计算机视觉研究的主要是人工智能, 计算机图形学是数字图像的合成产生技术,而数字图像图像处理则是图像数据的分析加工 (图形学的逆过程)
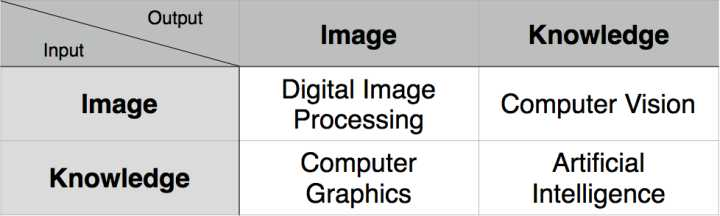
Computer Graphics,简称 CG 。输入的是对虚拟场景的描述,通常为多边形数组,而每个多边形由三个顶点组成,每个顶点包括三维坐标、贴图坐标、rgb 颜色等。输出的是图像,即二维像素数组。
Computer Vision,简称 CV。输入的是图像或图像序列,通常来自相机、摄像头或视频文件。输出的是对于图像序列对应的真实世界的理解,比如检测人脸、识别车牌。
Digital Image Processing,简称 DIP。输入的是图像,输出的也是图像。Photoshop 中对一副图像应用滤镜就是典型的一种图像处理。常见操作有模糊、灰度化、增强对比度等。
再说联系:
CG 中也会用到 DIP,现今的三维游戏为了增加表现力都会叠加全屏的后期特效,原理就是 DIP,只是将计算量放在了显卡端。
CV 更是大量依赖 DIP 来打杂活,比如对需要识别的照片进行预处理。
最后还要提到近年来的热点——增强现实(AR),它既需要 CG,又需要 CV,当然也不会漏掉 DIP。它用 DIP 进行预处理,用 CV 进行跟踪物体的识别与姿态获取,用 CG 进行虚拟三维物体的叠加。
先说区别
1. Computer Graphics,简称 CG 。输入的是对虚拟场景的描述,通常为多边形数组,而每个多边形由三个顶点组成,每个顶点包括三维坐标、贴图坐标、rgb 颜色等。输出的是图像,即二维像素数组。
[xyz xyz xyz ... xyz] -> 图片
2. Computer Vision,简称 CV。输入的是图像或图像序列,通常来自相机、摄像头或视频文件。输出的是对于图像序列对应的真实世界的理解,比如检测人脸、识别车牌、区分猫狗。
图片 -> dog or cat?
图片 -> [xyz xyz xyz ... xyz]
3. Digital Image Processing,简称 DIP。输入的是图像,输出的也是图像。Photoshop 中对一副图像应用滤镜就是典型的一种图像处理。常见操作有模糊、灰度化、增强对比度等。
图片 -> ps后的图片
再说联系
1. CG 中也会用到 DIP,现今的三维游戏为了增加表现力都会叠加全屏的后期特效,原理就是 DIP,只是将计算量放在了显卡端。通常的做法是绘制一个全屏的矩形,在 Pixel Shader 中进行图像处理。
2. CV 大量依赖 DIP 来打杂活,比如对需要识别的照片进行预处理,增强对比度、去除噪点。
3. 最后还要提到今年的热点——增强现实(AR),它既需要 CG,又需要 CV,当然也不会漏掉 DIP。它用 DIP 进行预处理,用 CV 进行跟踪物体的识别与姿态获取,用 CG 进行虚拟三维物体的叠加。
如果读者留意 OpenCV 2.3 之后的版本,那么会发现 cv::ogl namespace,ogl 自然是 OpenGL了。一个三维计算机图形库为何出现在计算机视觉中,传统的 CV 开发者是否需要学习它,这些问题待我一一来回答。
问题一:为何引入 OpenGL?
在 2.3 之前 OpenCV 的渲染部分都是由 CPU 来实现的,不论是画线还是把图片显示到屏幕上。这有两个问题,速度慢,同时没法画三维物体。引入 OpenGL 是为了借助 显卡的力量,显卡比 CPU 更擅长渲染,同时显卡和 CPU 可以同时干活。比方说,CPU 在获取摄像头画面然后检测人脸时,显卡在渲染三维的人脸网格模型和高精度抗锯齿的二维界面。
另外,随着民用深度传感器的普及,cv::VideoCapture 第一时间增加了对 Kinect、华硕 Xtion、Intel Perceptual Computing SDK 等的支持。传统的视觉计算中,深度图只能当做单通道的灰度图进行处理。想实现隔空的多点触摸是绰绰有余,但是如果想实现三维重建(比如 Kinect Fushion)那么我们必须将算法升级到三维空间。相应的,三维空间的算法也需要三维的 API 进行渲染,也就是 OpenGL。
想开启该功能,需要在配置 CMake 时选上 WITH_OPENGL=ON,然后重新编译完整的 OpenCV 库。我简要介绍下几个组件:
- ogl::Buffer 是 OpenGL 中的缓存区,可以用于保存多边形的顶点和颜色等。
- ogl::Texture2D 是保存在显卡中的二维贴图,可以认为是得到 GPU 加速的 cv::Mat。
前面这两个类都只是保存数据,要把数据画出来,还要用到 ogl::render 函数。
void ogl::render(const Texture2D& tex, Rect_<double> wndRect=Rect_<double>(0.0, 0.0, 1.0, 1.0), Rect_<double> texRect=Rect_<double>(0.0, 0.0, 1.0, 1.0))
问题二:是否应该学习 OpenGL?
It depends.
如果你开发的是命令行程序并不显示任何图像,或者显示的图片很简单,那么不需要转换到 cv::ogl 下。
如果你的应用耗费了大量时间在图片的显示上,或是希望拥有高质量的界面系统,那么你可以借助 cv::ogl::Texture2D 加速图像的渲染。
如果你开发的是增强现实应用,你肯定已经拥有了自己的三维渲染模块,可以考虑与 cv::ogl::Buffer 整合。
如果你已经在使用 CUDA 模块,对于渲染的时候数据需要回传到 CPU 表示多此一举,那么你可以使用 CUDA 与 OpenGL 的协同功能去除多余的数据传输。
另一方面,如果你不是 OpenCV 的用户但是你正在开发虚拟现实应用,你可以考虑将视觉计算引入到你的系统中,实现类似 HoloLens 的设备。
未来展望:OpenCV 与显卡的关系
由于显卡能力的增强以及硬件公司的支持,OpenCV 逐渐展露出新的形态,大量的视觉计算位于显卡上。
- 运算通过 CUDA 模块或 OpenCL 模块,这两个模块分别得到 NVIDIA 与 AMD 的大力支持。
- 渲染通过 OpenGL 模块。
这意味着除了文件读写(highgui 模块)外,视觉应用可以逐渐脱离 CPU。