1 redis内置的三种高级数据结构(了解)
| 数据结构名称 | 应用 |
|---|---|
| Bitmaps | 节约空间的2种状态统计(统计每天/月/年的用户签到数量) |
| HyperLogLog | 大规模数据有误差的去重统计(统计UV) |
| GEO | 存储地理位置信息,并对存储的信息进行操作 |
注意:上述高级数据结果都有着非常专门的应用场景,没有5种基本的数据类型应用那么广泛。
1-1 Bitmaps
1-1-1 概述
定义:BitMap,即位图,其实也就是 byte 数组,用二进制表示,只有 0 和 1 两个数字。
- Redis从2.2.0版本开始新增了
setbit,getbit,bitcount等几个bitmap相关命令。虽然是新命令,但是并没有新增新的数据类型,因为setbit等命令只不过是在set上的扩展。
应用场景:事务的状态信息只有2种
- 统计每天/月/年的用户签到数量
- 统计每天的用户活跃数量
1-1-2 基本操作命令
getbit key offset // 获取指定key对应偏移量上的bit值
setbit key offset value // 设置指定key对应偏移量上的bit值,value只能是1或0
bitop op destKey key1 [key2...]
// op: and or not xor
// 对指定key按位进行交、并、非、异或操作,并将结果保存到destKey中
bitcount key [start end]
1-1-3 bitmaps的应用场景分析
场景介绍:
电影网站
统计每天某一部电影是否被点播
统计每天有多少部电影被点播
统计每周/月/年有多少部电影被点播
统计年度哪部电影没有被点播
位图解决策略
- 每天都会维护一个位图,默认都为0,当某个电影被点播,根据id获得offset并将对应offset设为1
| 统计目标 | 方法 |
|---|---|
| 统计每天某一部电影是否被点播 | 通过电影id计算该电影在位图中的offset,找到当天的位图,查看offset的状态 |
| 统计每天有多少部电影被点播 | 计算当天的位图中1的个数 |
| 统计每周/月/年有多少部电影被点播 | 将所有天的状态进行按位或操作,统计最后结果1的个数 |
| 统计年度哪部电影没有被点播 | 将所有天的状态进行按位或操作,为0的位置的电影就是没有点播的电影,根据offset再获取对应的电影id。 |
数据操作实例
127.0.0.1:6378> setbit 20880808 0 1
(integer) 0
127.0.0.1:6378> setbit 20880808 4 1
(integer) 0
127.0.0.1:6378> setbit 20880808 8 1
(integer) 0
127.0.0.1:6378> setbit 20880809 0 1
(integer) 0
127.0.0.1:6378> setbit 20880809 5 1
(integer) 0
127.0.0.1:6378> setbit 20880809 8 1
(integer) 0
127.0.0.1:6378> bitcount 20880808
(integer) 3
127.0.0.1:6378> bitop or 08-09 20880808 20880809
(integer) 2
127.0.0.1:6378> bitcount 08-09
(integer) 4
1-2 HyperLogLog(大规模数据有误差的去重统计)
场景:统计独立UV (Unique Visitor)
问题分析:由于是独特的访问,所以需要考虑去重问题。
解决策略:
| 方案 | 备注 |
|---|---|
| 原始方案: set | 存储每个用户的id(字符串) |
| 改进方案: Bitmaps | 存储每个用户状态( bit) |
| 全新的方案:Hyperloglog |
实际上bitmaps已经很能够解决空间了,但是我们需要去重统计,在这个问题上hyperloglog可以以更小的空间进行去重统计。
1-2-1 hyperloglog的操作命令
-
添加数据
pfadd key element1, element2...Copy -
统计数据
pfcount key1 key2....Copy -
合并数据
pfmerge destkey sourcekey [sourcekey...]
1-2-2 hyperloglog算法特点
基数是数据集去重后元素个数,HyperLogLog 是用来做基数统计的,运用了LogLog的算法
- 用于进行基数统计,不是集合,不保存数据,只记录数量而不是具体数据
- 核心是基数估算算法,最终数值存在一定误差
- 误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值
- 耗空间极小,每个hyperloglog key占用了12K的内存用于标记基数
- pfadd命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
- Pfmerge命令合并后占用的存储空间为12K,无论合并之前数据量多少
1-3 GEO数据结构
1-3-1 基本操作
-
添加坐标点
geoadd key longitude latitude member [longitude latitude member ...] georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]Copy -
获取坐标点
geopos key member [member ...] georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]Copy -
计算坐标点距离
geodist key member1 member2 [unit] geohash key member [member ...]
实际操作
127.0.0.1:6378> flushdb
OK
127.0.0.1:6378> geoadd geos 1 1 a // 添加城市a位置
(integer) 1
127.0.0.1:6378> geoadd geos 2 2 b // 添加城市b位置
(integer) 1
127.0.0.1:6378> geopos geos a // 查看城市a位置
1) 1) "0.99999994039535522"
2) "0.99999945914297683"
127.0.0.1:6378> geodist geos a b
"157270.0561"
127.0.0.1:6378> geodist geos a b m // 计算a与b距离,单位m
"157270.0561"
127.0.0.1:6378> geodist geos a b km // 计算a与b距离,单位km
"157.2701"
下面内容来源于redis的设计与实现
2 redis底层6种基本数据结构
2-1 简单动态字符串(SDS)
2-1-1 SDS定义
- 下面是Redis4.0的SDS源代码
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
以 sdshdr64为例包含以下属性:字符串长度,字符串实际使用的空间大小,字符串类型标志位,char数组
| 变量 | 作用 |
|---|---|
| 64位无符号整型变量 | 字符串长度(不包含结尾的空字符) |
| 64位无符号整型变量 | 不包含头部与尾部字符的分配的字串长度(excluding the header and null terminator) |
| 8位无符号变量 | 表示字符串的类型,由于只有5种类型,所有使用了3bit,剩余5bit没有使用 |
| char数组 | 用于存放字符串 |
关于char数组
- 数组前5个字节保存有”Redis“这5个字符
- 最后一个字节保存有空字符'�'
2-2-2 SDS与C中字符数组区别
SDS的优势主要体现在:1)字符串长度的获取 2)缓冲区溢出的避免 3)操作时内存分配开销的减少 4)二级制安全
| 区别 | 普通C字符串 | sds | 动机 |
|---|---|---|---|
| 字符串长度的获取 | 使用strlen,O(n)时间复杂度 | 通过len属性,O(1) | 避免字符串长度的获取变为Redis性能瓶颈 |
| 缓冲区溢出 | 字符串操作存在溢出风险 | 字符串操作时会先检查空间,避免溢出 | |
| 减少字符串修改内存分配的开销 | 字符串长度+1=底层char数组长度 | 允许有未使用的空间 | 通过空间预分配与懒惰空间释放避免字符串修改时频繁的内存分配开销 |
| 二进制安全 | 通过'�'记录长度不安全,只能存储文本 | 通过len而不是'�'记录长度 | 存储任意格式的二机制数据 |
- 二进制安全指的是SDS是按照字节写入数据,不会修改数据,而原始数组使用'�'作为结束标志符,这使得无法存储图像等其他类型的数据,由于其他类型数据'�’也会作为信息写入。
为什么SDS有了len属性还是用'�'作为字符串的结束字符?
主要是为了兼容C对于字符串操作的函数,比如string.h的函数
2-2-3 SDS总结
特点
1)常数复杂度获取字符串长度
2)杜绝缓冲区溢出
3)减少修改字符串所需的内存分配次数
4)二进制安全,可以存储除文本以外的数据。
此外为了兼容C的库函数,仍然在字符串结尾处添加�'
SDS在redis中的应用
1)保存redis中的字符串。
2)作为缓冲区使用,包括AOF模块中的缓冲区,客户端状态中的输入缓冲区。
2-2 链表
2-2-1 链表的定义
#ifndef __ADLIST_H__
#define __ADLIST_H__
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr); // 节点值复制函数
void (*free)(void *ptr); // 节点值释放函数
int (*match)(void *ptr, void *key); // 节点值释放函数
unsigned long len; // 链表包含的节点数量
} list;
2-2-2 redis中链表总结
特点:
1)redis中的链表是双向无环链表
2)获取头尾节点以及链表长度的时间复杂度为O(1)
3)链表具有多态性,采用void* 保存数据,可以保存不同类型的值。
应用:
链表被用于实现列表键,发布与订阅,慢查询,监视器等。
2-3 字典(hash表)
2-3-1 字典定义
hash表节点定义
typedef struct dictEntry {
void *key; // 节点中存储的键
union { // 节点中存储的值(采用union联合体适用于各种类型数据存储)
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个节点,该节点与当前节点hash值相同(拉链发解决hash冲突)
} dictEntry;
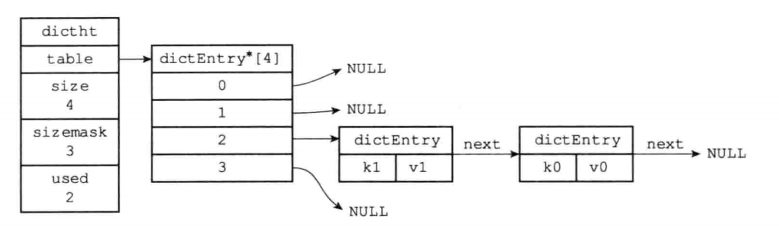
- 可以看到redis中的hash表是通过拉链法解决hash碰撞问题(如下图所示)
/*hash表的数据结构的操作方法定义,通过函数指针调用*/
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); // 为key计算hash值
void *(*keyDup)(void *privdata, const void *key); // 复制key
void *(*valDup)(void *privdata, const void *obj); // 复制val
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // key比较
void (*keyDestructor)(void *privdata, void *key); // 销毁key
void (*valDestructor)(void *privdata, void *obj); // 销毁值
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
/*字典数组定义*/
typedef struct dictht {
dictEntry **table;
unsigned long size; // hash表的大小
unsigned long sizemask; // 用于计算hash数组的索引,总是等于 hash表的大小-1
unsigned long used; // hash表中键值对的数量,注意并非时hash数组已使用的索引数量,用于计算负载因子
} dictht;
/*字典的定义,每个字典中包含2个hash table*/
typedef struct dict {
dictType *type; // 类型特定的字典函数
void *privdata; // 字典的私有数据
dictht ht[2]; // hash数组,默认情况下使用hash[0],hash[1]在hash[0]rehash的时候使用!!!!!!
long rehashidx;
/* 索引计数器变量,不为-1表示不是处于rehash状态,当处于rehash状态时,会通过这个统计已经rehash的idx*/
unsigned long iterators; /* number of iterators currently running */
} dict;
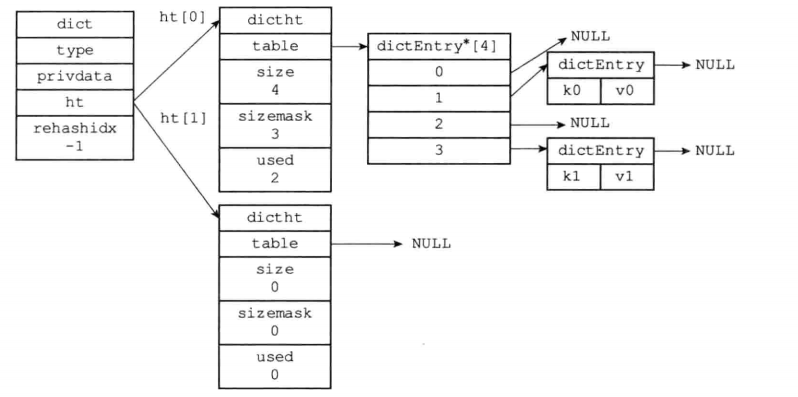
2-3-2 redis中hash表的特点
特点1:在 Redis 5.0 以及 4.0 版本,都使用了 siphash 哈希算法。siphash 可以在输入的 key 值很小的情况下,产生随机性比较好的输出,在 Redis 3.2, 3.0 以及 2.8 版本,使用 Murmurhash2 哈希算法,Murmurhash 可以在输入值是有规律时,也能给出比较好的随机分布。
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// hash函数输入key产生固定长度的hash值,然后对长度取模获取hash数组的index
redis4.0/src/dict.c
/* -------------------------- hash functions -------------------------------- */
static uint8_t dict_hash_function_seed[16];
void dictSetHashFunctionSeed(uint8_t *seed) {
memcpy(dict_hash_function_seed,seed,sizeof(dict_hash_function_seed));
}
uint8_t *dictGetHashFunctionSeed(void) {
return dict_hash_function_seed;
}
/* The default hashing function uses SipHash implementation
* in siphash.c. */
uint64_t siphash(const uint8_t *in, const size_t inlen, const uint8_t *k);
uint64_t siphash_nocase(const uint8_t *in, const size_t inlen, const uint8_t *k);
uint64_t dictGenHashFunction(const void *key, int len) {
return siphash(key,len,dict_hash_function_seed);
}
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len) {
return siphash_nocase(buf,len,dict_hash_function_seed);
}
/* ----------------------------- API implementation ------------------------- */
总结:从源码中可以看到redis4.0中采用是siphash函数计算key的hash值。
特点2:hash表的冲突采用链地址法解决,节点的插入采用头插法

特点3:redis中hash表的rehash操作
redis中rehash的步骤:
在2-3-1的定义中可以看到字典中定义了两个hash数组指针,分别
1)为字典的hash表1分配空间,hash表的空间大小取决于具体的操作:

2)将保存在hash表0的所有的键值对rehash到hash表1上。
3)当hash表0所有键值对都rehash到hash表1,释放hash表0的空间,然后将hash表0指向hash表1的空间,hash1表创建新的空白空间
2-3-3 redis中hash表的知识点
问题1:redis中hash表负载因子计算方式?
redis中负载因子计算方法 = 哈希表已保存的节点数量(包括冲突的节点)/ hash数组的大小 (所以值可以大于1)
Java中hashmap中负载因子计算方法 = 已经使用数组空间大小/hash数组大小 (所以值的范围为0~1,java默认0.75)
问题2:redis中什么时候对hash表进行扩展操作?

分情况的原因?
BGSAVE以及BGREWRITEAOF由于cow机制的原因也会进行内存的分配,在这种时刻进行扩容显然是不合适的,因此提高负载因子避免此类情况发生
问题3:redis中什么时候对hash表进行收缩操作?
当负载因子小于0.1的时候会进行收缩操作。
问题4:redis中的渐进式hash的动机以及实现?
动机:大数据量下一次性集中性的rehash操作会消耗大量计算资源,造成服务停止。
基本思想:将rehash过程中的计算开销平摊到对字典的各个操作上
实现步骤:
step1:当需要进行rehash的时候,并非一次性全部实现,而是先将字典的rehashidx属性(索引计数器变量)设为0(默认-1)表示当前字典处于rehash过程中
step2:在rehash的过程中,每次对该字典进行增删查改的操作时都会将对应索引进行rehash(渐进式体现)
step3: 当所有的键值对都被rehash,则rehashidx = -1,表示rehash过程结束
rehash过程中的查找与插入?
查找:优先在老hash表查找,找不到到新hash表
插入:直接插入到新hash表
2-3-4 redis中字典的总结
1)redis中字典底层为两个hash数组
2)hash采用链表解决冲突,rehash采用渐进式rehash,有两种情况的负载因子,进行hash表的扩容与收缩
3)应用:
a) redis数据库本身是一个 Map,其中所有的数据都是采用 key : value 的形式存储,这个map就是字典实现
b) key对应的hash表对象(书中也叫hash键)底层也会用到字典


2-4 跳跃表(skiplist)
2-4-1 跳跃表定义
跳跃表/跳表是有序链表的一种变形,它以二分查找的思想在一定程度上优化了链表查找元素效率不高的问题。采取了空间换时间的策略。
特点: 有序链表结构,多层索引节点提高效率

上图的跳表有四个层级:
| 层级 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 层级1 | 3 | 6 | 7 | 9 | 12 | 17 | 19 | 21 | 25 | 26 |
| 层级2 | 6 | 9 | 17 | 25 | ||||||
| 层级3 | 6 | 25 | ||||||||
| 层级4 | 6 |
总结:跳跃表的每层都是有序的,层次越高,节点数目数目越少,节点之间的跨度越大
A:查找:从高层索引节点往底层逐层查找,如果每次的节点分布均匀,时间复杂度O(logn),但是跳表实际往上层复制节点是通过抛硬币的方式确定,不能保证完全均匀,因此最坏的查找时间复杂度是O(n),即进行遍历。
B:插入:
1)新节点和各层索引节点逐一比较,确定原链表的插入位置。
2)把节点插入到底层链表中。
3)通过随机函数确定当前节点共存在于几层,
总体上,跳跃表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
C:删除
1)自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。
2)删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。
总体上,跳跃表删除操作的时间复杂度为O(logN)。
插入节点层数的确定:
- 宏定义ZSKIPLIST_P ,在源码中定义为了0.25,代码中生成n+1的概率是生成n的概率的4倍。
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}

问题:跳跃表与平衡树与hash表的对比?
1)跳跃表和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
2)在做范围查找的时候,平衡树比跳跃表操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳跃表上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
3)从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
4)查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
5)从算法实现难度上来比较,跳跃表比平衡树要简单得多。
- redis4.0中在server.h中定义了跳跃表
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度,当前节点在链表中位置,插入节点的时候可以使用其他节点的span确定当前节点的span
} level[]; // 当前节点层数
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 跳跃表的头/尾指针
unsigned long length; // 有序链表长度
int level; // 当前跳跃表总的层数
} zskiplist;

2-4-2 源码分析(待补充)
2-4-3 跳跃表总结
1)跳跃表是有序集合的底层实现之一,本质上是有序链表,每个链表的节点的层数是随机的,即部分节点会作为索引节点
2)跳跃表中的节点按照分值大小排序,分值相同按照对象大小排序
3)多个节点可以拥有相同的分值,但每个分值的对象是唯一的。

2-5 整数集合
2-5-1 整数集合定义
- 整数集合是redis用于保存整数值的集合抽象数据类型,redis集合键的底层数据结构会用到整数集合
#ifndef __INTSET_H
#define __INTSET_H
#include <stdint.h>
typedef struct intset {
uint32_t encoding; // 编码方式,设置存储的项是16位,32位,64位整数
uint32_t length; // 元素数量
int8_t contents[]; // 集合元素的存储数组(可以看到是字节为单位,支持16/32/64位整数)
} intset;
intset *intsetNew(void);
intset *intsetAdd(intset *is, int64_t value, uint8_t *success);
intset *intsetRemove(intset *is, int64_t value, int *success);
uint8_t intsetFind(intset *is, int64_t value);
int64_t intsetRandom(intset *is);
uint8_t intsetGet(intset *is, uint32_t pos, int64_t *value);
uint32_t intsetLen(const intset *is);
size_t intsetBlobLen(intset *is);
#ifdef REDIS_TEST
int intsetTest(int argc, char *argv[]);
#endif
注意:
- contents数组是整数集合的底层实现。整数集合每个元素都是数组中的项,并且项是按照从小到大的顺序排序且无重复
- 由于底层是数组实现,添加新元素的时间复杂度是O(n)
2-5-1 整数集合的升级
升级:集合中元素的数据类型的升级
发生时机:现有1个整数集合,之前插入10个16位整数,现在插入32位整数,那么在插入之前集合会进行升级操作,具体的工作包括:
step1: 为整数集合重新分配空间,空间大小等于 插入后元素个数 * 升级后的数据类型大小
step2: 将原先的低级元素进行升级,然后和新插入的元素一起放入到新分配的空间,放入的过程要保持有序性

整数集合升级机制的好处:
1)提升数据结构的灵活性,对于使用者可以透明的任意添加16位,32位,64位整数,
2)节约内存,必要时才需要更过内存,进行升级,如果整数集合的数字不超过16位,那么没必要采用64位的格式存储数据,当有64位才能表示的数字进来时,再进行内存的分配。
注意点:整数集合的升级是不可逆的,没有提供降级机制
2-5-3 整数集合总结
1)整数集合是redis的集合键的底层实现
2)整数集合底层是数组!!!,集合中的元素是有序的,数据添加的复杂度为O(N)
3)整数集合为了保证数据类型的灵活性的同时并节约内存在数据添加时,有必要时会进行数据类型的升级,并且升级是不可逆的
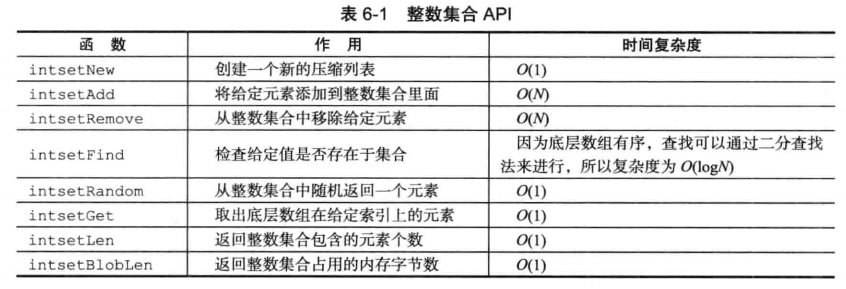
2-6 压缩列表
压缩链表:redis为节约内存开发的,是一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩链表包含任意多个节点,每个节点保存一个字节数组或者整数值
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previos entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
2-6 -1 压缩列表的组成

主要属性包括:列表大小,列表尾部节点位置,节点数量,多个节点,末端标记
2-6-2 压缩列表节点的组成
压缩链表的节点可以是字节数据还可以是整数值(压缩了)
| 压缩列表节点组成 | 含义 | 使用 | |
|---|---|---|---|
| previous entry length | 记录前一个节点的长度 | 列表的遍历 | |
| encoding | 保存数据类型以及字节数组的编码长度 | ||
| content | 保存节点的值 |
2-6-3 压缩列表的连锁更新
列表添加新节点与删除节点可能会触发连锁更新,(最坏情况下会造成每个节点空间的重新分配,最坏时间复杂度O(N^2))



3 redis的5种基本对象
3-1 对象的特点

问题:Redis中对象与数据结构的关系?
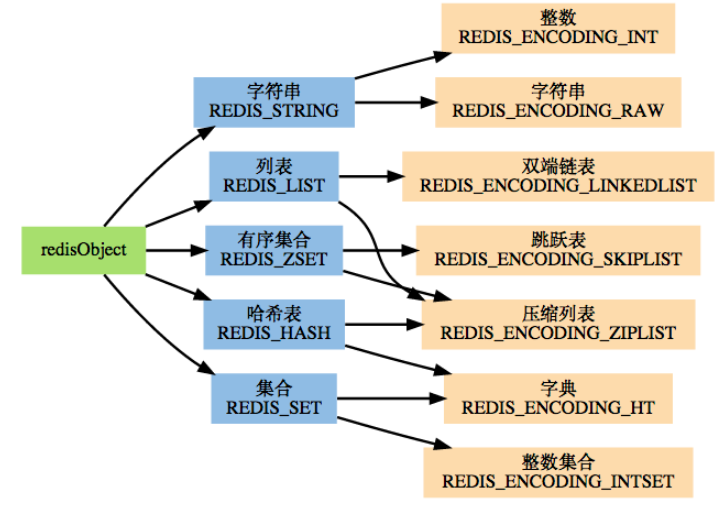
- 键的类型只能为字符串对象,值是5种对象:字符串、列表、集合、散列表、有序集合
- redis没有直接使用基本的数据结构来实现key-value数据库,而是基于主要数据结构创建对象系统。每个对象都用到了至少一种数据结构**
- 底层数据结构:简单动态字符串,双端链表,字典,压缩链表,整数集合。压缩链表
冷知识:有序集合名称由来?
Hello, as in XYZ, so the idea is, sets with another dimension: the order. It's a far association... I know
3-2 对象的组成(重要)
| redis对象的属性 | ||
|---|---|---|
| 对象类型(unsigned type) | 对象所使用的编码即对象所采用的基本数据结构 | 底层数据结构指针 |
通过对象中的编码属性以及底层数据结构指针来确定该对象使用哪种数据结构。

对象的类型就是上面5种基本类型。
术语:
字符串键:当前键所指向的对象是字符串对象
列表键:当前键所指向的是列表对象
对象的编码方式(重要)

| 对象类型 | 编码种类 | 方式1 | 方式2 | 方式3 | 备注 |
|---|---|---|---|---|---|
| 字符串对象 | 3 | long类型整数 | embstr编码SDS | SDS | |
| 列表对象 | 2 | 压缩列表 | 双端列表 | 无论那种实现本质上都是双端链表 | |
| 哈希对象 | 2 | 压缩列表 | 字典(hash数组) | ||
| 集合对象 | 2 | 有序整数集合(整数数组) | 字典(hash数组) | 集合对象的两种编码一个很大的差异整数集合中的元素是有序的。 | |
| 有序集合对象 | 2 | 压缩列表 | 跳跃表+字典(hash数组)!(综合两者优点) |
注意:压缩列表可以作为列表,hash,有序集合这三个对象的编码,但是使用条件必须是节点数目比较少的情况,否则将影响操作效率。
字符串对象


- 可以看到字符串对象的自增,自减操作是由于底层是long类型编码
列表对象
- 注意这两个值是可以修改的

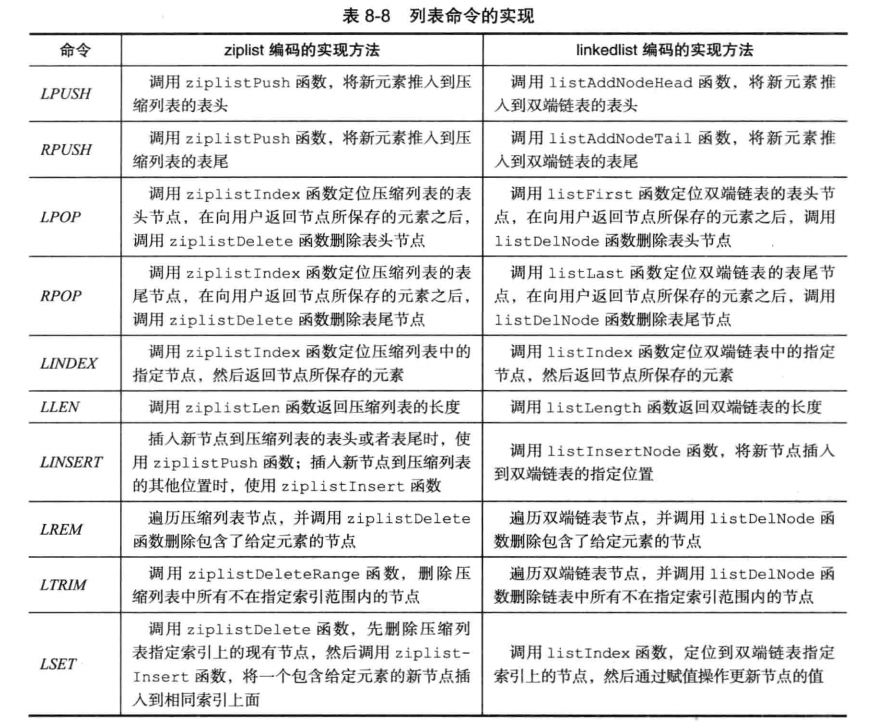
- 可以看到无论采用压缩列表还是普通链表,都是双端链表,支持头尾插入与删除
hash对象
- 注意这两个值是可以修改的

set对象

- 第二个条件可以修改
zset对象

- 综合了hash表查找迅速以及跳表的有序性的优点

- 上面2个条件同样可修改
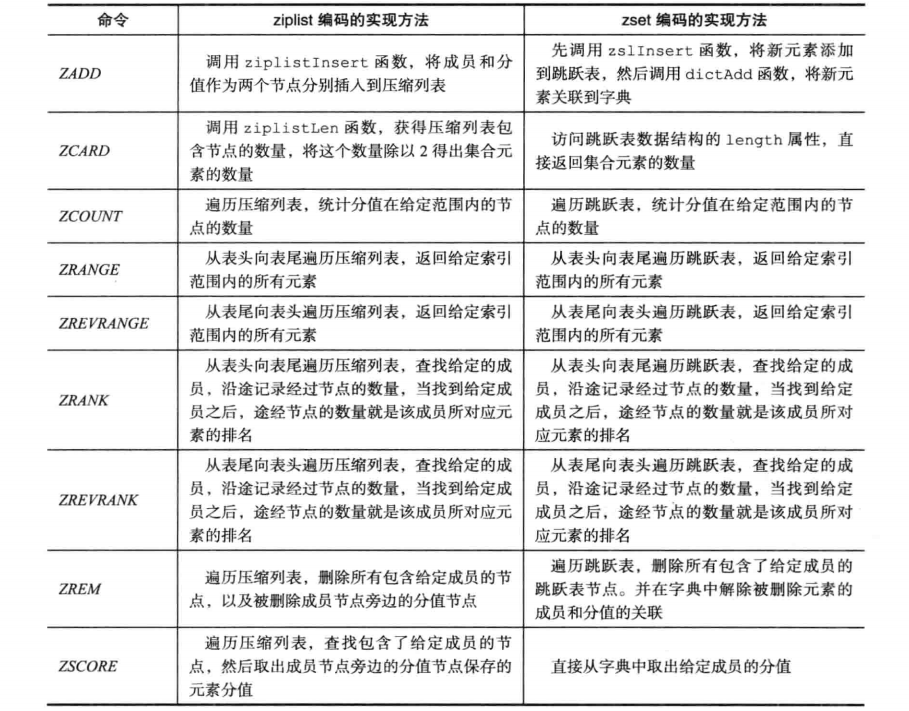
- 压缩链表都是适合数据规模比较小的时候使用
3-3 对象的回收与共享
- redis采用引用计数的方式判断对象是否可以回收
基于引用技术的对象共享(不同的key共享相同的value对象)
-
适用的对象:仅用于包含整数值的字符串对象以及嵌套了整数值的字符串对象



-
对象的共享本质上也是享员模式的体现