【Java拾遗】不可不知的 Java 序列化

前言
在程序运行的生命周期中,序列化与反序列化的操作,几乎无时无刻不在发生着。对于任何一门语言来说,不管它是编译型还是解释型,只要它需要通讯或者持久化时,就必然涉及到序列化与反序列化操作。但是,又正因为序列化与反序列化太过重要,太过普遍,大部分编程语言和框架都对其进行了很好的封装,又因为他的润物细无声,使得我们很多时候根本没有意识到,代码下面其实进行了许许多多序列化相关的操作。今天我们就一起去探寻这位最熟悉的陌生人。
序列化是什么
百度百科中给序列化的定义是『序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。』。似乎有点抽象,下面用一个例子简单类比一下。
日常生活中,总少不了人跟人之间的交流与沟通。而沟通的前提是先要把我们大脑中想的内容,通过某种形式表达出来。然后别人再通过我们表达出的内容去理解。
而表达的方式多种多样,最常见的就是说话,我们通过说一些话,把我们脑海里想的内容表达出来,对方听了这些话立刻明白了我们的想法。当然表达也可以是文字,比如你正在看的本文,不也是在与你交流吗?导演通过电影去表达自己对于世界的理解,画家通过画作述说的对美的渴望,音乐家通过乐符描述着对自由的向往。凡此种种,不胜枚举。
所以,这些又跟我们的主题 序列化 有什么关系呢?
其实人与人之间少不了沟通交流,程序与程序之间,机器与机器之间也少不了沟通交流。只不过通常不会说是沟通,我们会说请求、响应、传输、通讯…… 同样的内容只是换了一种说法。
上文中提到,人与人之间的沟通需要一种表达方式。通过这种表达方式把我们大脑中所想的内容,转化成他人可以理解的内容。而机器与机器之间的通讯也需要这样一种表达方式,通过这种表达方式把内存中的内容,转化成其它机器可以读取的内容。
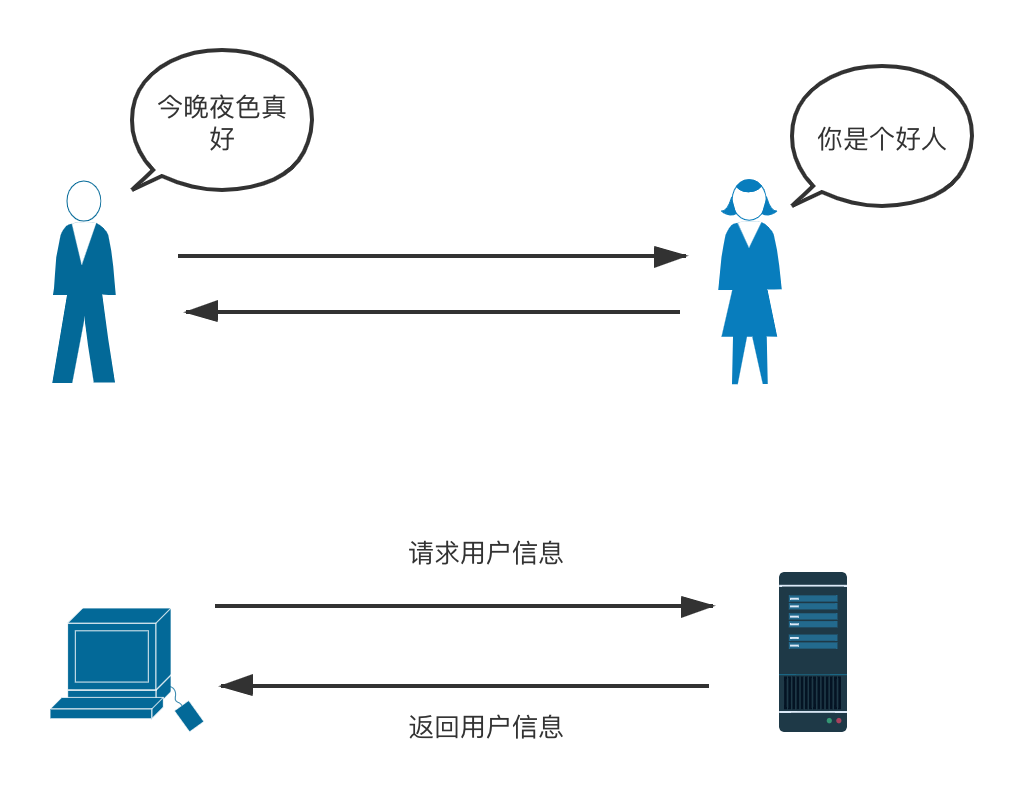
所以序列化可以简单的理解成是 机器内存中信息的表达方式 。
为什么需要序列化
通常情况下,我们的语言一方面用于交流,比如聊天,把我脑海中的思想,通过语言表达出来,对方听到我们的话语,会意我们的想法。
另一方面,我们的语言除了用于沟通交流,还可以用于记录。有一句话叫做『好记性不如烂笔头』。说的就是记录的重要性,因为话在我们的脑子里,很容易就忘了,通过记录下来可以保存更久。
而序列化功能又正好对应这两点,一个是用来传输信息,另一个是用来持久化。序列化用来传输的作用,前文已经说过了,关于持久化的作用,也很好理解。首先明确一个问题,序列化的是什么内容?通常是内存中的内容。而内存有一个特点我们都知道,那就是一重启就没了。对于部分内容,我们想在重启后还存在(比如说 tomcat 中 session 里面的对象),要怎么办呢?答案就是把内存中的对象保存到磁盘上,这样就不怕重启了,而持久化就需要用到序列化技术。
如何实现序列化
人与人之间有许许多多的表达方式,而且机器与机器之间也同样,序列化的方式多种多样。
Java 原生形式
对于如此普遍的序列化需求,Java 其实早在 JDK 1.1 开始就在语言层面进行了支持。而且使用起来非常方便,下面我们就一起看看具体代码。
- 首先我们要把想序列化的类实现 Java 自带的
java.io.Serializable接口
/*
*
* * *
* * * blog.coder4j.cn
* * * Copyright (C) 2016-2020 All Rights Reserved.
* *
*
*/
package cn.coder4j.study.example.serialization;
import java.io.Serializable;
import java.util.StringJoiner;
/**
* @author buhao
* @version HaveSerialization.java, v 0.1 2020-09-17 16:58 buhao
*/
public class HaveSerialization implements Serializable {
private static final long serialVersionUID = -4504407589319471384L;
private String name;
private Integer age;
/**
* Getter method for property <tt>name</tt>.
*
* @return property value of name
*/
public String getName() {
return name;
}
/**
* Setter method for property <tt>name</tt>.
*
* @param name value to be assigned to property name
*/
public void setName(String name) {
this.name = name;
}
/**
* Getter method for property <tt>age</tt>.
*
* @return property value of age
*/
public Integer getAge() {
return age;
}
/**
* Setter method for property <tt>age</tt>.
*
* @param age value to be assigned to property age
*/
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return new StringJoiner(", ", HaveSerialization.class.getSimpleName() + "[", "]")
.add("name='" + name + "'")
.add("age=" + age)
.toString();
}
}
需要注意的是,虽说是实现了 java.io.Serializable 接口,但是我们其实没有覆盖任何方法。这是为什么呢?我们一起看一下 java.io.Serializable 的源码。
public interface Serializable {
}
没错,是个空接口,除了接口定义部分,啥也没有。通常遇到这种情况,我们称之为标记接口,主要为了标记某些类,标记的原因是,把它与其它类区别出来,方便我们后面专门处理。而 Serializable 这个标记接口,就是为了让我们知道这个类是要进行序列化操作的类,仅此而已。
另外,虽然我们只实现一个空接口,但是细心的你,肯定发现了我们的类中多了一个 serialVersionUID 属性。那么这个属性的作用是什么呢?
它主要目的就是为了验证序列化与反序列化的类是否一致。比如上面 HaveSerialization 这个类现在有业务属性 name 与 age ,现在因为业务需要,我们要添加一个 address 的属性。序列化操作是没有问题的,但是把序列化信息传输给其它机器,其它机器在反序列化的时候,就出现了问题。因为其它机器的 HaveSerialization 没有 address 这个属性。
为了解决这个问题,JDK 通过使用 serialVersionUID 在作为该类的版本号,在反序列化时比较传输的类的值与要反序列化类的值是否一致,不一致就会报 InvalidCastException 。
当然,出发点是好的,但是直接抛异常会导致业务无法进行下去,通常 serialVersionUID 生成好后,我们不会再更新,序列化如果没有更新,对应变更的属性会为空,我们只要在业务里做好兼容就好了。
- 序列化对象
好了,我们已经完成了第一步,定义了一个序列化类,下面我们就把他给序列化掉。
/**
* 序列化对象(保存序列化文件)
* @throws IOException
*/
@Test
public void testSaveSerializationObject() throws IOException {
// 创建对象
final HaveSerialization haveSerialization = new HaveSerialization();
haveSerialization.setName("kiwi");
haveSerialization.setAge(18);
// 创建序列化对象保存的文件
final File file = new File("haveSerialization.ser");
// 创建对象输出流
try (final ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(file))) {
// 将对象输出到序列化文件
objectOutputStream.writeObject(haveSerialization);
}
}
可以看到代码十分简单,大体分成如下 4 步:
- 创建要序列化的对象
其实就是你上面的实现java.io.Serializable的类,如果没有实现,在这里会报NotSerializableException异常 - 创建一个
File对象,用来保存序列化后的二进制数据。
注意这里文件名我用的是*.ser,这个 ser 后缀并没有强制要求,只是方便理解,你可能写成其它后缀 - 创建对象输出流
创建一个ObjectOutputStream对象输出流的对象,并把上面定义的序列化文件对象通过构造函数传给它。 - 通过输出流把对象写到序列化文件里
注意这里我用的 JDK 8 的try with resource语法,所以不用手动close
好了,到这里我们序列化也完成了。
- 反序列化对象
既然有序列化,那肯定也有反序列化。反序列化可以理解成是序列化的逆向操作,既然序列化把内存中的对象转成一个可以持久化的文件,那么反序列化要做的就是把这个文件再加载到内存中的对象。话不多说,直接看代码。
/**
* 反序列化对象(从序列化文件中读取对象)
* @throws IOException
* @throws ClassNotFoundException
*/
@Test
public void testLoadSerializationObject() throws IOException, ClassNotFoundException {
// 创建对象输出流
try (ObjectInputStream objectInputStream = new ObjectInputStream(
new FileInputStream(new File("haveSerialization.ser")))) {
// 从输出流中创建对象
final Object obj = objectInputStream.readObject();
System.out.println(obj);
}
}
是的,反序列化代码比序列化代码还少,主要分成如下 2 步:
- 创建对象输入流
创建一个ObjectInputStream对象,并把序列化文件通过构造函数传给它 - 从对象输入流中读取对象
直接通过readObject方法即可,注意读取后是Object类型,后续使用需手动强转一次
到这里,我们便通过 JDK 原生的方法完成了序列化与反序列化操作,是不是还很简单。但是日常工作不太推荐直接使用原生的方式实现序列化,一方面它生成的序列化文件较大,一方面也比一些第三方框架生成的慢,但是序列化原理大致类似。下面我们简单看一下其它方式如何序列化。
通用对象序列化
通常序列化是与语言绑定的,比如说通过上面 JDK 序列化的文件,不可能拿给 PHP 应用反序列化成 PHP 的对象。不过可以通过某些特殊的通用对象结构序列化来实现跨语言使用,比较常见的是 JSON 、XML 。下面我们以 JSON 为例看一下
/**
* 测试序列化通过json
*/
@Test
public void testSerializationByJSON(){
//-------------序列化操作---------------
// 创建对象
final HaveSerialization haveSerialization = new HaveSerialization();
haveSerialization.setName("kiwi");
haveSerialization.setAge(18);
// 序列化成 JSON 字符串
final String jsonString = JSON.toJSONString(haveSerialization);
System.out.println("JSON:" + jsonString);
//-------------反序列化操作---------------
final HaveSerialization haveSerializationByJSON = JSON.parseObject(jsonString, HaveSerialization.class);
System.out.println(haveSerializationByJSON);
}
运行结果:
JSON:{"age":18,"name":"kiwi"}
HaveSerialization[name='kiwi', age=18]
上述代码使用的 JSON 框架是 alibaba/fastjson 。但是大部分 JSON 框架使用起来都大同小异。可以按个人喜好去替换。
序列化框架
序列化框架其实有很多,比如 kryo 、 hessian 、 protostuff 。它们各有优缺点,详细的比较可以看这篇文章 序列化框架 kryo VS hessian VS Protostuff VS java 。大家可以按各自的使用场景选择使用,下文以 kryo 为例演示。
- 依赖
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.0.0-RC9</version>
</dependency>
- 具体代码
/**
* 测试序列化通过kryo
*/
@Test
public void testSerializationByKryo() throws FileNotFoundException {
//-------------序列化操作---------------
// 创建对象
final HaveSerialization haveSerialization = new HaveSerialization();
haveSerialization.setName("kiwi");
haveSerialization.setAge(18);
final Kryo kryo = new Kryo();
// 注册序列化类
kryo.register(HaveSerialization.class);
// 序列化操作
try (final Output output = new Output(new FileOutputStream("haveSerialization.kryo"))) {
kryo.writeObject(output, haveSerialization);
}
// 反序列化
try (final Input input = new Input(new FileInputStream("haveSerialization.kryo"))) {
final HaveSerialization haveSerializationByKryo = kryo.readObject(input, HaveSerialization.class);
System.out.println(haveSerializationByKryo);
}
}
其实看代码可以发现跟 JDK 的流程几乎一样,其中有几点需要注意的,kryo 在序列化前,要手动通过 register 注册序列化的类,有点类似 JDK 实现 java.io.Serializable 接口。然后 Input 、 Output 对象不是 JDK 的。是 kryo 提供的。另外 Kryo 有不少需要注意的地方,可以查看参考链接部分的内容学习。
源码地址
因文章篇幅有限,无法展示所有代码,已经另外把完整代码上传到 github,具体链接如下:
https://github.com/kiwiflydream/study-example/tree/master/study-serialization-example
参考链接
- 序列化框架 kryo VS hessian VS Protostuff VS java - 知其然,知其所以然 - ITeye博客
- Kryo 使用指南 - hntyzgn - 博客园
- 深入理解 RPC 之序列化篇 --Kryo | 徐靖峰|个人博客
- EsotericSoftware/kryo: Java binary serialization and cloning: fast, efficient, automatic
总结
本文主要介绍了 Java 序列化的相关内容,主要介绍序列化是什么?与人与人之间沟通的表达方式做类比,得到是 机器内存中信息的表达方式 。而为什么需要序列化,我们通过举例说明了序列化 信息传输与持久化 的功能。最后我们一起从 JDK 原生的实现 java.io.Serializable 的方式,再到通用对象序列化的 JSON、XML 方式,最终到第三方框架 kryo 的形式了解如何去实现序列化。