开 |
| 命令传播阶段 | 实时数据的同步 | 数据同步阶段后,网络状态稳定 |
1-2-2 阶段一:建立连接阶段
相关命令:
- SLAVEOF 命令用于在 Redis 运行时动态地修改复制(replication)功能的行为。
1)通过执行 SLAVEOF host port 命令,可以将当前服务器转变为指定服务器的从属服务器(slave server)。
2)如果当前服务器已经是某个主服务器(master server)的从属服务器,那么执行 SLAVEOF host port 将使当前服务器停止对旧主服务器的同步,丢弃旧数据集,转而开始对新主服务器进行同步。
3)对一个从属服务器执行命令 SLAVEOF NO ONE 将使得这个从属服务器关闭复制功能,并从从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃。利用『 SLAVEOF NO ONE 不会丢弃同步所得数据集』这个特性,可以在主服务器失败的时候,将从属服务器用作新的主服务器,从而实现无间断运行。
目标:建立slave到master的连接,使master能够识别slave, 并保存slave端口号
具体工作流程:
step1:通过从客户端向server发送slaveof ip port指令将该server设置为slave server并执行同步操作,服务器保存ip与port是master server的。
step2: slave server根据保存的信息建立与master的socket的连接,并设置定时任务执行周期性的ping命令(确保连接的存活)
step3:一些场景下可能还需要进行身份验证
step4:master保留slaver发送的端口号,并用于后续的监听。

总结:
1)slave要保存有master的ip与端口并建立socket连接,同时将自己的端口信息发送给master
- master要完成与slave的连接建立,并获取slaver信息持续对slave进行监听。
连接建立的实例操作实例:
主从结构配置:单台机器中端口号为6378的作为master server,端口号为6379的slave server。
master server的日志
(base) god@god-MS-7C83:~/redis-4.0.0/conf$ redis-server redis-6378.conf
30412:C 11 May 09:43:49.667 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
30412:C 11 May 09:43:49.667 # Redis version=4.0.0, bits=64, commit=00000000, modified=0, pid=30412, just started
30412:C 11 May 09:43:49.667 # Configuration loaded
30412:M 11 May 09:43:49.669 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.0 (00000000/0) 64 bit
.-`` .-```. ```/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6378
| `-._ `._ / _.-' | PID: 30412
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
30412:M 11 May 09:43:49.670 # Server initialized
30412:M 11 May 09:43:49.670 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
30412:M 11 May 09:43:49.670 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
30412:M 11 May 09:43:49.670 * DB loaded from append only file: 0.000 seconds
30412:M 11 May 09:43:49.670 * Ready to accept connections
30412:M 11 May 09:48:35.622 * Slave 127.0.0.1:6379 asks for synchronization
30412:M 11 May 09:48:35.622 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for 'ee13fb85ad9e0fd840d53897424fa5e4270f8e2d', my replication IDs are '70b06e6b4a97d7ba81da6d938a5c4607ea92aef0' and '0000000000000000000000000000000000000000')
30412:M 11 May 09:48:35.622 * Starting BGSAVE for SYNC with target: disk
30412:M 11 May 09:48:35.622 * Background saving started by pid 30452
30452:C 11 May 09:48:35.624 * DB saved on disk
30452:C 11 May 09:48:35.625 * RDB: 0 MB of memory used by copy-on-write
30412:M 11 May 09:48:35.721 * Background saving terminated with success
30412:M 11 May 09:48:35.722 * Synchronization with slave 127.0.0.1:6379 succeeded
30412:signal-handler (1620697869) Received SIGINT scheduling shutdown...
30412:M 11 May 09:51:09.278 # User requested shutdown...
30412:M 11 May 09:51:09.278 * Calling fsync() on the AOF file.
30412:M 11 May 09:51:09.279 # Redis is now ready to exit, bye bye...
slaver server的日志
(base) god@god-MS-7C83:~/redis-4.0.0/conf$ redis-server redis-6379.conf
30429:C 11 May 09:44:38.078 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
30429:C 11 May 09:44:38.078 # Redis version=4.0.0, bits=64, commit=00000000, modified=0, pid=30429, just started
30429:C 11 May 09:44:38.078 # Configuration loaded
30429:M 11 May 09:44:38.080 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.0 (00000000/0) 64 bit
.-`` .-```. ```/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 30429
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
30429:M 11 May 09:44:38.080 # Server initialized
30429:M 11 May 09:44:38.080 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
30429:M 11 May 09:44:38.080 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
30429:M 11 May 09:44:38.080 * DB loaded from append only file: 0.000 seconds
30429:M 11 May 09:44:38.080 * Ready to accept connections
30429:S 11 May 09:48:35.614 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
30429:S 11 May 09:48:35.614 * SLAVE OF 127.0.0.1:6378 enabled (user request from 'id=2 addr=127.0.0.1:44450 fd=9 name= age=35 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=slaveof')
30429:S 11 May 09:48:35.620 * Connecting to MASTER 127.0.0.1:6378
30429:S 11 May 09:48:35.621 * MASTER <-> SLAVE sync started
30429:S 11 May 09:48:35.621 * Non blocking connect for SYNC fired the event.
30429:S 11 May 09:48:35.621 * Master replied to PING, replication can continue...
30429:S 11 May 09:48:35.621 * Trying a partial resynchronization (request ee13fb85ad9e0fd840d53897424fa5e4270f8e2d:1).
30429:S 11 May 09:48:35.622 * Full resync from master: 92e3bfb1b29ae96d1754d25c5e4be96a4d19a492:0
30429:S 11 May 09:48:35.622 * Discarding previously cached master state.
30429:S 11 May 09:48:35.722 * MASTER <-> SLAVE sync: receiving 224 bytes from master
30429:S 11 May 09:48:35.722 * MASTER <-> SLAVE sync: Flushing old data
30429:S 11 May 09:48:35.722 * MASTER <-> SLAVE sync: Loading DB in memory
30429:S 11 May 09:48:35.723 * MASTER <-> SLAVE sync: Finished with success
30429:S 11 May 09:48:35.723 * Background append only file rewriting started by pid 30453
30429:S 11 May 09:48:35.747 * AOF rewrite child asks to stop sending diffs.
30453:C 11 May 09:48:35.747 * Parent agreed to stop sending diffs. Finalizing AOF...
30453:C 11 May 09:48:35.747 * Concatenating 0.00 MB of AOF diff received from parent.
30453:C 11 May 09:48:35.747 * SYNC append only file rewrite performed
30453:C 11 May 09:48:35.748 * AOF rewrite: 0 MB of memory used by copy-on-write
30429:S 11 May 09:48:35.822 * Background AOF rewrite terminated with success
30429:S 11 May 09:48:35.822 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
30429:S 11 May 09:48:35.822 * Background AOF rewrite finished successfully
30429:S 11 May 09:51:09.279 # Connection with master lost.
30429:S 11 May 09:51:09.279 * Caching the disconnected master state.
30429:S 11 May 09:51:09.979 * Connecting to MASTER 127.0.0.1:6378
30429:S 11 May 09:51:09.979 * MASTER <-> SLAVE sync started
30429:S 11 May 09:51:09.979 # Error condition on socket for SYNC: Connection refused
30429:S 11 May 09:51:10.982 * Connecting to MASTER 127.0.0.1:6378
30429:S 11 May 09:51:10.982 * MASTER <-> SLAVE sync started
30429:S 11 May 09:51:10.982 # Error condition on socket for SYNC: Connection refused
总结:从日志尾部可以看到,如果master server突然宕机,slave server会报错:
30429:S 11 May 09:51:10.982 # Error condition on socket for SYNC: Connection refused
master server客户端操作命令
(base) god@god-MS-7C83:~$ redis-cli -p 6378
127.0.0.1:6378> set name i_am_a_master_are_you_ok
OK
slaver server客户端操作命令
127.0.0.1:6379> slaveof 127.0.0.1 6378
OK
127.0.0.1:6379> set name synchronizastion
(error) READONLY You can't write against a read only slave.
127.0.0.1:6379> get name
"i_am_a_master_are_you_ok"
总结:可以看到设置数据库其他数据库的slaver后,默认无法进行写操作,并且能够直接读取到master server写入的数据。
通过配置文件实现master-slave 的连接的建立(实际工作中常用的方式)
- 在slaver的配置文件中添加slaveof命令使得启动时就与master建立连接
port 6379
slaveof 127.0.0.1 6378
daemonize no
# logfile "6378.log"
dir /home/god/redis-4.0.0/log_info
appendonly yes
appendfsync everysec
使用info命令查看replication的信息
master服务器信息
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6379,state=online,offset=70,lag=1
master_replid:d13eefb9a8df2e131c39b291619090310ecf4af5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
slave服务器信息
# Replication
role:slave
master_host:127.0.0.1
master_port:6378
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:140
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:d13eefb9a8df2e131c39b291619090310ecf4af5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:140
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:57
repl_backlog_histlen:84
连接阶段的其他操作命令
/*客户端发送命令,slave断开连接后,不会删除已有数据,只是不再接受master发送的数据*/
slaveof no one
/*master客户端发送命令设置密码*/
requirepass <password>
/*master配置文件设置密码*/
config set requirepass <password>
config get requirepass
/*slave客户端发送命令设置密码*/
auth <password>
/* slave配置文件设置密码*/
masterauth <password>
/*slave启动服务器设置密码*/
redis-server –a <password>
1-2-3 阶段二:数据同步阶段
psync2:partial resynchronization version2
- redis因某种原因引起复制中断后,从库重新同步时,只同步主实例的差异数据(写入指令),不进行bgsave复制整个RDB文件。
具体工作流程(结合表格)
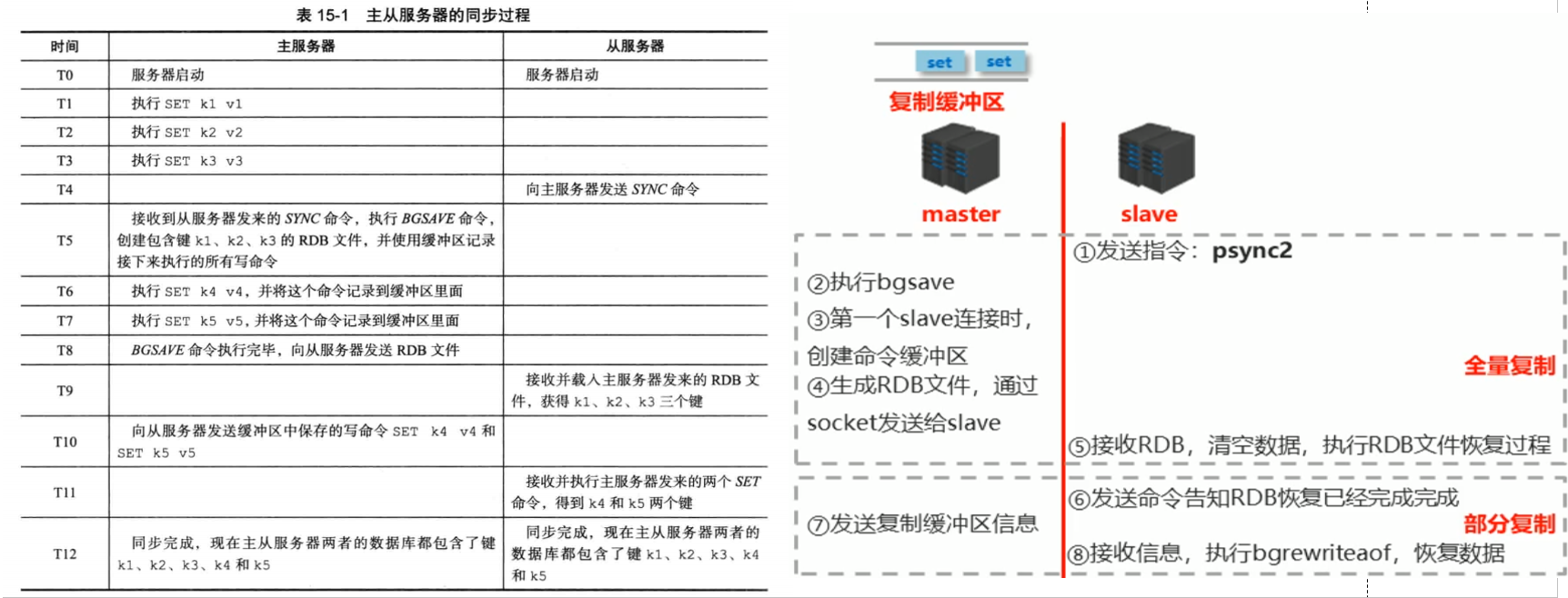
补充知识:redis的同步命令随着版本而发生变化,1.0是sync命令,2.8变为psync命令,4.0命令则是变为psync2。
step1: slave库向master库发送同步命令(sync/pysync/psync1)
step2: master库收到从slave库的同步命令后使用bgsave创建RDB文件,由于RDB的方式实时性比较差并且master库在创建RDB文件中也会有数据写入,这部分数据的写入命令(本质上是AOF文件)会被写入到复制缓冲区(部分复制发送的内容就是复制缓冲区内容),RDB文件创建完成后发送给slave库。
step3: slave库接受并首先使用RDB文件数据完成数据的全量复制,
step4: slave库恢复完成后通知master库已经使用RDB文件复制了数据,并请求master的缓冲区的内容。
step5: master发送复制缓冲区的数据给slave库,slave库接受数据后采用bgrewriteof(Background append only file rewriting started)命令进一步复制数据(完成增量复制)
redis中全量复制与部分复制的特点与区别?
- 全量复制(RDB):用于初次复制或其它无法进行部分复制的情况,采用RDB文件将master库中的所有发送到slave库中数据。
- 部分复制(AOF):用于处理在主从复制中因网络闪退等原因造成数据丢失场景,全量复制通常会配合部分复制一起使用。master库通过网络通信将其复制缓冲区的命令发送给slave库。
结合实际日志信息分析同步过程
- 从日志文件中可以看到在数据库数据同步的阶段,master会执行bgsave获取RDB文件用于全量复制,
30412:M 11 May 09:48:35.622 * Slave 127.0.0.1:6379 asks for synchronization
30412:M 11 May 09:48:35.622 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for 'ee13fb85ad9e0fd840d53897424fa5e4270f8e2d', my replication IDs are '70b06e6b4a97d7ba81da6d938a5c4607ea92aef0' and '0000000000000000000000000000000000000000')
30412:M 11 May 09:48:35.622 * Starting BGSAVE for SYNC with target: disk
30412:M 11 May 09:48:35.622 * Background saving started by pid 30452 // 创建新的进程去创造RDB文件
30452:C 11 May 09:48:35.624 * DB saved on disk
30452:C 11 May 09:48:35.625 * RDB: 0 MB of memory used by copy-on-write
30412:M 11 May 09:48:35.721 * Background saving terminated with success
数据同步阶段maser与slave的注意点(重要)
数据同步阶段的master端: 避开流量高峰,确保复制缓冲大小足够,内存占用比例合理设置
1)如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
2) 复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态
3)master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执bgsave命令和创建复制缓冲区
repl-backlog-size 1mb // 配置文件的配置选项
数据同步阶段的slave端:关闭对外服务,大规模同步调整结构以及错峰同步
1 避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
2. 数据同步阶段, master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送
命令
3. 多个slave同时对master请求数据同步, master发送的RDB文件增多, 会对带宽造成巨大冲击, 如果
master带宽不足, 因此数据同步需要根据业务需求,适量错峰
4.slave过多时, 建议调整拓扑结构,由一主多从结构变为树状结构, 中间的节点既是master,也是
slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟
较大, 数据一致性变差, 应谨慎选择。
1-2-4 阶段三:命令传播阶段(维护状态一致性)
命令传播:主服务器会将自己执行的写命令,也就是造成主从服务器不一致的写命令,发送slave执行,当slave执行这个命令后就会让状态一致。
| 命令传播阶段的断网现象 | 策略 |
|---|---|
| 网络闪断闪连 | 传播命令 |
| 短时间网络中断 | 部分复制 |
| 长时间网络中断 | 全量复制 |
1-3 部分复制的实现机制(重要)
1-3-1 部分复制的三个核心要素
服务器的运行 id( run id)
主服务器的复制积压缓冲区
主从服务器的复制偏移量
1-3-2 服务器运行id介绍
服务器运行ID:每一台服务器每次运行的身份识别码,一台服务器**多次运行可以生成多个运行ID。
- 运行id由40位字符组成,是一个随机的十六进制字符
运行ID作用:运行id被用于在服务器间进行传输,识别身份
如果两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
实现方式: 运行id在每台服务器启动时自动生成的, master在首次连接slave时,会将自己的运行ID发送给slave, slave保存此ID,通过info Server命令,可以查看节点的runid
可以通过info server查看当前库的运行ID
# Server
redis_version:4.0.0
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:d748290e16ddf3d8
redis_mode:standalone
os:Linux 5.4.0-70-generic x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:7.5.0
process_id:30623
run_id:b565cb32a78ea5b632b147ac5b8d2054b64ffdff // 运行id
tcp_port:6379
uptime_in_seconds:10367
uptime_in_days:0
hz:10
lru_clock:10096796
executable:/home/god/redis-4.0.0/conf/redis-server
config_file:/home/god/redis-4.0.0/conf/redis-6379.conf
1-3-3 复制缓冲区
概念:复制缓冲区,又名复制积压缓冲区,是一个先进先出( FIFO)的队列, 用于存储服务器执行过的命令, 每次传播命令, master都会将传播的命令记录下来, 并存储在复制缓冲区
- 复制缓冲区默认数据存储空间大小是1M,由于存储空间大小是固定的,当入队元素的数量大于队列长度时,最先入队的元素会被弹出,而新元素会被放入队列
- 每台服务器启动时,如果开启有AOF或被连接成为master节点, 即创建复制缓冲区
组成:由偏移量与字节值组成
主从服务器复制偏移量( offset)描述复制缓冲区中的指令字节位置
-master复制偏移量:记录发送给所有slave的指令字节对应的位置(多个)
-slave复制偏移量:记录slave接收master发送过来的指令字节对应的位置(一个)
=============================================================
master端:发送一次记录一次
slave端:接收一次记录一次
==============================================================
作用:同步信息,比对master与slave的差异,当slave断线后,恢复数据使用
原理:通过offset区分不同的slave当前数据传播的差异,master记录已发送的信息对应的offset,slave记录已接收的信息对应的offset

1-4 命令传播的实现机制(runid/offset)总结(重要)

前提:master/slave服务器中redis数据库运行,产生唯一的runid, master与slave已经建立网络连接。
概述:在命令传播阶段主要以命令的传播为主,当触发某些条件是还是会进行全量复制与部分复制的。
全量复制阶段(大量的数据没有实现同步)
情况1:第一次进行全量复制,此时从库的复制偏移量为-1,master也没有这个新的slave的runid记录,因此直接发送同步命令,主库收到命令后发现id不匹配,因此将该命令作为全量复制处理,进而创建好DB文件后发送FULLRESYN runid offset命令给从库,注意这里的
runid用于区分可能存在的多个从库,offset则是DB文件中已经复制的数据偏移量。
情况2:由于一些原因(网络长时间断开,复制缓冲区溢出),某个slave再次触发了全量复制。
部分复制阶段(最近的小批量数据没有实现同步)
- 注意:全量复制与部分复制在命令上的体现仅仅在于是否带有偏移量
命令传播阶段(实时性的数据同步)
本质:slave会周期性的发送部分同步命令(带有复制偏移量和slave运行id的同步命令)给master库要求同步最新写入的数据。master端会维护每个slave的runid以及offset,对于发送过来的同步命令进行匹配。
1-5 复制过程中的心跳机制
心跳机制目的:命令传播阶段候, master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
- 对于master通过心跳机制判断slave是否在线
- 对于slave用于汇报自己的存在以及自己所需的offset
master端心跳机制的配置:
指令: PING
周期:由repl-ping-slave-period决定,默认10秒
作用:判断slave是否在线
查询: INFO replication 获取slave最后一次连接时间间隔, lag项维持在0或1视为正常
slave端心跳机制的配置:
指令: REPLCONF ACK {offset}
周期: 1秒
作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
作用2:判断master是否在线
心跳机制的注意事项
当slave多数掉线,或延迟过高时, master为保障数据稳定性,将拒绝所有信息同步操作
slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步
slave数量由slave发送REPLCONF ACK命令做确认
slave延迟由slave发送REPLCONF ACK命令做确认
1-6 主从复制整体流程图解

- 注意master会不断的发送ping命令确认slave的存在
- 整个工作流程可以理解为一个状态机,根据主从数据不一致的规模来采取适当的策略(全量复制/增量复制/命令传播)进行状态转移
- 具体的实现通过master维护每个slave的offset与runid实现。
2 主从复制工作流程中常见的问题以及解决策略
问题1:频繁的全量复制该怎么处理?
出现该问题的场景1:伴随着系统的运行, master的数据量会越来越大,一旦master重启, runid将发生变化,会导致全部slave的
全量复制操作
解决策略:重启前保存重启时刻的所有slave的id以及自身的runid, 这样重启后加载之前的配置,避免全量复制。
内部优化调整方案:
1. master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave
2. 在master关闭时执行命令 shutdown save,进行RDB持久化,将runid与offset保存到RDB文件中
repl-id repl-offset
通过redis-check-rdb命令可以查看该信息
3. master重启后加载RDB文件, 恢复数据
重启后,将RDB文件中保存的repl-id与repl-offset加载到内存中
master_repl_id = repl master_repl_offset = repl-offset
通过info命令可以查看该信息
作用:
本机保存上次runid,重启后恢复该值,使所有slave认为还是之前的master
出现该问题的场景2:网络环境不佳,出现频繁网络中断,slave不得不进行全量复制,这样也会造成slave无法正常提供服务
问题原因:复制缓冲区过小,断网后slave的offset越界,触发全量复制
解决方案:
修改复制缓冲区大小
建议设置如下:
1. 测算从master到slave的重连平均时长second
2. 获取master平均每秒产生写命令数据总量write_size_per_second
3. 最优复制缓冲区空间 = 2 * second * write_size_per_second
问题2:主从服务器之间频繁的网络中断该怎么处理?
问题发生的现象1:slave在提供读取服务时,出现这样一种现象:接到了慢查询(耗时比较大的查询)时( keys * , hgetall等),会大量占用CPU性能,但是master每1秒调用复制定时函数replicationCron(),比对slave发现长时间没有进行响应。从而对slave的生存状态不停的询问(slave由于过于繁忙无法及时应答master的询问)
不良结果:master各种资源(输出缓冲区、带宽、连接等) 被严重占用 (master需要不停询问未应答的slave
占用并浪费了资源)
解决策略:及时的放弃长时间不应答的slave。
通过设置合理的超时时间,确认是否释放slave
repl-timeout // 该参数定义了超时时间的阈值(默认60秒),超过该值,释放slave
问题发生的现象2: master对slave的关心与耐心不够,对slave的状态进行误判。
master发送ping指令频度较低
master设定超时时间较短
ping指令在网络中存在丢包
解决方案:
提高ping指令发送的频度
repl-ping-slave-period
- 超时时间repl-time的时间至少是ping指令频度的5到10倍,否则slave很容易判定超时
问题3:多个slave获取的数据不一致问题?
原因: 网络信息不同步,数据发送有延迟
解决策略(通常需要综合考虑多方面因素,不仅仅是redis本身的问题):
1)优化主从间的网络环境,通常放置在同一个机房部署,如使用阿里云等云服务器时要注意此现象
2)监控主从节点延迟(通过offset)判断,如果slave延迟过大,暂时屏蔽程序对该slave的数据访问开启后仅响应info、 slaveof等少数命令(慎用,除非对数据一致性要求很高)
配置选项:
slave-serve-stale-data yes|no // 停止slave提供服务,尝试其他解决策略
3 主从复制的总结(结合上面内容)
主从复制的目的就是希望保证slave服务器与master服务器能够保持数据的一致性。我们希望在master中写入的数据能够实时在其他slave服务器被获取的。
情景:假定一台主服务器正在运行,要新增一台slave server提供master的数据的读取服务。
根据这个场景,在redis中完整的主从复制可以大致分为三个阶段(连接建立,数据同步,命令传播):
1)连接建立阶段,主要采用slaveof设置新增的机器的master的ip与端口
2)建立连接后,一开始数据不一致很大,所以采用全量复制的方式,从库发送同步命令,主库采用bgsave的方式产生rdb文件并发送给从服务器去复制数据,从服务器利用rdb文件恢复数据后。显然rdb文件中数据并非master所有最新的数据。
3)对于rdb文件中没有的数据,主库会采用增量复制,主库复制执行的命令并存储在复制缓冲区,在从库完成rdb的恢复后,主库根据从库提供的offset将剩余的最新数据发送过去。
4)在完成全量复制以及部分复制后,主从数据库基本保持一致,进入命令传播阶段,由于主库他的数据一直在变动,后续的状态不一致时,主库直接将引发不一致的写入命令发送给从库执行,从而保持数据一致性。
5)本质上全量复制/增量复制/命令传播是针对主从数据不一致性提供的三种不同机制。数据的不一致程度决定采用具体的复制机制,如果网络长时间中断则则需再次进行增量/全量复制。
6)另外就是主从复制的实现核心是通过masetr维护各个slave运行id以及数据复制的偏移量实现的
关于主从复制的原理可以看《redis的设计与实现》更加详细