铭文一级:
整合Flume和Kafka的综合使用
avro-memory-kafka.conf
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop000
avro-memory-kafka.sources.avro-source.port = 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
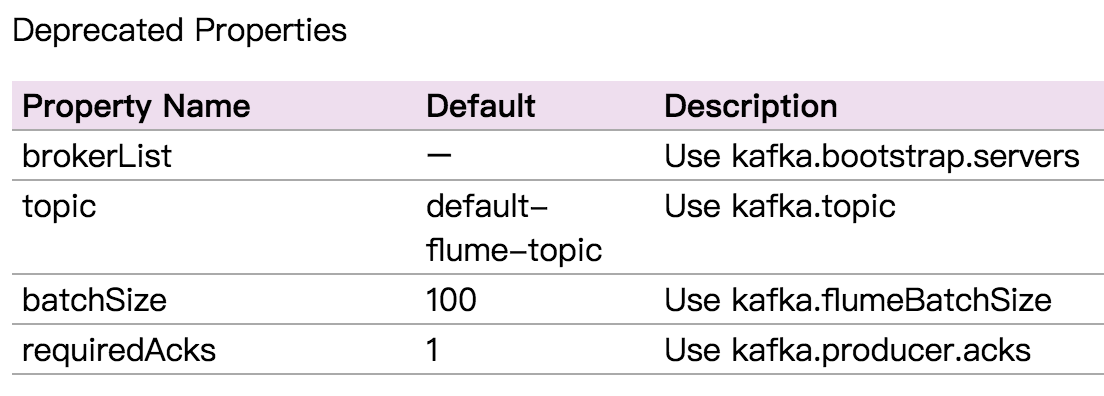
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
avro-memory-kafka.sinks.kafka-sink.topic = hello_topic
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks =1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
flume-ng agent
--name avro-memory-kafka
--conf $FLUME_HOME/conf
--conf-file $FLUME_HOME/conf/avro-memory-kafka.conf
-Dflume.root.logger=INFO,console
flume-ng agent
--name exec-memory-avro
--conf $FLUME_HOME/conf
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf
-Dflume.root.logger=INFO,console
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic
铭文二级:
Kafka Producer java API编程:
建KafkaProperties类=>
申明三个静态属性:
public static final String
1.BROKER_LIST="192.168.0.115:9092" //IP地址修改成自己的地址
2.ZK="192.168.0.115:2181" //IP地址修改成自己的地址
3.TOPIC="hello_topic"
建KafkaProducer类=>
创建构造方法实现123小点,参数为topic:(构造方法为私有还是公有?公有)
1.申明Producer类(导入类为kafka.javaapi.Producer),查看返回值与参数值
2.参数值new ProducerConfig(),里面参数为properties(在构造方法中new出来)
3.properties需要put三个属性:
A.metadata.broker.list //类静态方法获得
B.serializer.class //kafka.serializer.StringEncoder
C.request.required.acks //值说明如下:
0:不等待任何握手机制;
1:写到本地log并返回ack,常用,但可能有一丁点数据丢失
-1:严格握手,只要有副本存活就没有数据丢失
4.使类继承Thread类,因为使用线程测试
public void run(){
int messageNo = 1;
while(true){
String message = "message_" + messageNo;
producer.send(new KeyedMessage<Integer,String>(topic,message));
system.out.println("Send:" + message);
messageNo++;
}
try{
Thread.sleep(2000);
}catch(Exception e){
e.printStackTrace();
}
}
建KafkaClientApp测试类:
1.申明main方法
2.new KafkaProducer(KafkaProperties.TOPIC).start();
3.jps查询是否已启动zookeeper、kafka、consumer,必须先启动
4.运行main方法可观察到控制台与consumer终端有内容输出
Kafka Consumer java API编程:
创建KafkaConsumer类=>
申明参数为topic的构造方法
private ConsumerConnector createConnector(){
Properties properties = new Properties();
properties.put("zookeeper.connect", KafkaProperties.ZK);
properties.put("group.id",KafkaProperties.GROUP_ID);
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
public void run() {
ConsumerConnector consumer = createConnector();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1);
// topicCountMap.put(topic2, 1);
// topicCountMap.put(topic3, 1);
// String: topic
// List<KafkaStream<byte[], byte[]>> 对应的数据流
Map<String, List<KafkaStream<byte[], byte[]>>> messageStream = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = messageStream.get(topic).get(0); //获取我们每次接收到的数据
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while (iterator.hasNext()) {
String message = new String(iterator.next().message());
System.out.println("rec: " + message);
}
}
代码分析:
1.获取Consumer,根据分装过的topicCountMap生成信息流messageStream
topicCountMap.put(topic,1);//参数“1” 指生成一个信息流
2.此时messageStream里面还有topic,需要去除topic,返回stream
3.将stream进行迭代,返回iterator
4.通过while(iterator.hasNext())与iterator.next().message()生成message并返回
ps:KafkaProperties类勿忘需要加一个属性GROUP_ID并添加到properties,自起一个id即可
示例:
public static final String GROUP_ID = "test_group1";
properties.put("group.id",KafkaProperties.GROUP_ID);
Kafka实战=>
整合Flume和kafka完成实时数据采集
修改avro-memory-logger.conf//将sink改成kafka,详情可看CDH5里面的文档,官网新版有些小改动
type:org.apache.flume.sink.kafka.KafkaSink
brokerList:hadoop000:9092
非必须:
topic //自己尝试不设置是否可以,默认是调用含有topic参数的topic
batchSize:5
requiredAcks:1
分别开始,然后测试。
ps:上面属性名已经不推荐,最新官网为,可能跟版本有关,自行测试: