Union因为要进行重复值扫描,所以效率低。如果合并没有刻意要删除重复行,那么就使用Union All
两个要联合的SQL语句 字段个数必须一样,而且字段类型要“相容”(一致);
如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。
union和union all的区别是,union会自动压缩多个结果集合中的重复结果,而union all则将所有的结果全部显示出来,不管是不是重复。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
Intersect:对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;
Minus:对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。
可以在最后一个结果集中指定Order by子句改变排序方式。
例如:
select employee_id,job_id from employees
union
select employee_id,job_id from job_history
以上将两个表的结果联合在一起。这两个例子会将两个select语句的结果中的重复值进行压缩,也就是结果的数据并不是两条结果的条数的和。如果希望即使重复的结果显示出来可以使用union all,例如:
2.在oracle的scott用户中有表emp
select * from emp where deptno >= 20
union all
select * from emp where deptno <= 30
这里的结果就有很多重复值了。
有关union和union all关键字需要注意的问题是:
union 和 union all都可以将多个结果集合并,而不仅仅是两个,你可以将多个结果集串起来。
使用union和union all必须保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。但列名则不一定需要相同,oracle会将第一个结果的列名作为结果集的列名。例如下面是一个例子:
select empno,ename from emp
union
select deptno,dname from dept
我们没有必要在每一个select结果集中使用order by子句来进行排序,我们可以在最后使用一条order by来对整个结果进行排序。例如:
select empno,ename from emp
union
select deptno,dname from dept
order by ename;
------------------------------------------------------------
UNION 并集,表中的所有数据,并且去除重复数据(工作中主要用到的是这个);
UNION ALL,表中的数据都罗列出来;
那么交集怎么取呢,怎么取得几张表中的重叠的部分呢?(文末提供了一种方法)
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。需要满足以下条件:
1、相同数量的列;
2、列也必须拥有相似的数据类型;
3、同时,每条 SELECT 语句中的列的顺序必须相同。
这三点一定要牢记,下面用一个小例子来说明。
建了两张表,一张选功夫课程的学生表,一张是选音乐课程的学生表。里面的主要数据如下
我们先用UNION连接一下,查看下查询结果。
仔细看一下,不是说UNION是并集且去掉重复的数据吗。为什么还会有两个令狐冲?
这样来看为什么只有一个令狐冲呢,再对比一下脚本,原来是第一个脚本的字段比第二个脚本的查询到的字段比较多。观察第一个脚本的查询结果并没有四列全部重复的数据,所以查询时要尽量明确自己的目的。如果是查询学习课程的同学有哪些,第二个脚本的查询结果就是。而第一个脚本就是查询了哪些同学选了哪些课程,并且任课老师的信息全部列出来了。
接下来来看交集怎么取,查询目的,有哪些同学既学习了武功还学习了音乐。
union在数据库运算中会过滤掉重复数据,并且合并之后的是根据行合并的,即:如果a表和b表中的数据各有五行,且有两行是重复数据,合并之后为8行。运用场景:适合于需要进行统计的运算
union all是进行全部合并运算的,即:如果a表和b表中的数据各有五行,且有两行是重复数据,合并之后为10行。
join是进行表关联运算的,两个表要有一定的关系。即:如果a表和b表中的数据各有五行,且有两行是重复数据,根据某一列值进行笛卡尔运算和条件过滤,假如a表有2列,b表有2列,join之后是4列。
对于无关的运算,一般适合于full join,这样在图表展示的时候可以进行很好的处理,每个元素都可以展示的很好。
union在进行表求并集后会去掉重复的元素,所以会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
union all则只是简单地将两个结果集合并后就返回结果。因此,如果返回的两个结果集中有重复的数据,那么返回的结果就会包含重复的数据。
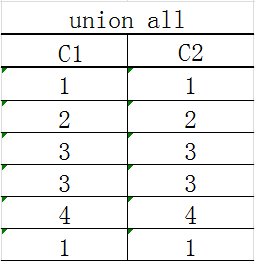
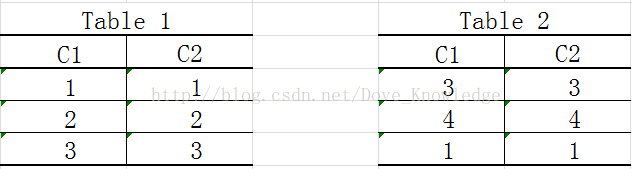
从上面的对比可以看出,在执行查询操作时,union all要比union快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据,那么最好使用union all。例如,现有两个学生表Table1和Table2:
执行语句:
select * from Table1 union select * from Table2
查询结果如下:
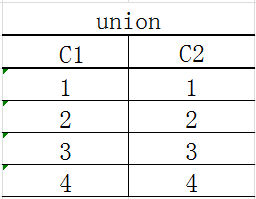
执行语句:
select * from Table1 union all select * from Table2
查询结果如下: