四种主要的数据挖掘任务:
1、预测建模任务
- 分类:用于预测离散的目标变量
- 回归:用于预测连续的目标变量
2、关联分析
3、聚类分析
4、异常检测
主要的数据质量问题:存在噪声和离群点,数据遗漏、不一致或重复,数据有偏差,或者在别的方面,数据不代表描述所设想的现象或总体情况。
测量标度:将数值或符号值与对象的属性相关联的规则(函数),通常将属性的类型称为测量标度的类型
数据集主要分为三类:记录数据,基于图形的数据、有序的数据
一般数据集的三个特性:
- 维度:数据集中的对象具有的属性数目,数据预处理的一个重要动机是维规约。
- 稀疏性:如具有非对称特征的数据集,只有非零值才需要处理。
- 分辨率:如果分辨率太高,分类太细,模式可能看不到,或者掩埋在噪声里,如果分辨率太低,模式可能不出现。
记录数据的不同类型:
- 事物数据或购物篮数据:非关系型数据,例如每个消费者的购物时一条记录,购物车里的所有东西构成数据集
- 数据矩阵:数据对象看做多维空间中的点,每个维代表描述对象的一个不同属性。
- 稀疏数据矩阵:文档-词矩阵
基于图形的数据:
- 带有对象之间联系的数据,如网页链接
- 具有图形对象的数据,如化学分子
有序数据:
- 时序数据,又叫时间数据,每个记录包含与之相关联的时间
- 序列数据:如基因序列
- 时间序列数据:如气温时间序列,要考虑时间自相关,时间接近的测量值通常非常相似
- 空间数据:如不同地理位置的信息,考虑空间自相关性
数据清理:对数据质量问题的检测和纠正
抽样:数据挖掘处理所有的数据的费用太高,太费时间,因此使用抽样的算法可以压缩数据量,从而可以使用更好但开销更大的算法
特征子集的选择有三个标准选择方法:
- 嵌入方法:在数据挖掘算法运行期间,算法本身决定使用哪些属性和忽略哪些属性。例如构造决策树分类的算法。
- 过滤方法:使用某种独立于数据挖掘任务的方法,在数据挖掘算法运行之前进行特征选择,例如我们可以选择属性的集合,他的属性对之间的相关度尽可能低。
- 包装方法:这些方法将目标数据挖掘算法作为黑盒,使用类似于便利所有可能集合的方法,但通常不会全部遍历一次。
特征创建:可以有原来的属性创建新的属性集,新的属性集可能比原有的要少,主要三种方法
- 特征提取:由原始数据创建新的特征集
- 映射数据到新的空间:例如对时间序列实施傅里叶变换,小波变换
- 特征构造:由原始特征构造成新特征
相似性和相异性的度量
- 相似度:两个对象相似的程度,通常非负的,在0到1之间取值,两个对象越相似相似度就越高
- 相异度:两个对象差异程度的数值度量,对象越类似,相异度就越低,距离是相异度的同义词
欧几里德距离是指多维空间两点间的距离,这是一种用直尺测量出来的距离。
如果将两个点分别标记为(p1,p2,p3....pn)和(q1,q2,q3.....qn),则欧几里德距离的计算公式为:

欧几里得公式的性质:
- 非负性
- 对于所有x和y,d(X,Y)>=0;
- 仅当x=y时,d(x,y)=0;
- 对称性
- 对于所有x和y,d(x,y)=d(y,x)
- 三角不等式
- 对于所有x,y,z,d(x,z)<=d(x,y)+d(y,z)
对于两个有n个二元属性的对象x和y来说,可以用简单匹配系数,公式为
SMC=(值匹配的属性个数/属性个数)=(f₁₁+f00)/(f00 + f10 + f01 + f11) 其中f11表示x取1并且y取1的属性个数,其他类推
对于非对称的二元属性,则用Jaccard系数来处理,忽略0-0匹配
对于文档相似性,用余弦相似度处理 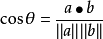
如果余弦相似度为1,则除大小外,x和y是相同的,如果余弦相似度为0,则他们不包含任何相似的词