分区表简介
分区表是SQL Server2005新引入的概念,这个特性在逻辑上将一个表在物理上分为多个部分。(即它允许将一个表存储在不同的物理磁盘里)。在SQL Server2005之前,分区表实际上是分布式视图,也就是多个表做union操作。
分区表在逻辑上是一个表,而物理上是多个表。在用户的角度,分区表和普通表是一样的,用户角度感觉不出来。
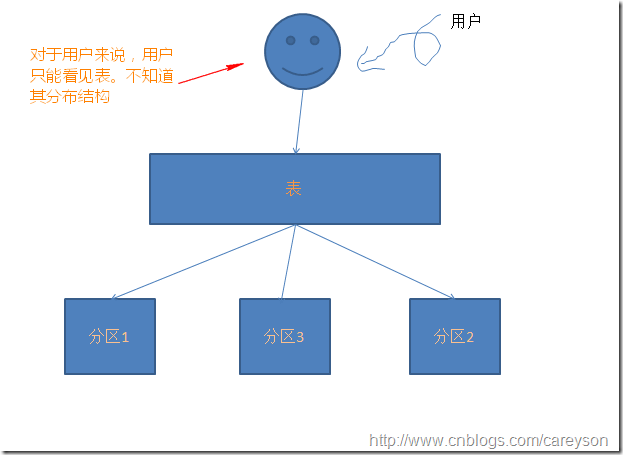
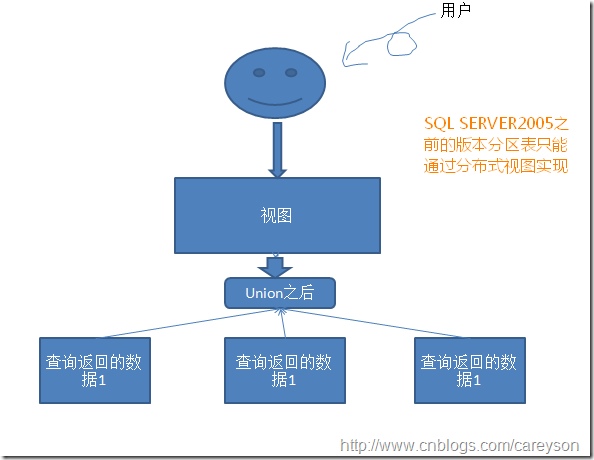
而在SQL Server2005之前,由于没有分区的概念,所谓的分区仅仅是分布式视图:
对表分区的理由
表分区这个特性,只有SQL Server企业版或SQL Server开发版才有,理解表分区的概念之前,还得先理解SQL Server中文件和文件组的概念。这篇文章是解释文件和文件组的。http://www.cnblogs.com/kissdodog/p/3156166.html
表分区主要用于:
- 提供性能:这个是大多人数分区的目的,把一个表分部到不同的硬盘或其他存储介质中,会大大提升查询速度。
- 提高稳定性:当一个分区出了问题,不会影响其他分区,仅仅是当前坏的分区不可用。
- 便于管理:把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区。
- 存档:将一些不太常用的数据,单独存放。如:将1年前的数据记录分到一个专门的存档服务器存放。
分区表的操作步骤
分区表分为三个步骤:
- 定义分区函数
- 定义分区构架
- 定义分区表
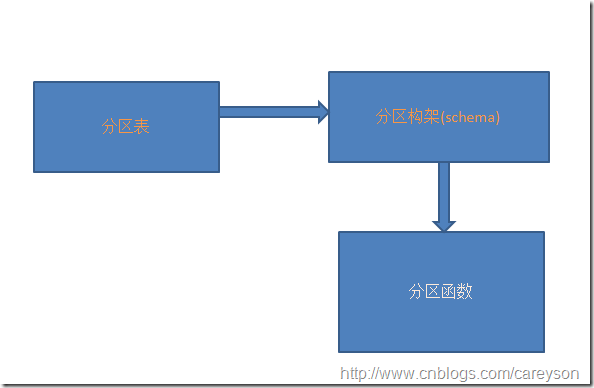
分区函数,分区构架和分区表的关系如下:分区表依赖于分区构架,分区构架又依赖分区函数。因此,定义分区表的顺序基本上是定义分区函数->定义分区构架->定义分区表。
实际操作,先定义一张需要分区的表:
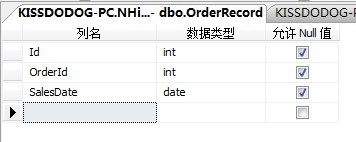
我们以SalesDate列作为分区列。
第一步,定义分区函数:
分区函数用于判断一行数据属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区。如上面的分区表,可以通过设置SalesDate的值来判定其不同的分区,加入我们定义了SalesDate的两个边界值进行分区,则会生成三个分区,现在设置两个边界值分别为2004-01-01和2007-01-01,则上面的表就可以根据这两个边界值分出三个分区。
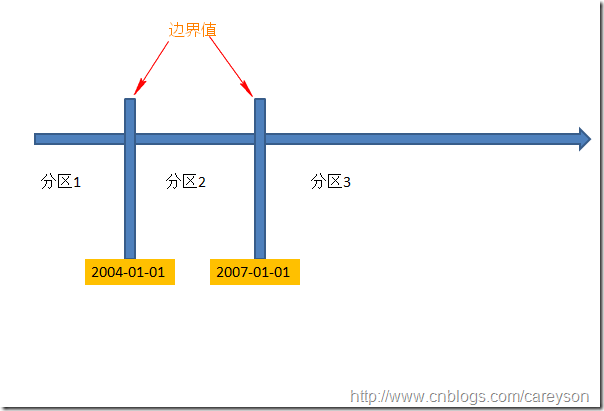 (CareySon大牛给的图,真的放方便理解。)
(CareySon大牛给的图,真的放方便理解。)
定义分区函数的语法如下:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,...n ] ] ) [ ; ]
在上面定义分区函数的原型语法中,我们看到其中并没有涉及到具体的表,因为分区函数并不和具体的表绑定。另外原型中还可以看到Range left和right。这个参数决定临界值(也就是刚好等于2004-01-01或2007-01-01的这些与分界值相等的值)应该归于左边还是右边。

创建分区函数:
--创建分区函数 CREATE PARTITION FUNCTION fnPartition(DATE) AS RANGE RIGHT FOR VALUES('2004-01-01','2007-01-01') --查看分区表是否创建成功 SELECT * FROM sys.partition_functions
上述查询语句显示结果如下:

通过系统视图,可以看见这个分区函数已经创建成功。
第二步,定义分区构架
定义完分区函数仅仅知道了根据列的值将数据分配到不同的分区。而每个分区的存储方式,则需要分区构架来定义。
分区构架语法原型:
CREATE PARTITION SCHEME partition_scheme_name AS PARTITION partition_function_name [ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] ) [ ; ]
从原型来看,分区构架仅仅是依赖分区函数。分区构架负责分配每个区属于哪个文件组,而分区函数是决定哪条数据属于哪个分区。
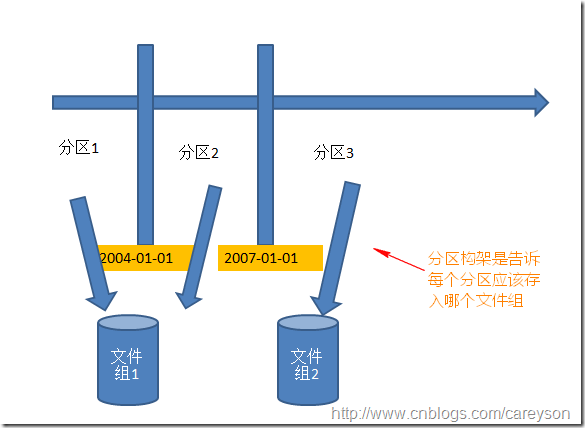
基于之前创建的分区函数,创建分区构架:
--基于之前的分区函数创建分区构架schema CREATE PARTITION SCHEME SchemaForParirion AS PARTITION fnPartition --这个是之前创建的分区函数 TO(FileGroup1,[primary],FileGroup1) --FileGroup1是自己添加的文件组,因为有两个分界值,3个分区,所以要指定3个文件组,也可以使用ALL所谓的分区指向一个文件组 --查看已创建的分区构架 SELECT * FROM sys.partition_schemes
以上SELECT语句输出结果如下:

留意到分区构架已成功创建。
第三步:定义分区表
有了分区函数与分区构架,下面就可以创建分区表了,表在创建的时候就要决定是否是分区表了。虽然在大部分情况下,都是在发现表太大时,才想到要分区。但是分区表只能够在创建的时候指定为分区表。
CREATE TABLE OrderRecords ( Id int, OrderId int, SalesDate Date ) ON SchemaForParirion(SalesDate) --SchemaForPartition是刚刚定义的分区架构,括号内为指定的分区列
然后手工向数据库里面添加3条数据:
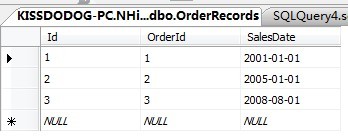
然后执行查询:
select convert(varchar(50), ps.name) as partition_scheme, p.partition_number, convert(varchar(10), ds2.name) as filegroup, convert(varchar(19), isnull(v.value, ''), 120) as range_boundary, str(p.rows, 9) as rows from sys.indexes i join sys.partition_schemes ps on i.data_space_id = ps.data_space_id join sys.destination_data_spaces dds on ps.data_space_id = dds.partition_scheme_id join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id join sys.partitions p on dds.destination_id = p.partition_number and p.object_id = i.object_id and p.index_id = i.index_id join sys.partition_functions pf on ps.function_id = pf.function_id LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id and v.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE i.object_id = object_id('OrderRecords') --此处是表名 and i.index_id in (0, 1) order by p.partition_number
可以看到,分区起作用了:
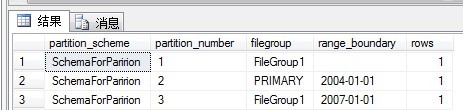
分区表的分割
分区表的分割,相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容。
新加入多一个分割点:2009-01-01。如下图所示:
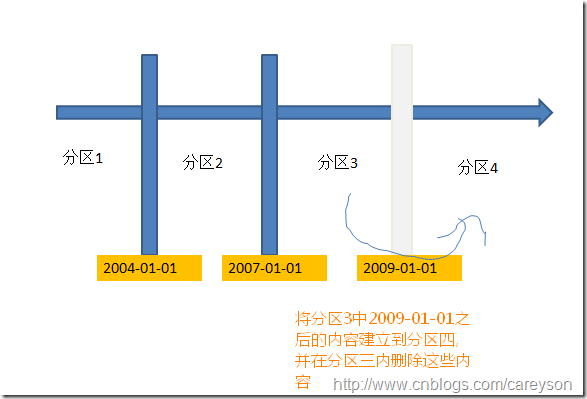
对于上图的操作,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应的数据。
这种操作非常非常消耗IO,并且在分割的过程中锁定分区3内的内容,造成分区3的内容暂时不可用。而且,这个操作生成的日志内容将会是被转移数据的4倍。
因此,最好在建表的时候,就要考虑到以后的分割点,比如预判到2014-01-01,2016-01-01。
分割现有的分区需要两个步骤:
- 首先要告诉SQL Server新建立的分区放到哪个文件组
- 建立新的分割点。
加一条数据,致使原表如下:
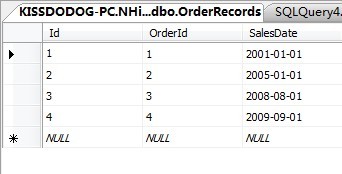
执行那个长查询,显示如下:
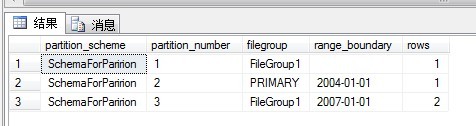
现在,可以执行分割操作了:
--分割出来的分区数据存在在哪个文件组 ALTER PARTITION SCHEME SchemaForParirion NEXT USED 'PRIMARY' --添加分割点 ALTER PARTITION FUNCTION fnPartition() SPLIT RANGE('2009-01-01')
执行完之后,再看结果如下:
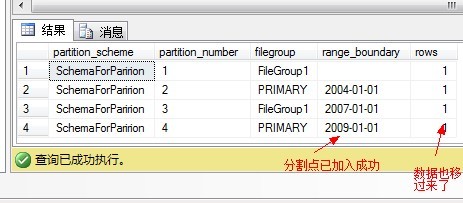
分区表的合并
分区的合并可以旱作是分区分割的逆操作。分区的合并需要提供分割点,并且这个分割点必须在现有的分割表中已经存在,否则进行合并时就会报错。
例如,对以上例子,根据2009-01-01来进行合并:
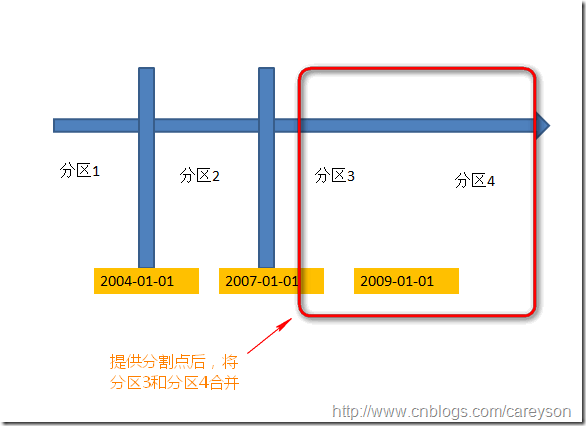
合并分区操作:
--提供分割点,合并分区 ALTER PARTITION FUNCTION fnPartition() MERGE RANGE('2009-01-01')
再来看分区信息:
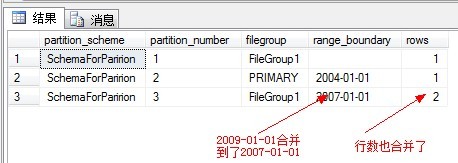
在这里应该注意到一个问题,假设已经合并了分区,那么合并之后,文件是存在分区3的文件组呢,还是分区4的文件组呢?这个取决于我们刚开始时定义的分区函数是left还是right。如果定义的是left,则左边的分区3合并到分区4。如果是right,则右边的分区4合并到分区3.
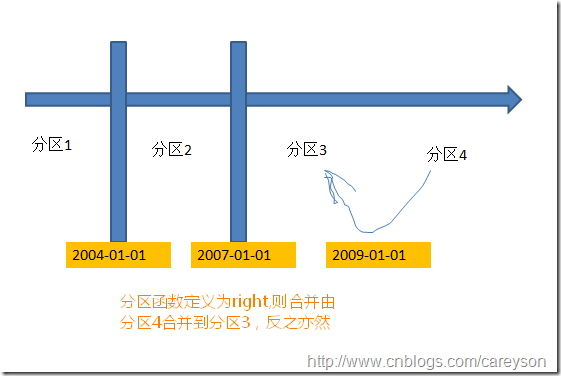
最后附上一句:CareySon大牛,我爱你。
本文学习自:http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html