| 名称 | 说明 |
|---|---|
| ASCII | 只能存英文和拉丁字符,一个字符占一个字节,8位。 ASCII 码是不支持中文的,支持中文的第一张表是 GB2312 |
| GB2312 | 支持中文,收录了 7445个字符 |
| GBK1.0 | 支持中文,收录了 21886个字符 |
| GB18030 | 收录了 27484个汉字,及藏文,维吾尔文等少数名族文字 |
| unicode | 万国码,支持所有国家和地区的编码,向下兼容 gb2312, gbk |
| UTF-32 | 一个字符占用4个字节 |
| UTF-16 | 一个字符占2个字节或2个以上 |
| UTF-8 | unicode 的扩展集,可变长的字符编码集 (一个英文用 ASCII 来存储,一个中文占3个字节) |
可以简单的理解为:
1.为了处理英文字符,产生了ASCII码。
2.为了处理中文字符,产生了GB2312。
3.为了处理各国字符,产生了Unicode。
4.为了提高Unicode存储和传输性能,产生了UTF-8,它是Unicode的一种实现形式。
注意:
Python2.x 默认编码是 ASCII
Python3.x 默认编码是 unicode,所以 Python3.x 直接支持中文不需要进行二次处理。
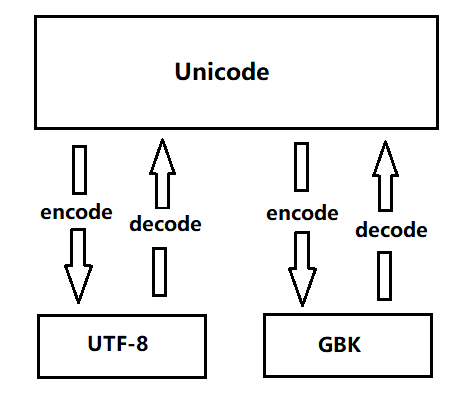
GBK转换成 UTF-8 的流程:
1.通过解码 (decode) 转换成 Unicode
2.通过编码 (encode) 转成成 GBK
乱码是因为系统编码与所提供字符的编码不一致所导致的。所以当我们需要操作系统正确的输出一个字符时,除了要知道该字符的字符编码,也要知道自己系统所使用的字符编码。
Linux 系统大部分使用的是 UTF-8 编码,Windoors 系统使用的编码是 GB2312。
可以通过 chardet 来判断字符的编码
安装步骤:
1. 下载 chardet-3.0.4.tar.gz
地址:https://pypi.python.org/pypi/chardet/3.0.4#downloads
2. 解压至安装目录
我的电脑为 D:softwarePython2.7Libsite-packageschardet-3.0.4
3. 打开 Windows 命令行窗口进行安装
进入源码目录

使用 python setup.py install 安装
测试
# -*- encoding:utf-8 -*-
import chardet
name = '你好'
print(chardet.detect(name))
运行结果:

在py2中
#-*- coding: UTF-8 -*-
声明这句话就是告诉 python2.7 解释器 (默认ACSII编码方式)解释的 .py 文件声明下面的内容按 utf8 编码,就是编码(编码成字节串最后转成0101的形式让机器去执行)