由于各种原因,mysql主从架构经常会出现数据不一致的情况出现,大致归结为如下几类
- 1:备库写数据
- 2:执行non-deterministic query
- 3:回滚掺杂事务表和非事务表的事务
- 4:binlog或者relay log数据损坏
数据不同步给应用带来的危害是致命的,当出现主从数据不一致的情况,常见的应对方法是先把从库下线,然后找个半夜三更的时间把应用停掉,重新执行同步,如果数据库的体积十分庞大,那工作量可想而知,会让人崩溃。本文介绍使用percona-toolkit工具对mysql主从数据库的同步状态进行检查和重新同步。
一:安装percona-toolkit
- # yum -y install perl-Time-HiRes
- # wget
- http://www.percona.com/downloads/percona-toolkit/2.2.13/tarball/percona-toolkit-2.2.13.tar.gz
- # tar -zxvpf percona-toolkit-2.2.13.tar.gz
- # cd percona-toolkit-2.2.13
- # perl Makefile.PL
- # make
- # make install
二:修改mysql 的binlog格式binlog_format参数为row格式
mysql binlog日志有三种格式,分别为Statement, Mixed,以及ROW!
1.Statement:
每一条会修改数据的sql都会记录在binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。(相比row能节约多少性能与日志量,这个取决于应用的SQL情况,正常同一条记录修改或者插入row格式所产生的日志量还小于Statement产生的日志量,但是考虑到如果带条件的update操作,以及整表删除,alter表等操作,ROW格式会产生大量日志,因此在考虑是否使用ROW格式日志时应该跟据应用的实际情况,其所产生的日志量会增加多少,以及带来的IO性能问题。)
缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同 的结果。另外mysql 的复制,像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数, last_insert_id(),以及user-defined functions(udf)会出现问题).
2.Row
不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点: binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题
缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如一条update语句,修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。
3.Mixed
是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种.新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
主从数据库分别修改my.cnf文件相关配置项如下:
- binlog_format=ROW


三:使用pt-table-checksum工具检查数据一致性情况
用法参考:
假设192.168.1.205是主库,192.168.1.207是它的从库,端口在3306。
1. 先校验
- # pt-table-checksum --user=root --password=123456
- --host=192.168.1.205 --port=3306
- --databases=test --tables=t2 --recursion-method=processlist
- --no-check-binlog-format --nocheck-replication-filters
- --replicate=test.checksums
2. 根据校验结果,只修复192.168.1.207从库与主库不一致的地方:
- # pt-table-sync --execute --replicate
- test.checksums --sync-to-master h=192.168.1.207,P=3306,u=root,p=123456
3. 修复后,再重新校验一次。执行第一步的语句即可。
4. 检查修复结果: 登陆到192.168.1.207,执行如下sql语句返回若为空,则说明修复成功:
- SELECT
- *
- FROM
- test.checksums
- WHERE
- master_cnt <> this_cnt
- OR master_crc <> this_crc
- OR ISNULL(master_crc) <> ISNULL(this_crc)
各参数含义
- --nocheck-replication-filters:不检查复制过滤器,建议启用。后面可以用--databases来指定需要检查的数据库。
- --no-check-binlog-format:不检查复制的binlog模式,要是binlog模式是ROW,则会报错。
- --replicate-check-only:只显示不同步的信息。
- --replicate=:把checksum的信息写入到指定表中,建议直接写到被检查的数据库当中。
- --databases=:指定需要被检查的数据库,多个则用逗号隔开。
- --tables=:指定需要被检查的表,多个用逗号隔开
- h=127.0.0.1:Master的地址
- u=root:用户名
- p=123456:密码
- P=3306:端口
下面我们来模拟下主从数据库不同步情况下的pt-table-checksum,为了方便,这里我们采用test schema
1: 主库上建表,插入测试数据
- mysql> create table t2 (id int primary key,name varchar(100) not null,salary int);
- mysql> CREATE PROCEDURE test_insert ()
- BEGIN
- DECLARE i INT DEFAULT 0;
- WHILE i<10000
- DO
- INSERT INTO t2
- VALUES
- (i,CONCAT('员工',i), i);
- SET i=i+1;
- END WHILE ;
- END;;
- mysql> CALL test_insert();
从库上校验当前数据的同步情况为正常。
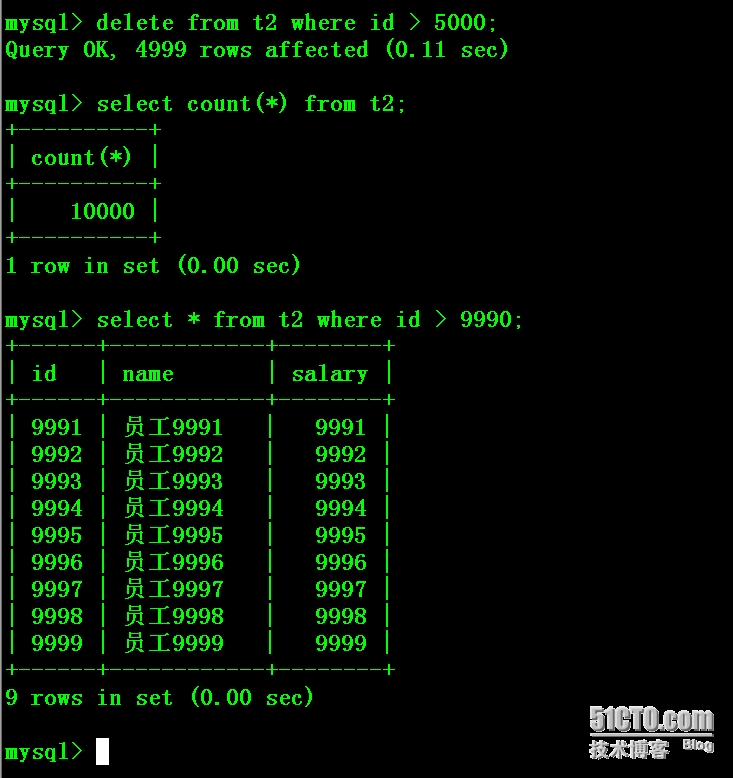
从库上删除一半的数据
- mysql> delete from t2 where id > 5000;
- Query OK, 4999 rows affected (0.14 sec)
- mysql> select count(*) from t2;
- +----------+
- | count(*) |
- +----------+
- | 5001 |
- +----------+
- 1 row in set (0.01 sec)
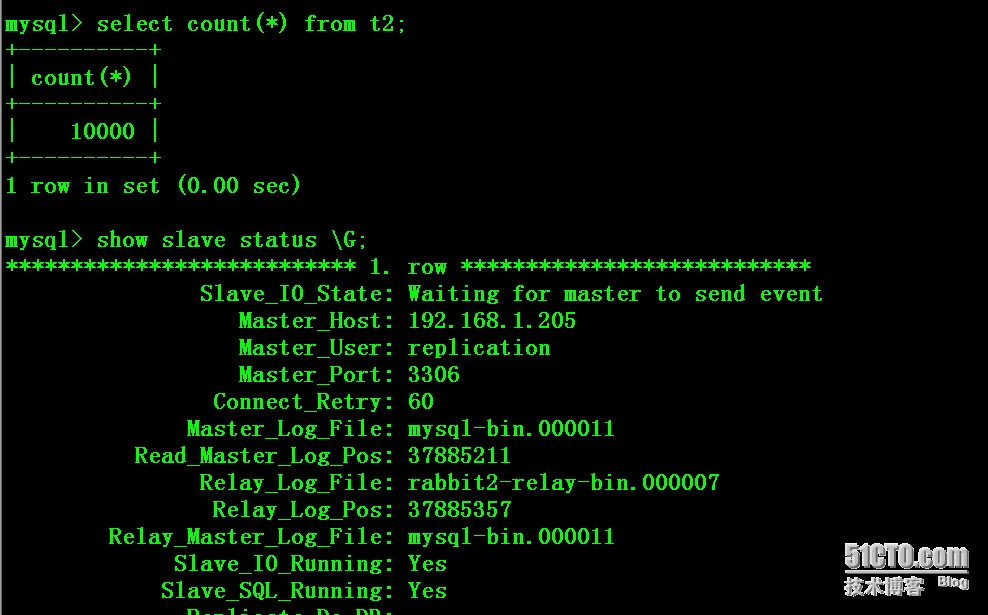
2:使用pt-table-checksum工具进行校验:
- # pt-table-checksum --user=root --password=123456
- --host=192.168.1.205 --port=3306
- --databases=test --tables=t2 --recursion-method=processlist
- --no-check-binlog-format --nocheck-replication-filters
- --replicate=test.checksums

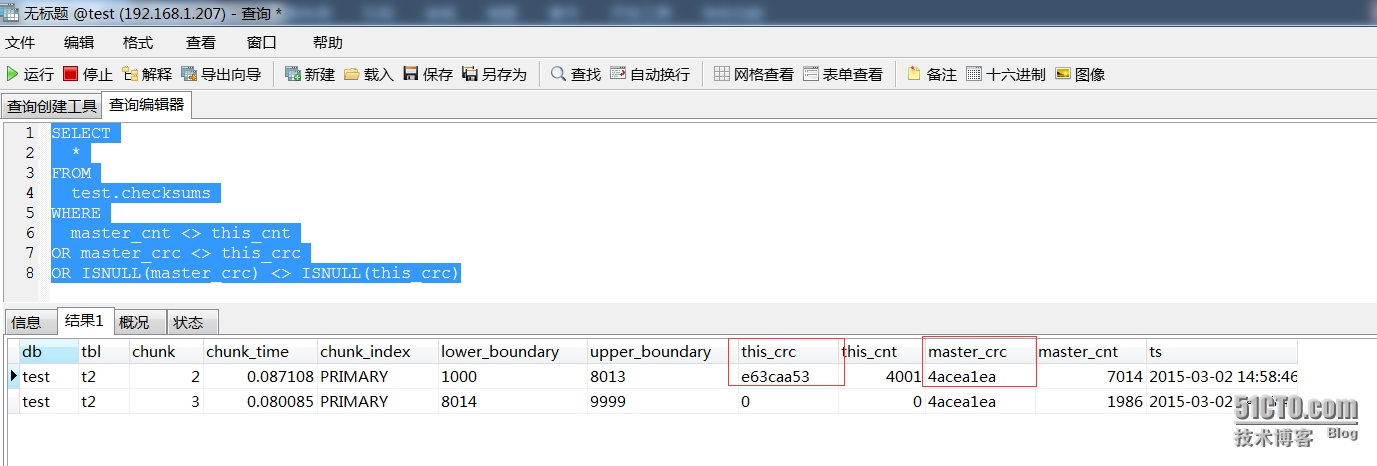
3:登陆从库进行查询checksum表
- mysql> SELECT
- *
- FROM
- test.checksums
- WHERE
- master_cnt <> this_cnt
- OR master_crc <> this_crc
- OR ISNULL(master_crc) <> ISNULL(this_crc)
4:使用pt-table-sync工具进行数据重新同步
- # pt-table-sync --execute --replicate
- test.checksums --sync-to-master h=192.168.1.207,P=3306,u=root,p=123456
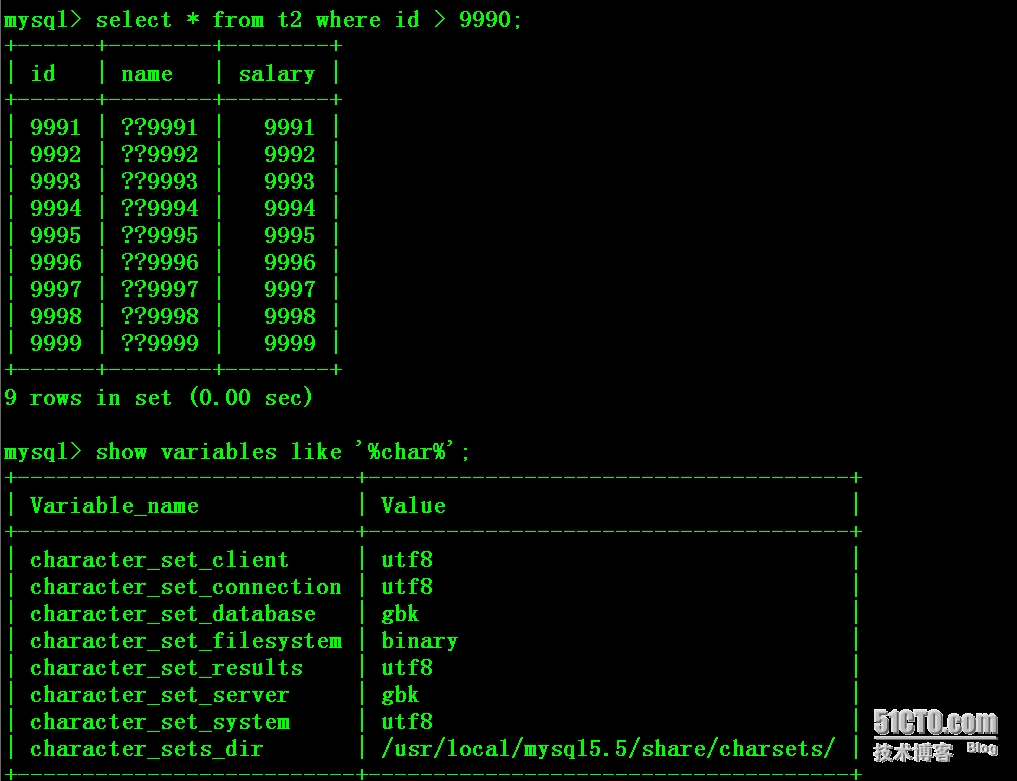
5:从库上验证数据,中文“员工”变成了“??”
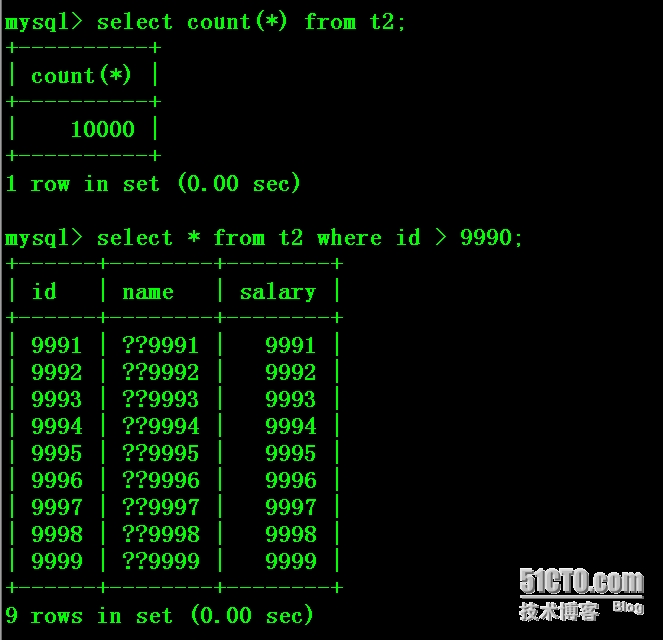
检查主库,发现出现一样的情况,中文“员工”变成了“??”,猜想和字符集设置相关。
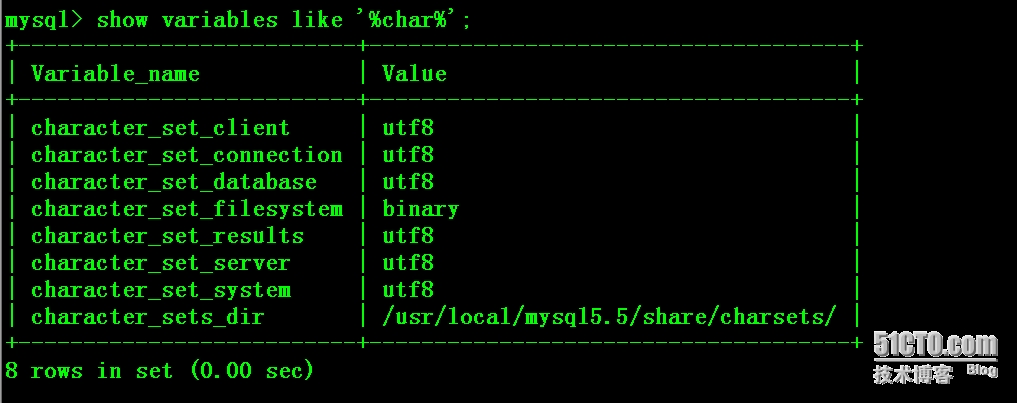
于是检查数据库字符集设置,发现test库字符集非utf8
主从库my.cnf文件添加如下配置项后重启数据库实例
- character_set_client=utf8
- character_set_server=utf8
重新执行以上1-4步,发现一切正常!关键第4步要加--charset=utf8 参数
- # pt-table-sync --execute --replicate
- test.checksums --charset=utf8
- --sync-to-master h=192.168.1.207,P=3306,u=root,p=123456