对于一个没有字段名标题的数据,如data.csv

1.获取数据内容。pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv")
print(df)
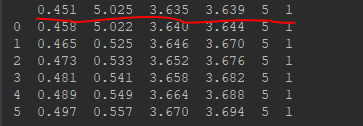
为了解决这个问题,我们添加“header=None”,告诉函数,我们读取的原始文件数据没有列索引。因此,read_csv为自动加上列索引。
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv", header=None)
print(df)
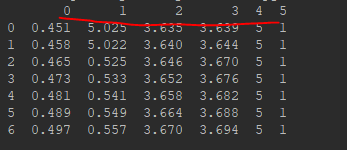
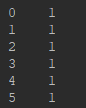
2.局部获取。有时候我们需要取某些列数据,如下(X,y):

- pd.read_csv()函数有"header=None"参数:
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv", header=None)
# 注意有"header=None", df.ix[:,0:4]就是左闭右闭的区间
X= df.ix[:,0:4]
y = df.ix[:,5]
print(X)
print(y)

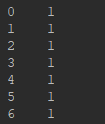
- pd.read_csv()函数没有"header=None"参数:
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv")
# 注意没有"header=None", df.ix[:,0:4]就是左闭右开的区间
X= df.ix[:,0:4] # 实际上X应该是df.ix[:,0:5]
y = df.ix[:,5]
print(X)
print(y)
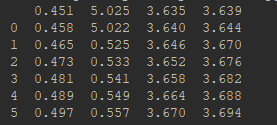
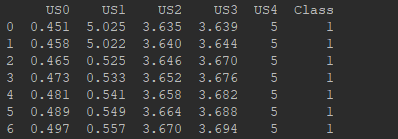
在第二种情况中,带上names属性还是df.ix[:,0:4]就是左闭右开的区间。
# 设置表头
names = ["US0","US1","US2","US3","US4","Class"]
# 读入数据 (没有属性行:header=None)
df = pd.read_csv("../data/data.csv", names=names)
# 注意没有"header=None", df.ix[:,0:4]就是左闭右开的区间
X= df.ix[:,0:4] # 实际上X应该是df.ix[:,0:5]
y = df.ix[:,5]
print(df)
print(X)
print(y)
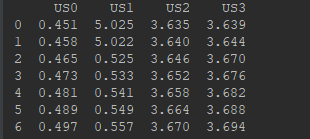
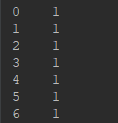
总结:pd.read_csv()函数,有"header=None", df.ix[:,0:4]就是左闭右闭的区间;没有"header=None", df.ix[:,0:4]就是左闭右开的区间。