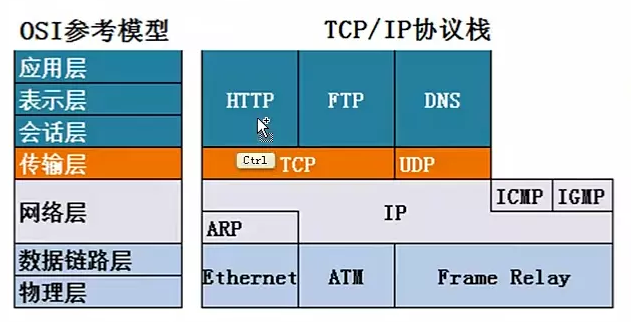
1. TCP/IP协议分层结构
应用层(含括了OSI七层中的上三层,分别为应用层,表示层, 会话层):DNS, URI, HTML, HTTP, TLS/SSL, SMTP, POP, IMAP, MIME, TELNET, SSH, FTP, SNMP, MIB, SIP, RTP, LDAP;
传输层: TCP , UDP, UDP_LITE, SCTP, DCCP;
网络层: ARP, IP, ICMP;
物理层(包含OSI七层模型的下两层,数据链路层及物理层): PPP(点到点)等
1. http请求到响应过程
A. 浏览器生成HTTP请求信息(第五层):
第一步:当用户输入网址并回车
第二步:浏览器分解URL(例如 http://www.test.com/p1.html http为请求协议, www.test.com为请求的域名即web服务器地址, p1.html为资源,当然在这里资源分为静态资源及动态请求)
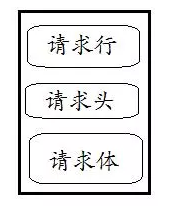
第三步:生成http请求消息
消息的格式为: <请求行 METHOD+path+协议及版本> + <请求头 User-Agent、Content-type等等> <请求体 post数据放在此>
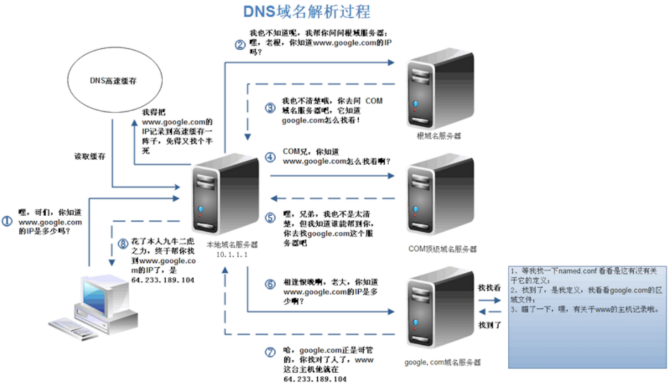
第四步:DNS解析(解析域名,得到WEB服务器IP地址) (DNS优化: 1.DNS缓存, 2.DNS负载均衡)
1)首先会搜索浏览器自身的DNS缓存,否则执行2);
2)则搜索操作系统的DNS缓存,否则执行3);
3)搜索hosts文件里面去找,否则执行4);
4)递归查找DNS服务器;(dns为树状结构,直到查找至最顶层)
B. TCP连接(三次握手):
第一步:建立socket
操作系统在接到请求后,首先会申请一块用于存放一个套接字所需的内存空间,套接字是存放了一些通信相关的控制信息的集合。然后向这个内存空间写入一些初始状态,并把该套接字的唯一标识告诉应用程序,即浏览器。
第二步:建立TCP连接:
这里参照这篇博文
第四步:发送HTTP请求:
操作系统收到数据后会将数据存放在的发送数据缓存区中,并等待接收后续数据,只有当接收的数据达到一个网络包的大小的时候,或者达到最大等待时间之后,才会委托ip模块发送出去。浏览器数据量小、对性能要求高,一般会设置为直接发送。一般的http请求数据用一个网络包就够了,但有时提交的表单数据较大时,会拆分成多个网络包发送
C. 网络层处理:
当上层(传输层)HTTP请求数据到达之后,该层做进一步的数据包封装, 主要包括源地址及目的地址,当然这里的地址包括IP及MAC地址, 其中目的IP地址就是应用层中DNS解析的IP地址, 而MAC地址则需要通过ARP协议进行广播查询
D. 物理层将数据包以数字信号进行发送,在此之前还需要添加一些CRC校验字段等等来确保数据未发生丢失
E. 服务器响应HTTP请求, 浏览器得到资源文件
HTTP响应同样由响应行、响应头、响应体组成
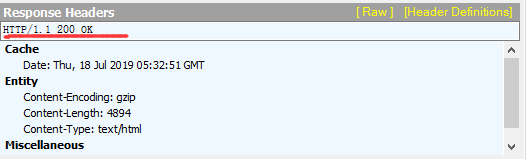
常见的响应状态码类别有:
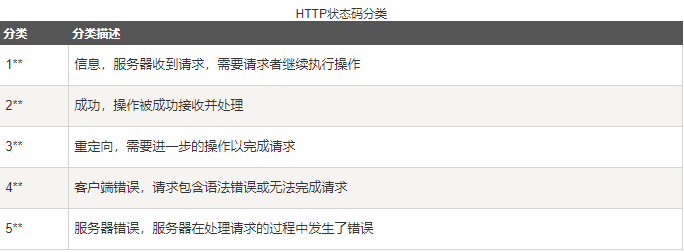
F. 浏览器解析HTML代码, 同时请求相关静态资源
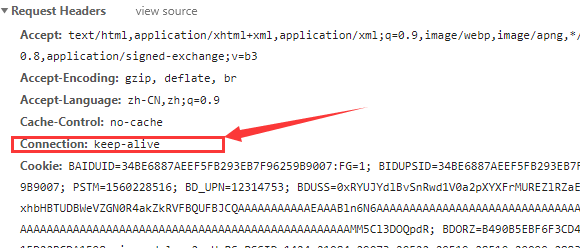
浏览器(应用层)在得到HTML文件之后, 会按照<!DOCTYPE XXXX>规定的格式进行解析, 如果碰到链接的静态文件资源时, 浏览器便会另开多个线程去请求下载, 这是便会使用到HTTP协议的keep-alive特性了, 建立了一次HTTP连接,但是能够请求多个静态资源。
G. 生成DOM并渲染, 边解析边渲染
浏览器是一个边解析边渲染的过程。首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
自此便完成了一次HTTP请求及响应