Undo and redo
Oracle最重要的两部分数据,undo 与redo,redo(重做信息)是oracle在线(或归档)重做日志文件中记录的信息,可以利用redo重放事务信息,undo(撤销信息)是oracle在undo段中记录的信息,用于撤销或回滚事务。
1 redo
重做日志文件redo log,是数据库的事务日志,oracle维护着2类重做日志,在线重做日志文件和归档重做日志文件,归档日志文件就是重做日志的副本,系统将日志文件填满时arch进程会在另一个位置建立一个在线重做日志的副本
每个oracle数据库至少有2个重做日志组,以便切换日志,每个日志组至少有1个日志组成员,这些在线重做日志文件是以循环写的方式使用,
2 undo
你对数据库执行修改时,数据库会生成undo信息,以便回滚到更改前的状态,undo用于取消一条语句或一组语句的作用,undo在数据库内部存放在一组特殊的段中,
为undo段(回滚段 rollback segment),利用undo,数据库只是逻辑的恢复到原来的样子,所有修改都逻辑的取消,但是数据结构以及数据块本身在回滚后可能不大相同,
对于undo生成对于直接路径操作不适用,直接路径操作能够绕过表上的undo生成。
SQL> set autotrace traceonly statistics SQL> select * from t;--not first execute no rows selected Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 3 consistent gets 0 physical reads 0 redo size 995 bytes sent via SQL*Net to client 374 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed SQL> insert into t select * from all_objects; 49789 rows created. SQL> rollback; Rollback complete. SQL> select * from t; no rows selected Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 689 consistent gets -----I/O 0 physical reads 0 redo size 995 bytes sent via SQL*Net to client 374 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed
Insert导致一些块增加到表的高水位线(HWM),这些块没有因为回滚而消失,
select extent_id, bytes, blocks from user_extents
where segment_name = 'X' order by extent_id; 分配给表的存储空间—这个表没有使用任何区段
3 undo 跟redo如何协作
尽管undo信息存储在undo表空间或undo段中,但也会受到redo保护,会把undo信息当成表数据或索引数据一样,对undo的修改会生成一些redo,将记入重做日志,
将undo数据增加到undo段中,并像其他部分的数据一样,在缓冲区缓存中得到缓存
Insert-update-delete场景
3.1 insert
Insert语句,都会生成redo跟undo信息,插入发生后,如下图
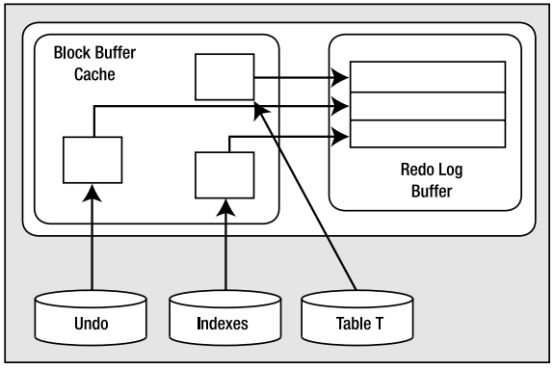
缓存了一下已修改的undo块,索引块和表数据块,这些块得到重做日志缓冲区相应条目的保护
1假象现在系统崩溃,sga全部被清空,但是我们不需要sga的中的任何内容,重启动时就好像这个事务就没发生过,没有将任何修改的块刷新输出到磁盘,
也没有任何redo信息刷新输出到磁盘,我们不需要这些undo或redo信息来实现实例失败恢复
2假象:缓冲区缓存已满
Dbwr进程要把已修改的块从缓存输出到磁盘,首先要求lgwr进程将保护这些数据库的redo条目输出到磁盘,dbwr在将任何修改的块输出到磁盘之前,都必须要求lgwr进程先刷新输出到redo日志,
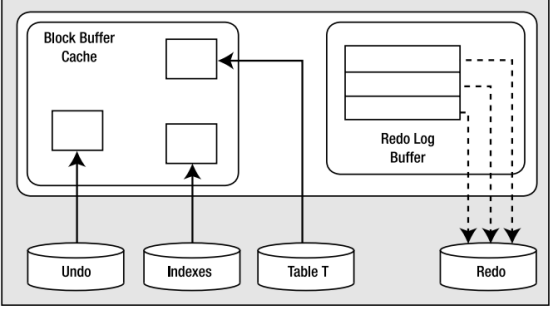
3.2 update
Update所带来的工作与insert大体一样,不过undo信息量更大,update,要保存系统的前映像,
缓冲区中会有更多的undo块,为了撤销update,如果必要,已修改的数据库表和索引都会存在缓存中,其中重做日志有的已经输出到磁盘,有的还在redo buffer 中
1 系统崩溃:启动时,oracle会读取重做日志,给定系统的当前状态,利用重做日志文件中对应的插入的redo条目,并利用仍在缓冲区中对应的redo条目,oracle会前滚插入,连接断开,oracle发现事务从未提交,因此将其回滚,利用undo,
2 应用回滚事务
Oracle发现这个事务的undo信息可能缓存在undo段中,也肯能已经刷新输出到磁盘,会把und信息应用到缓存中的数据和索引上,不在缓存中,则先要读入到缓存,恢复其原来的行,并刷新输出数据文件,
回滚过程不涉及重组日志,只有恢复和归档才会读取重做日志,重做日志是用来写的,不用于读,
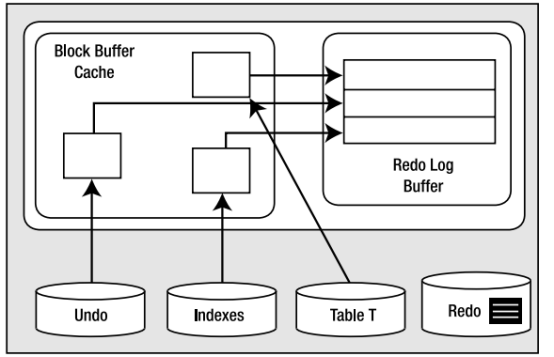
3 delete
Delete 会生成undo日志,块将被修改,并把redo日志发送到重做日志缓冲区,与update类似
4 commit
已经修改的块放在缓冲区缓存中,可能已经输出到磁盘,重做这个事务所需的全部redo都安全的存放在磁盘上,undo信息会一直存在,除非undo段回绕并重用了这些undo块,
4 提交和回滚处理
Commit:commit并没有做太多的工作,
Commit开销,频繁提交,会增加与数据库的往返同学,如果每个记录都提交,生成的往返通信量会大得多,每次提交时,必须等待redo写到磁盘,这会导致等待
在commit之前可能:
已经在sga中生成了undo 块,已经在sga中生成了已修改的数据块,已经在sga中生成了对应的2想的redo信息,取决于前3项的大小,已经这些花费的时间,前面的数据可能已经输出到磁盘,已经得到全部锁需要的锁
在实际commit时,
1为事务生成一个scn(系统改变号),scn用于保证事务的顺序,并支持失败恢复,scn还用于保证数据库中的读一致性和检查点,每次有人commit,scn都会增加1。
2 Lgwr进程会将重做日志缓冲区中的redo信息全部输出到磁盘,并把scn记录到redolog中,这一步已经真正提交,回车v$transaction中删除。
3 V$lock记录中我们会话持有的锁全部释放。4 如果事务修改的某些块还在缓冲区存在,则已一种快速的模式访问并清理,块清除。
Rollback 。撤销所有的修改,从undo中读取数据,逆向执行前面所做的事情,释放所持有的锁,
5 分析redo
Redo管理是数据库的一个串行点,任何oracle实例只有一个lgwr,
5.1 测量redo
SQL> set autotrace traceonly statistics; SQL> truncate table t; Table truncated. SQL> insert into t select * from all_objects; 49788 rows created. Statistics ---------------------------------------------------------- 6702 recursive calls 6822 db block gets 83402 consistent gets 2 physical reads 5625720 redo size 672 bytes sent via SQL*Net to client 575 bytes received via SQL*Net from client 4 SQL*Net roundtrips to/from client 14 sorts (memory) 0 sorts (disk) 49788 rows processed SQL> truncate table t; Table truncated.
对于noarchivelog模式的数据库进行直接路径加载,如果是archivelog模式,必须把表设置为nologging模式
SQL> insert /*+ APPEND */ into t select * from all_objects; 49788 rows created. Statistics ---------------------------------------------------------- 6244 recursive calls 1254 db block gets 82000 consistent gets 2 physical reads 57016 redo size 659 bytes sent via SQL*Net to client 589 bytes received via SQL*Net from client 4 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 49788 rows processed
5.2 能关掉重做日志程序吗
答案是不能的,重做日志是必不可少的,dba如果把db设置为force logging模式,在这种情况下,任何操作都会记录日志,
select force_logging from v$database
5.2.1 在sql中设置nologging
有些sql语句和操作支持使用nologging,有些特定的操作会比不使用nologging生成的redo要少的多,
在归档模式下,创建表使用nologging,看与不适用nologging的redo的比较
查看归档模式: cmd》archive log list
select log_mode from v$database
修改到归档模式:1 alter system set log_archive_dest_1=’location=f:
Mydbacrhive’;将归档日志放到指定的目录,默认在安装rdbms目录下
关闭 shutdown immediate
startup mount 模式
alter database archivelog
alter database open
归档未归档的文件 alter system archive log all
SQL> alter system set log_archive_dest_1='location=f:mydbarchivelog';
System altered.
创建一个函数,返回redo的大小
create or replace function get_stat_val( p_name in varchar2 ) return number as l_val number; begin select b.value into l_val from v$statname a, v$mystat b where a.statistic# = b.statistic# and a.name = p_name; return l_val; end;
create table t
NOLOGGING as select * from all_objects
Nologging注意:
1 还是会生成一定的redo,该redo主要是保护数据字典
2 此时nologging在建表时避免生成redo,但是在后续操作中insert update,delete都会生成redo
3 在archivelog模式的数据库中,使用了nologging之后,要赶快备份操作所创建的数据
5.2.2 在索引上使用nologging
在noarchivelog模式下,
create index test_y on test2(y) select get_stat_val('redo size') from dual
alter index test_y rebuild
select get_stat_val('redo size') from dual 与 alter index test_y nologging 之后,redo相差不多
在noarchivelog模式下,索引create个rebuild不会记录到redo中
在archivelog下才有区别
Nologging小结:采用nologging模式执行以下操作
1 索引的创建和alter(重建)
2 表的批量insert(用过append直接路径加载或sqlldr直接路径加载),表数据不生成redo,但是索引的所有修改会生成redo
3 lob操作(对大对象的操作不需要生成redo)
4 用过create as select 创建table
5 各种alter table 操作
6 临时表和redo/undo
临时表不会为他们的块生成redo信息,对临时表的操作是不可恢复的,修改临时表的一个块时不会将修改记录到重做日志中,不过临时表会生成undo,
临时表可以有约束,正常表有的临时表都可以有,
关于临时表的dml操作
Insert 不会生成undo
Update生成的undo比正常表少一半
Delete会生成一样的undo
另外考虑临时表上的索引,索引的修改也会生成undo
7 分析undo
7.1 什么操作会生成最多最少的undo
存在索引,对表的操作会生成更多的undo,insert最少,delete最多的undo,
大量更新前,索引删除后在重建
7.2 ora-1555 snapshot too old 快照太旧
1555错误与数据破坏跟数据丢失没有关系,唯一的影响是不能进行查询处理
导致1555的3个原因
1 undo段太小,不足以在系统下执行工作
2程序跨commit获取
3 块清除
由于数据库的读一致性,导致会从undo中读取信息,undo太小,被回绕利用,查询就不能继续,
解决办法:1 适当的设置undo_retention(要大于运行最长事务的所需的时间),可以用v$undostat undostat来确定长时间运行的查询的持续时间,另外保证磁盘上预留了足够的空间,使undo段能根据所需要的undo_retention字段增加
2使用手动管理undo段增加其大小,建议自动管理undo段
3减少查询的时间(调优),最好的办法
4 收集相关的统计信息,大批量的update跟insert会导致块清除,在大量更新后,收集表的统计信息
select * from v$undostat
1 undo段确实太小
create undo tablespace undo_small
datafile '/tmp/undo.dbf' size 2m autoextend off 创建一个小的undo空间
alter system set undo_tablespace = undo_small;
create table t as select * from all_objects order by dbms_random.random;
exec dbms_stats.gather_table_stats( user, 'T', cascade=> true );收集统计信息
进行一个大量的更新,同时在另一个会话查询,
把 回滚表空间设置为自动增长(相应的数据文件)
alter database datafile '/tmp/undo.dbf' autoextend on next 1m maxsize 2048m;
查看大小 select bytes/1024/1024 from dba_data_files where tablespace_name = 'UNDO_SMALL'
解决办法:1 保证事务大小适当,不要过于频繁的提交
2 使用dbms_stats扫描相关的对象
3 允许undo表空间自动扩大,
4 减少查询的时间(先尝试做)
Undo信息有专门的undo表空间(对于的数据文件),使用undo信息前必须在缓冲区中sga中,可能在磁盘的undo信息要读到缓冲区中使用,undo是可绕回使用,可自动扩展