最大熵模型的意义和形式
第一次系统提出最大熵的原理的一般认为是Jaynes,后来有人提出了相应的算法来估计对应的统计模型的参数。由于当时计算条件的限制,最大熵模型在人工智能和自然语言处理领域都没有得到广泛应用。上世纪90年代,IBM的研究员应用重新深入的研究了这个问题,系统地描述了条件最大熵的框架和实现算法,并在自然语言处理任务上取得了非常好的效果,引起了人们的重视。很快条件最大熵模型技术得到了广泛的传播,在自然语言处理的各个领域都取得了巨大的成功,在此基础上的一些深入研究工作也不断展开。最大熵模型已经成为近年来自然语言处理领域最成功的机器学习方法。
假设我们的分类任务或者预测任务的类别为![]() ,而我们能够依据的上下文信息记为
,而我们能够依据的上下文信息记为![]() ,
,![]() 。我们希望对于不同的给定的上下文x条件下,统计模型能够给出判为不同类别y的概率值
。我们希望对于不同的给定的上下文x条件下,统计模型能够给出判为不同类别y的概率值![]() 。因此,我们希望能够建立一种区分性的条件概率模型
。因此,我们希望能够建立一种区分性的条件概率模型![]() (注意,我们这里仍然用了
(注意,我们这里仍然用了![]() 的表示形式,但是此处的意义表示的是整个的概率分布,
的表示形式,但是此处的意义表示的是整个的概率分布,![]() 也不再表示具体的实例)。我们用
也不再表示具体的实例)。我们用![]() 来表示所有这种条件概率模型的集合,而我们期望得到的模型就是
来表示所有这种条件概率模型的集合,而我们期望得到的模型就是![]() 中的一种。所谓的条件最大熵模型,就是在
中的一种。所谓的条件最大熵模型,就是在![]() 中一定约束下条件熵最大的模型。
中一定约束下条件熵最大的模型。
所谓的约束,也就是我们已知的信息,可以认为我们希望模型在这些信息上能和训练数据匹配。而熵最大,则表明除约束外,我们不再做未知的假设。在条件最大熵模型中,约束是通过特征的形式来体现的。这里的特征和语音识别等领域的特征有所不同,它表示成![]() 和
和![]() 的函数的形式
的函数的形式![]() ,表示了x的某种属性和y的共现情况。特征函数理论上可以取任何实数值(早期因为训练算法的原因只能取正值),在自然语言处理领域一般表示为0-1的指示函数的形式,例如:
,表示了x的某种属性和y的共现情况。特征函数理论上可以取任何实数值(早期因为训练算法的原因只能取正值),在自然语言处理领域一般表示为0-1的指示函数的形式,例如:
![]()
我们定义特征函数f的经验期望如下:
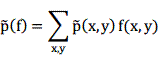
![]() 表示样本
表示样本![]() 在训练语料
在训练语料![]() 中出现的经验概率:
中出现的经验概率:
![]()
而特征函数f的模型期望为:
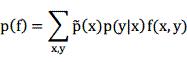
最大熵模型的约束就是使得任意特征![]() 的经验期望和模型期望相等:
的经验期望和模型期望相等:

我们认为我们定义的特征集合描述了训练样本的信息,而我们的模型在这些信息的层面上和训练数据保持了一致。
我们将满足这些约束的条件概率的![]() 中的一个子集定义为
中的一个子集定义为![]() ,而条件熵的定义为:
,而条件熵的定义为:
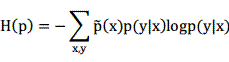
那我们需要得到的就是在![]() 中条件熵
中条件熵![]() 最大的模型p:
最大的模型p:
![]()
根绝概率公式的定义,我们还有另外一个约束:
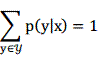
那么以上两个式子就构成了一个约束最优化问题,可以用拉格朗日乘子法来计算:
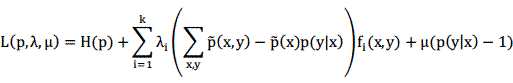
可以解得模型p的形式为:
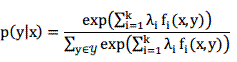
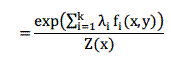
这就是条件最大熵模型的形式,而对应的
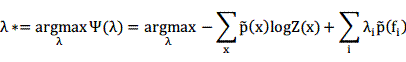
这里的拉格朗日乘子![]() 相当于特征
相当于特征![]() 的权重,为了以后讨论的方便,换用
的权重,为了以后讨论的方便,换用![]() 表示:
表示:
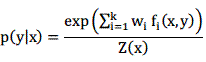
如果已知模型是上式的形式,那么在训练数据上的log似然值为:

通过上式我们可以发现,通过最大似然求解最优权将和的结果是一样的。也就是说在约束下的条件熵最大的模型也就是具有形式且使得在训练数据上似然值最大的模型。
训练算法和参数估计
虽然使得![]() 最大的
最大的![]() *是我们的最优权值解,但是式子却没有一个直接的数值解,但是幸运的是,具有凸函数的性质,因此我们想求得最优的
*是我们的最优权值解,但是式子却没有一个直接的数值解,但是幸运的是,具有凸函数的性质,因此我们想求得最优的![]() ,只需要使得:
,只需要使得:
![]()
而通过计算我们可以得到:
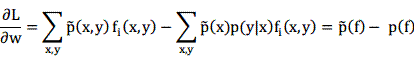
恰好就是上文所提的约束条件。在设定的权值参数下,似然值的梯度是容易计算的。因此权值参数估计的方法可以通过基于梯度的数值优化算法进行,比如共轭梯度(Conjugate Gradient, CG),拟牛顿方法(quasi-Newton)等等。目前最常用的是一种称为L-BFGS的拟牛顿方法(limited memory BFGS),它在优化性能和速度上都表现良好,特别是相对于早期的以前基于迭代缩放的IIS(improved iterative scaling)、GIS(generalized iterative scaling)最大熵模型参数估计方法优势明显。
正则化
采用最大似然方法训练出的最大熵模型能够在训练数据上表现良好,但是不一定在未知数据上具有好的推广性。特别是出现在参数数量巨大而训练数据又不是很充足的情况下。一种解决方案是设立一定数量的开发集,当在开发集上性能下降时停止训练。但是这并不是一个很好的策略,因为可能暂时的下降之后还会上升。
另一种思路就是在优化目标上改变,可以增加关于参数的先验知识,也被称为一种“正则化”的策略。设定我们的参数集为w,训练样本集合为D,那么根据贝叶斯公式有:
![]()
其中,![]() 成为给定D下参数w的后验,
成为给定D下参数w的后验,![]() 成为w在D上的似然,
成为w在D上的似然,![]() 称为w的先验。最大似然轨迹其实就是假设w的先验为均匀分布,直接最大化似然
称为w的先验。最大似然轨迹其实就是假设w的先验为均匀分布,直接最大化似然![]() 就可以了。
就可以了。
而我们可以通过假设一个先验分布,来防止有些权值被过训练,一个常用的分布就是高斯分布。

根据:
![]()
那么相应的目标函数就变为:
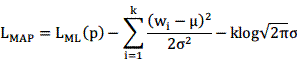
梯度的计算变为:
![]()
这种变化对我们以前所讲的参数估计参数影响不大,但却可以十分有效地防止过训练的问题。
模型训练
- 假定第零次迭代的初始模型为等概率的均匀分布。
- 用第 N 次迭代的模型来估算每种信息特征在训练数据中的分布,如果超过了实际 的,就把相应的模型参数变小;否则,将它们便大。
- 重复步骤 2 直到收敛。
Darroch 和 Ratcliff没有能对这种算法的物理含义进行很好地解释,后来是由Csiszar解释清楚的,因此,人们在谈到这个算法 时,总是同时引用 Darroch 和Ratcliff 以及希萨的两篇论文。GIS 算法每次迭代的时间都很长,需要迭代很多次才能收敛,而且不太稳定,即使在 64 位计算机上都会出现溢出。因此,在实际应用中很少有人真正使用,大家只是通过它来了解最大熵模型的算法。
八十年代,Della Pietra在IBM对GIS算法进行了两方面的改进,提出了改进迭代算法IIS(improved iterative scaling)。这使得最大熵模型的训练时间缩短了一到两个数量级。这样最大熵模型才有可能变得实用。即使如此,在当时也只有 IBM 有条件是用最大熵模型。
最大熵模型的优点
- 建模时,试验者只需集中精力选择特征,而不需要花费精力考虑如何使用这些特征。
- 特征选择灵活,且不需要额外的独立假定或者内在约束
- 模型应用在不同领域时的可移植性强
- 可结合更丰富的信息
最大熵模型的缺点
-
- 数据稀疏问题严重
- 对语料库的依赖性较强